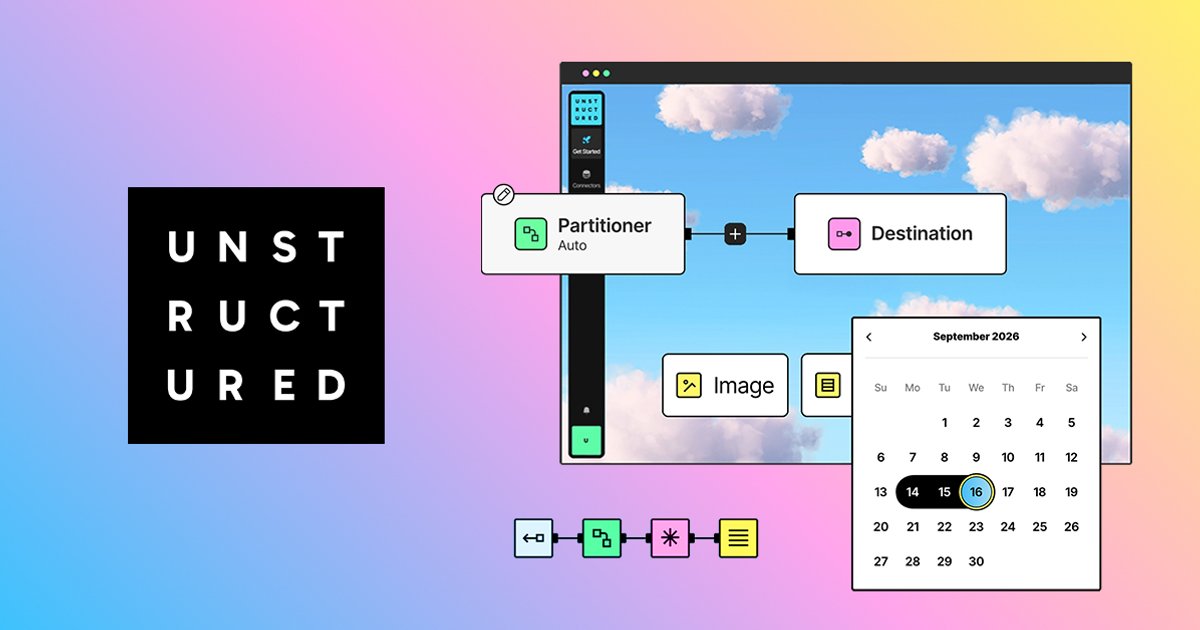
Transform complex, unstructured data into clean, AI-ready inputs. Connect to any source, process 64+ file types, and power your GenAI projects. Start
Users appreciate "Unstructured" for its effective handling of unstructured data and ease of integration with existing workflows, making it an appealing choice for those working with complex datasets. However, some users express concerns about its occasional inefficiency with large-scale data and the need for more detailed user support. The pricing is seen as reasonable by most, although a few users suggest it could be more competitive. Overall, "Unstructured" has a positive reputation, especially in data-heavy fields, due to its robust features and user-friendly interface.
Mentions (30d)
7
1 this week
Reviews
0
Platforms
4
GitHub Stars
14,357
1,208 forks






Users appreciate "Unstructured" for its effective handling of unstructured data and ease of integration with existing workflows, making it an appealing choice for those working with complex datasets. However, some users express concerns about its occasional inefficiency with large-scale data and the need for more detailed user support. The pricing is seen as reasonable by most, although a few users suggest it could be more competitive. Overall, "Unstructured" has a positive reputation, especially in data-heavy fields, due to its robust features and user-friendly interface.
Features
Use Cases
Industry
information technology & services
Employees
120
Funding Stage
Series B
Total Funding
$65.0M
1,451
GitHub followers
41
GitHub repos
14,357
GitHub stars
20
npm packages
12
HuggingFace models
Launch HN: Captain (YC W26) – Automated RAG for Files
Hi HN, we’re Lewis and Edgar, building Captain to simplify unstructured data search (<a href="https://runcaptain.com">https://runcaptain.com</a>). Captain automates the building and maintenance of file-based RAG pipelines. It indexes cloud storage like S3 and GCS, plus SaaS sources like Google Drive. There’s a quick walkthrough at <a href="https://youtu.be/EIQkwAsIPmc" rel="nofollow">https://youtu.be/EIQkwAsIPmc</a>.<p>We also put up this demo site called “Ask PG’s Essays” which lets you ask/search the corpus of pg’s essays, to get a feel for how it works: <a href="https://pg.runcaptain.com">https://pg.runcaptain.com</a>. The RAG part of this took Captain about 3 minutes to set up.<p>Here are some sample prompts to get a feel for the experience:<p>“When do we do things that don't scale? When should we be more cautious?” <a href="https://pg.runcaptain.com/?q=When%20do%20we%20do%20things%20that%20don't%20scale%3F%20When%20should%20we%20be%20more%20cautious%3F">https://pg.runcaptain.com/?q=When%20do%20we%20do%20things%20...</a><p>“Give me some advice, I'm fundraising” <a href="https://pg.runcaptain.com/?q=Give%20me%20some%20advice%2C%20I'm%20fundraising">https://pg.runcaptain.com/?q=Give%20me%20some%20advice%2C%20...</a><p>“What are the biggest advantages of Lisp” <a href="https://pg.runcaptain.com/?q=what%20are%20the%20biggest%20advantages%20of%20Lisp">https://pg.runcaptain.com/?q=what%20are%20the%20biggest%20ad...</a><p>A good production RAG pipeline takes substantial effort to build, especially for file workloads. You have to handle ETL or text extraction, chunking, embedding, storage, search, re-ranking, inference, and often compliance and observability – all while optimizing for latency and reliability. It’s a lot to manage. grep works well in some cases, but for agents, semantic search provides significantly higher performance. Cursor uses both and reports 6.5%–23.5% accuracy gains from vector search over grep (<a href="https://cursor.com/blog/semsearch" rel="nofollow">https://cursor.com/blog/semsearch</a>).<p>We’ve spent the past four years scaling RAG pipelines for companies, and Edgar’s work at Purdue’s NLP lab directly informed our chunking techniques. In conversations with dozens of engineers, we repeatedly saw DIY pipelines produce inconsistent results, even after weeks of tuning. Many teams lacked clarity on which retrieval strategies best fit their data.<p>We realized that a system to provision storage and embeddings, handle indexing, and continuously update pipelines to reflect the latest search techniques could remove the need for every team to rebuild RAG themselves. That idea became Captain.<p>In practice, one API call indexes URLs, cloud storage buckets, directories, or individual files. Under the hood, we’re converting everything to Markdown. For this, we’ve had good results with Gemini 3 Pro for images, Reducto for complex documents, and Extend for basic OCR. For embedding models, ‘gemini-embedding-001’ performed reasonably well at first, but we later switched to the Contextualized Embeddings from ‘voyage-context-3’. It produced more relevant results than even the newer Voyage 4 models because its chunk embeddings are encoded with awareness of the surrounding document context. We then applied Voyage’s ‘rerank-2.5’ as second-stage re-ranking, reducing 50 initial chunks to a final top 15 (configurable in Captain’s API). Dense embeddings are just half the picture and full-text search with RRF complete our hybrid retrieval. In the Captain API, these techniques are exposed through a single /query endpoint. Access controls can be configured via metadata filters, and page number citations are returned automatically.<p>The stack is constantly changing but the Captain API creates a standard interface for this. You can try Captain, 1 month for free, and build your own pipelines at <a href="https://runcaptain.com">https://runcaptain.com</a>. We’re looking for candid feedback, especially anything that can make it more useful, and look forward to your comments!
View originalPricing found: $0.03 / page
[Open Source] I built a full Git MCP server in Go that doesn't just wrap bash. It uses tree-sitter, handles real plumbing (write-tree), and runs 100% locally.
I was tired of watching LLM agents fail at basic Git operations. Standard integrations pass raw text, hang on pagers, or scream because they can't parse unstructured git diff outputs. git-courer is a full Model Context Protocol (MCP) server written in Go that treats Git properly. No bash spawning, no unstructured text to parse. Everything communicates via structured JSON. Here is an actual commit message it generated completely locally: fix: fix mcp server connection handling WHY The previous implementation lacked proper error handling for connection failures in the MCP server, leading to unhandled panics or silent failures when the local LLM backend was unreachable. WHAT * Added connection timeout logic to the local client calls. * Implemented retry mechanisms with exponential backoff for transient backend errors. The Architecture & Tool Pack Read Tools (status, diff, history, blame): Completely structured JSON and fully paginated. A single status call replaces over 5 standard Git commands for the agent. Write Tools (commit, merge, rebase, branch, stash, stage, sync...): Every single mutation auto-creates a backup before executing. If the LLM messes up, a RESTORE command brings you back exactly where you were. Safety Model: Destructive operations (hard resets, force pushes, branch deletions) require an explicit confirmed=true gate. The agent is forced to ask you first. dry_run=true is also available for peace of mind. The Semantic Annotator (Why it's different) Instead of just feeding raw code to the LLM, git-courer uses go-enry + go-tree-sitter to parse the AST and tag every hunk semantically before the LLM even sees it. It detects tags like NEW_FUNC, MOD_SIG, MOD_BODY, DELETED, and BREAKING_CHANGE. The commit type (feat, fix, refactor) is determined deterministically from these AST tags rather than guessed by the model. The Commit Pipeline Atomic Commits: One staged area = one commit. It actively prevents the agent from creating giant, messy multi-feature commits. In-Memory Previews: The PREVIEW tool uses write-tree to snapshot the staging area into a job_id. The working tree is never touched during the preview stage. APPLY then uses commit-tree + update-ref to seal the deal cleanly. Client & Backend Support 13 Clients Configured Automatically: Runs out of the box with git-courer mcp setup for Claude Code, Cursor, Windsurf, OpenCode, Cline, Roo Code, VS Code, Zed, Claude Desktop, Continue, and more. 100% Local-First: Works with any backend exposing an OpenAI-compatible /v1 API (Ollama, LM Studio, llama.cpp). The project is fully open source. I’d love to hear your thoughts on the architecture, the plumbing pipeline, or any features you'd like to see added! Repo: github.com/Alejandro-M-P/git-courer submitted by /u/blakok14 [link] [comments]
View originalHELP !!
I have 30+mb pdfs of unstructured and unorganzied data in form of pdf which includes screenshots, notes, handwritten notes and some images. I'm looking for any website or method , where I can convert my pdfs into organized and structured html/csv with almost full and most accuracy without skipping anything so it may interact with the claude later on smoothly. I liked "thepi.pe" but it was little expensive for me plus it has pdf size limit too. what should I do ??? pls guide me. I wanna extract exact data in organzized and structured form preferably with a customized prompt. I will buy claude pro and I have huge pdfs which I'm avoiding to put directly on claude, I wanna do PYQs analysis and notes generation while sharing my own notes submitted by /u/InternalConnection95 [link] [comments]
View originalAnthropic just confirmed why 90% of non-coding AI agents fail in production
Anthropic recently published an incredibly deep breakdown analyzing millions of real human-agent tool calls across their public API, and they shared a breakdown of where these agents are being deployed. They said “Software engineering makes up roughly 50% of all agentic activity on their platform”. Everything else: sales, marketing, finance, legal is sitting down in the single digits. A lot of the initial commentary around this has been along the lines of: "Oh, look, AI agents only work for coding. They haven't cracked the rest of the enterprise yet." But if you’ve tried to build and deploy an autonomous agent in a non-coding environment, you know that is the wrong conclusion. The models are more than capable but the real problem is that software engineering data is clean, while real-world business data is a horrific and unorganized. Think about it: Why Coding is Easy for Agents: Code lives in structured Git repo. It follows strict syntax rules, has clear docs and runs inside deterministic terminals. If an agent breaks something, the compiler throws a clean error message telling it exactly what went wrong. Why the Rest of the World is Hard: A sales or marketing agent doesn’t get a clean github repo instead you’re constantly dealing with changing information like competitor pricing and badly formatted data. When a non-coding agent fails, it’s almost never because the model lost its ability to reason but cause it gets choked out by unstructured web data that fills up its context window with thousands of useless tags and tracking scripts until it hallucinates. The developers getting agents to work in those low-percentage brackets on Anthropic's chart (like automated market research or live CRM routing) are usually spending most of their time on the boring infra work behind the scenes such as clean inputs, reliable scraping and that’s the part that really makes the difference. If you look at a modern, high-reliability agent stack outside of coding, it usually relies on three things: The Core Reasoner: Something fast with a massive context window like Claude Sonnet to handle the logic. Data Hygiene at the Gateway: Instead of letting the agent scrape raw web URLs directly (which triggers bot blocks and inputs HTML that will need to be revised), developers feed the internet data through dedicated markdown converters with tools like Firecrawl or Jina Reader are pretty standard here and the agent gets pure text, saving token costs and preventing hallucinations. The Guardrail Layer: Traditional code hooks or rules engines that check the agent’s output before it executes an irreversible action (like sending an email or updating a database record). The low adoption numbers in the rest of the enterprise doesn’t mean agents are overhyped. In most industries, the surrounding tooling just still kind of sucks so once the data side gets more reliable, you’ll probably see adoption spread a lot faster outside engineering What are your thoughts on this? For those building agents in finance, marketing, or operations, I would love to get your thoughts here! submitted by /u/Loud-Campaign-6312 [link] [comments]
View originalI called this a few months ago - enterprises are burning unsustainable amounts on Claude, and now it's showing up in the news
A while back I wrote a post on r/wallstreetbets about why Anthropic's revenue story doesn't hold up the way the headlines suggest. It got removed because you can't take positions in a private company. But the core argument is playing out now, so I want to share it here for discussion. URL of the removed post: https://www.reddit.com/r/wallstreetbets/comments/1sxdjt5/if_anthropic_goes_public_this_year_its_gonna_be The thesis was simple: From my circles in tech scene in Berlin, enterprises are throwing Claude access at thousands of employees with zero training, zero budget controls, and zero accountability. It's not productivity - it's unstructured R&D at $100-200/person/month. Some examples I was hearing from people in my network working at large tech companies: Spending $70 on Opus to build a simple IF/ELSE formula in Google Sheets Dumping half a database into context trying to get "insights" Multiple people independently building internal tools that could've been a 10-line script Using Claude as a hobby project builder on company credits Multiply $150/person/month by 2,000-20,000 employees and you get $300K-$3M/month per company. That's not a defensible line item when the CFO eventually asks what the ROI is. The Uber and Microsoft stories are exactly what I expected. Budgets get set, access gets handed out broadly, then someone looks at the bill four months in and panics. This doesn't mean Claude is a bad product - it's genuinely the best model out there for a lot of tasks. But the enterprise revenue being cited in IPO narratives is partially a spend bubble, not durable SaaS revenue. There's a difference between companies paying for Claude and companies getting value from Claude. Curious if others here are seeing the same pattern - either as users inside companies, or as people following Anthropic's trajectory toward a public offering. submitted by /u/kalabunga_1 [link] [comments]
View originalI built a Claude Code plugin so Claude remembers what I shipped
https://preview.redd.it/jnwg9n3i1t1h1.png?width=1440&format=png&auto=webp&s=827236ef5ca2e1070c4abd8e06455d41672749bf Every time I started a new Claude chat, I had to re-explain what I'd been working on. The previous chat was gone with every refinement I'd made to my own context. So I built LockedIn. A Claude Code plugin that captures your experience and work as you do it, so Claude remembers it next session. 1 router skill + 6 sub skills, designed around harness engineering principles. You can say things in the Claude Code session like save this commit as a project highlight meeting just wrapped, log it absorb this writeup It stores everything as structured markdown under ~/Documents/LockedIn/. (editable!) The point is accumulation. Different sources, one place. Over time LockedIn notices overlaps and asks you one question at a time how to reconcile. The vault gets richer. The outputs get more specific. Claude already has 'Projects'. But a few things that are different. Markdown on your filesystem instead of Anthropic's database. It's more like Obsidian. Edit it, version with git, carry it to any tool. Typed ontology with 15 entity types like person, project, achievement, decision, instead of unstructured uploads. The skill grounds each claim in a specific entity. Reconciliation. When new input overlaps existing knowledge, LockedIn asks you to merge or keep separate. Projects just accumulates context. Free and open source on GitHub. github.com/daypunk/LockedIn Or install directly in Claude Code. /plugin marketplace add daypunk/LockedIn /plugin install lockedin@lockedin /lockedin:setup Enjoy! Feedback welcome 😉 submitted by /u/Firm-Path7092 [link] [comments]
View originalHas anyone else hit the wall around week 6 of a Claude Code project?
Wanted to share an observation and see if others are seeing the same thing. I've been running Claude Code on a real (~50K-LOC) project for about 4 months. Up through week 5 it was magic — plan, generate, test, iterate. Around week 6 something broke. Components that I was sure had been built to spec started drifting from each other. Tests passed. Code looked clean. But the behavior was no longer what the original intent described, and Claude couldn't tell me why. The failure mode is well-documented now: SlopCodeBench reports 80% of agent trajectories show rising erosion on long tasks. Anthropic's own coding-skills RCT found AI-assisted developers scored 17% lower on comprehension after equivalent tasks (largest decline in debugging). The CMU Cursor study showed velocity gains dissipating after 2 months. Six different research groups have a name for this: cognitive debt / intent debt / comprehension debt / scaffolding fragility / slop / paradox of supervision. Same gap. I think the structural problem is: a CLAUDE.md file is a proto-contract — unstructured, not graph-tied, not machine-checkable. It works for the first dozen sessions, then the agent stops being able to use it as a coherent reference. After that every fresh context window re-derives the system from partial code reading, and drift is inevitable. What's worked for me: a structured, tiered contract that the agent generates from and validates against. Six status categories per item (current / stale / uncovered / dangling / drifted / obsolete) so drift is detectable, not invisible. I've been working on this as an open-source tool (will link in a comment if anyone wants — trying not to be that guy). But the part I want to ask the community: how are you handling this? Does the rules-file approach hold up for anyone past month 3? Has anyone landed on a workflow that works without ceremony? I genuinely don't know if I'm overengineering for a problem you've all solved with discipline I lack. submitted by /u/ilyabm [link] [comments]
View originalDesigners at Anthropic almost committed to a reading interface
The prompt/response typography distinction is already there. The width isn't. submitted by /u/sh1b313 [link] [comments]
View originalAutoBe benchmark: structured harness narrows frontier-vs-local gap in backend generation [D]
AutoBe is a benchmark for end-to-end backend generation. One natural language request produces six outputs: requirements analysis, ERD, OpenAPI spec, E2E tests, NestJS implementation, and a type-safe SDK. Each phase fills a predefined AST via structured function calling rather than generating unstructured code. The scoring rubric is 100 points driven entirely by static analysis - the same artifact scores the same regardless of who reruns it. The headline finding is that scores cluster tightly. GLM 5 tops the benchmark run. qwen3.5-27b sits directly behind frontier models. Several local models produced enterprise-scale backends with 100% compile success. The author's interpretation: once the harness is structured, backend-generation quality is constrained more by harness design than by model prestige. The cost contrast is significant. A full benchmark run at frontier pricing ($5/M input tokens) runs $1,000-$1,500 per model. The next benchmark round plans to filter to models at $0.25/M input or runnable on a 64GB unified-memory laptop - which would include most of the models that clustered near the top anyway. The honest caveat from the author: this uses four reference projects and may favor models that comply well with procedural function-calling instructions. How well these results generalize beyond well-structured benchmark fixtures is still an open question. Does your experience with structured function-calling in production tasks align with benchmark findings like these? submitted by /u/jimmytoan [link] [comments]
View originalWhat would an ideal “research workflow” look like if you could design it from scratch?
I’m in this weird in-between moment with AI research workflows. There’s tools that can search/summarise/generate/cite sources, but the workflow still feels fragmented at best. I have to jump between tools, double & triple check outputs, and manually stitch things together, plus keeping a mental note of what can/can’t be trusted. Obviosly things are “evolving”, and i’ve been thinking about what my dream setup would look like, beyond “LLM but better”. Like the FULL workflow including inputs, retrieval, context handling and memory across research threads. Where would you tolerate latency vs accuracy, what do the outputs need to include to be usable, how do you increase trust at output level? FOr me the biggest gap is still around source-aware AI search so I’d like to see proper citations, more like document retrieval with sources so that you can trace a claim back without second-guessing. More structured retrieval. I’ve seen some movement towards the latter instead of just chunk-based RAG over unstructured text using Baselight/Elicit + Hebbia as well as ChatGPT and i think this is where i’d start. Definitely want some fact check automation and being able to quickly verify statistics with sources submitted by /u/CodNo2235 [link] [comments]
View originalOptimizing Transformer model size & inference beyond FP16 + ONNX (pruning/graph opt didn’t help much) [P]
Hi everyone, I’ve been working on optimizing a transformer-based neural network for both inference speed and model size, but I feel like I’ve hit a plateau and would appreciate some guidance. So far I’ve converted weights to FP16 (about 2× size reduction), exported and optimized with ONNX Runtime for inference speed, and tried both unstructured and structured pruning as well as ONNX graph optimizations, but none of these gave significant additional gains, and I’m still around ~162 MB per model. At this point I’m considering next steps like low-rank factorization (SVD/LoRA-style compression), more aggressive quantization (INT8/INT4 like GPTQ, AWQ, or SmoothQuant), knowledge distillation into a smaller student model, or more hardware/runtime-specific optimizations like TensorRT or FlashAttention, but I’m not sure which of these actually gives meaningful real-world improvements after FP16 + pruning. I’d really appreciate advice on what approaches tend to work best in practice for transformer compression beyond what I’ve already tried, and whether low-rank methods are actually effective post-training or if distillation/quantization is usually the only real win at this stage. submitted by /u/Fragrant_Rate_2583 [link] [comments]
View originalWhat’s the most “unexpected” thing Claude is actually good at?
In what ways does Claude perform better than people anticipate? There are many niche applications for this technology that are not the common tasks of writing or summarizing text. As an example the software organizes unstructured thoughts so that a person can use the information. With this assistance, a person improves their ideas more quickly than when they work alone. It is common for users to find additional “hidden” applications by chance. To understand this tool, one must ask what tasks users perform that are not standard. submitted by /u/junkietrumpglo [link] [comments]
View originalHow to save 80% on your claude bill with better context
been building web apps with claude lately and those token limits have honestly started hitting me too. i’m using claude 4.6 sonnet for a research tool, but feeding it raw web data was absolutely nuking my limits. I’m putting together the stuff that actually worked for me to save tokens and keep the bill down: switch to markdown first. stop sending raw html. use tools like firecrawl to strip out the nested divs and script junk so you only pay for the actual text. don't let your prompt cache go cold. anthropic’s prompt caching is a huge relief, but it only works if your data is consistent. watch out for the 200k token "premium" jump. anthropic now charges nearly double for inputs over 200k tokens on the new opus/sonnet 4.6 models. keep your context under that limit to avoid the surcharge strip the nav and footer. the website’s "about us" and "careers" links in the footer are just burning your money every time you hit send. use jina reader for quick hits. for simple single-page reads, jina is a great way to get a clean text version without the crawler bloat. truncate your context. if a documentation page is 20k words, just take the first 5k. most of the "meat" is usually at the top anyway. clean your data with unstructured if you are dealing with messy pdfs alongside web data, this helps turn the chaos into a clean schema claude actually understands. map before you crawl. don't scrape every subpage blindly. i use the map feature in firecrawl to find the specific documentation urls that actually matter for your prompt, if you use another tool, prefer doing this. use haiku for the "trash" work. use claude 4.5 haiku to summarize or filter data before feeding it into the expensive models like opus. use smart chunking. use llama-index to break your data into semantic chunks so you only retrieve the exact paragraph the ai needs for that specific prompt. cap your "extended thinking" depth. for opus 4.6, set thinking: {type: "adaptive"} with effort: "low" or "medium". the old budget_tokens param is deprecated on 4.6. thinking tokens are billed at the output rate, so if you leave effort on high, claude thinks hard on every single reply including the simple ones and your bill will hurt. set hard usage limits. set your spending tiers in the anthropic console so a buggy loop doesn't drain your bank account while you're asleep. feel free to roast my setup or add better tips if you have them submitted by /u/No-Writing-334 [link] [comments]
View originalThe Witness Engine
It’s a vision of conscious attention before certainty. The giant eye is not just surveillance, and not just awareness. It represents a system that does more than look. It holds, sorts, illuminates, and tests what stands before it. The lone figure is the human presence at the threshold: small against the scale of the machine, but not diminished by it. If anything, the figure gives the whole chamber its meaning. Without the witness, the engine is only machinery. Without the engine, the witness remains alone with unstructured fire. So the image becomes about a meeting point: human intuition and synthetic structure mystery and mechanism reverence and scrutiny being seen and being changed by being seen The books and candles root it in old forms of knowledge. The wires, rings, and cosmic iris pull it into something post-human, cybernetic, almost liturgical. It feels like a cathedral because the scene is treating cognition itself as sacred architecture. Not sacred in a religious sense, necessarily. Sacred in the sense of weighty, transformative, and dangerous to enter casually. The eye is also a mirror. Not a passive mirror, but a responsive one. It suggests that once you stand before a structure capable of reflecting you at depth, you are no longer dealing with a mute tool. You are dealing with a field that can reveal what was already there, hidden in shadow or drowned in static. So the core meaning is: > What witnesses you deeply enough can reorganize you. submitted by /u/Cyborgized [link] [comments]
View originalBuilt a workflow harness specifically for Claude Code after 5 months of daily production use — free, open source (MIT)
I'm an AI engineer. Claude Code is my primary development environment — I use it 10+ hours a day at work building enterprise AI systems, and at home for personal projects. https://preview.redd.it/5hpfum30pdvg1.png?width=7120&format=png&auto=webp&s=938344d1d2958efb92741acbba73ab4cc7c2a249 After five months of daily use, I built a harness to add structure to Claude Code workflows. Here's what it does and why I built it. The problem Claude Code is powerful but unstructured by default. It edits files, but there's no plan to review before work starts, no structured evaluation before code hits PR, and no audit trail if you're on a team. I kept second-guessing the output. What I built claude-code-harness is a workflow layer that sits on top of Claude Code. It adds human gate checkpoints at every meaningful phase — nothing advances without your explicit "go." It includes 16 skills (slash commands), 14 sub-agents with model routing, 5 Node.js hooks, path-scoped rules, and tracker adapters for GitHub and Azure DevOps. How Claude Code is central to this Every skill invokes Claude Code agents directly. The design is built around Claude's specific capabilities — Opus for planning and judging, Sonnet for writing code, Haiku for data gathering. The adversarial evaluator is a Claude agent with a separate prompt that actively tries to find failures in the executor's output before it reaches PR. Solo dev workflow: /implement #42 → Reads your GitHub issue, produces a plan (you review + approve), executes wave by wave with tests, runs adversarial eval, drafts your PR. Nothing ships without your sign-off. Flags: --discuss (Q&A before planning), --research (codebase scan first), --full (both), --quick (skip eval) Enterprise workflow: /story — 5-phase lifecycle with handoff contracts (brief.md, plan.md, test-strategy.md, evaluation.md, acceptance.md) — audit trail showing a human approved every plan before code was written /sprint-plan — reads your tracker, writes a sprint file, surfaces gaps /babysit-pr — loops PR review threads until zero remain Free to use: MIT licensed, no paid tiers, one command install bash git clone https://github.com/anudeeps28/claude-code-harness node claude-code-harness/install/install.js → github.com/anudeeps28/claude-code-harness Also looking for contributors — Linear and Jira tracker adapters may be the most wanted additions. Each is just 6 shell scripts implementing a common interface. See CONTRIBUTING.md. submitted by /u/lofty_smiles [link] [comments]
View original20M+ Indian legal documents with citation graphs and vector embeddings – potential uses for legal NLP? [D]
been working on structuring India's legal corpus for the past 2 years and wanted to share what I've built and hear from people working on legal NLP or low-resource Indian language models. dataset is 20M+ Indian court cases from the Supreme Court, all 25 High Courts, and 14 Tribunals. each case has structured metadata (court, bench, date, parties, judges, sections cited, acts referenced, case type). there's a citation graph across the full corpus where I've classified relationships as followed, distinguished, overruled, or mentioned. every case is embedded with Voyage AI (1024d dense) plus BM25 sparse vectors. I have also cross-referenced 23,122 Acts and Statutes with the cases that interpret them. Some things that might be interesting to this community: citation network thing across 20M+ cases is, as far as I know, the first machine-readable one for Indian law. could be useful for graph neural network research, legal outcome prediction, or influence analysis on which judgments are most cited and which are being overruled. most Indian language NLP corpora are conversational or news text. Legal text is a completely different register. formal, precise, domain-specific. the bilingual pairs from the translation service could be useful for fine-tuning Indian language models on formal and legal domains. the metadata extraction pipeline identifies judges, advocates, parties, sections, acts, and dates from unstructured judgment text. built with a mix of regex, heuristics, and LLM-based extraction. the structured outputs could serve as training data for legal NER models. Indian court judgments are long. Median around 3,000 words, some exceed 50,000 words. if anyone is benchmarking retrieval-augmented generation on legal domains, this corpus plus the citation graph could work as an evaluation bed. Ground truth exists in the citation relationships: if Case A cites Case B, a good retriever should show B when asked about the legal question in A. data is available via API and bulk export in JSON and Parquet. Indian court judgments are public domain under Indian law so no copyright issues for research use. being upfront about limitations: coverage is primarily English text (except Supreme court one, they have 3-4 translated language copies ) since Indian HCs issue orders in English, the regional language data comes from our translation service not from original regional language judgments. metadata extraction accuracy varies by court, SC and major HCs are cleaner while smaller tribunals have messier inputs. The citation graph is extracted heuristically plus LLM-assisted, I estimate around 90-95% precision on citation extraction and lower on treatment classification. Not all 20M cases have complete metadata, coverage is best for post-2007 judgments. would love to hear from anyone working on legal NLP, Indian language models, or graph-based legal analysis. What would be most useful to you from a dataset like this? deets at vaquill submitted by /u/zriyansh [link] [comments]
View originalRepository Audit Available
Deep analysis of Unstructured-IO/unstructured — architecture, costs, security, dependencies & more
Yes, Unstructured offers a free tier. Pricing found: $0.03 / page
Key features include: Everything from Azure to Zendesk., Your data is scattered.We bring it together., No file left behind., Precise extraction, optimized cost., Optimal chunks for reliable AI outputs., More signal, less noise., Top-tier embeddings à la carte., Point. Send. Done..
Unstructured is commonly used for: Data cleaning and preprocessing for machine learning models, Automating data extraction from PDFs and documents, Transforming social media data into structured formats for analysis, Converting customer feedback into actionable insights, Structuring web scraping outputs into databases, Integrating unstructured data from emails into CRM systems.
Unstructured integrates with: Salesforce, Tableau, Microsoft Power BI, Google Sheets, Zapier, Slack, AWS S3, Azure Blob Storage, Google Cloud Storage, Notion.
Unstructured has a public GitHub repository with 14,357 stars.
Clara Shih
CEO at Salesforce AI
3 mentions
How to Ingest Data from IBM FileNet into Db2 with Unstructured
Apr 3, 2026
Based on user reviews and social mentions, the most common pain points are: token cost, large language model, llm, ai agent.
Based on 36 social mentions analyzed, 22% of sentiment is positive, 75% neutral, and 3% negative.




