
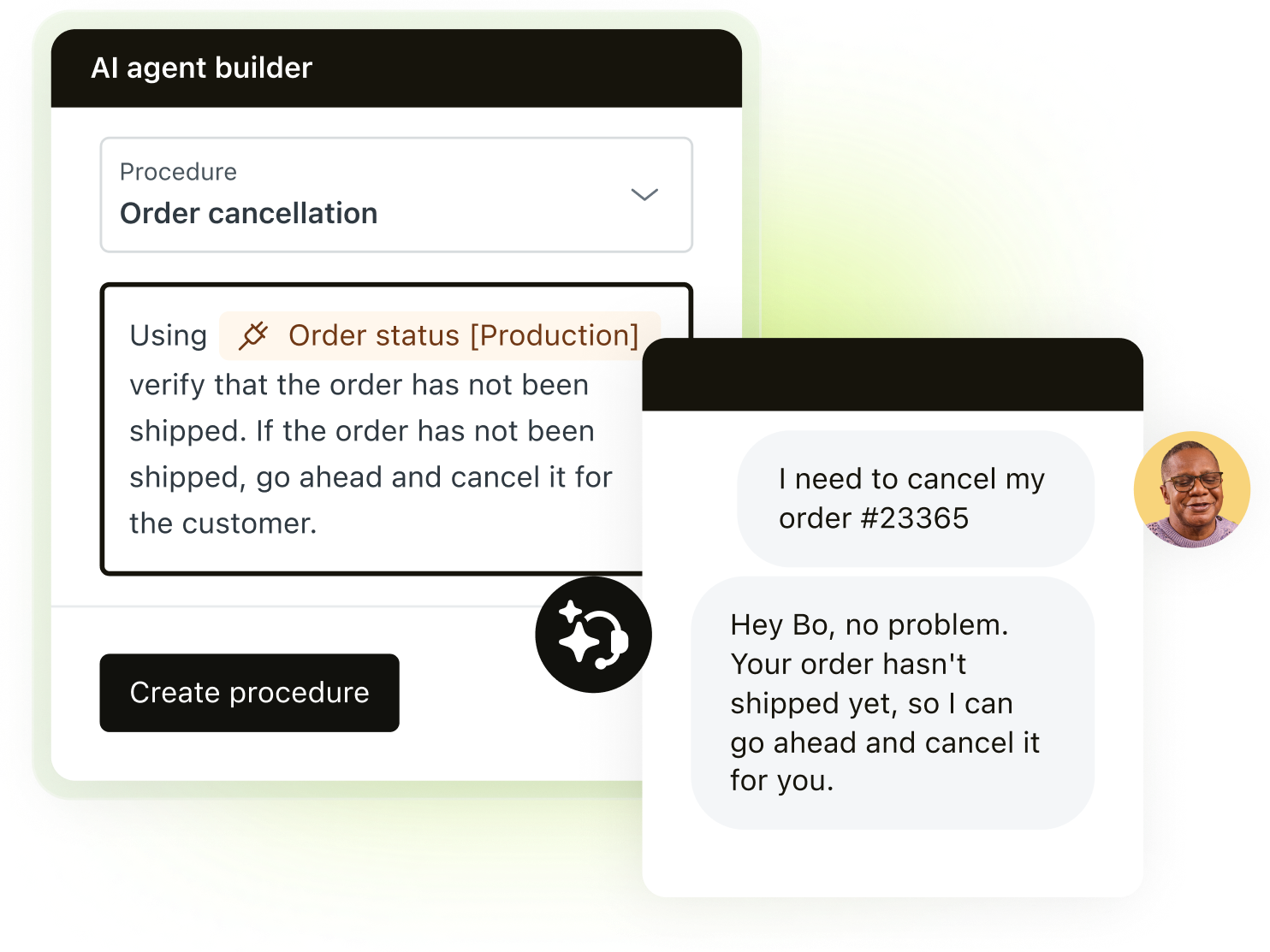
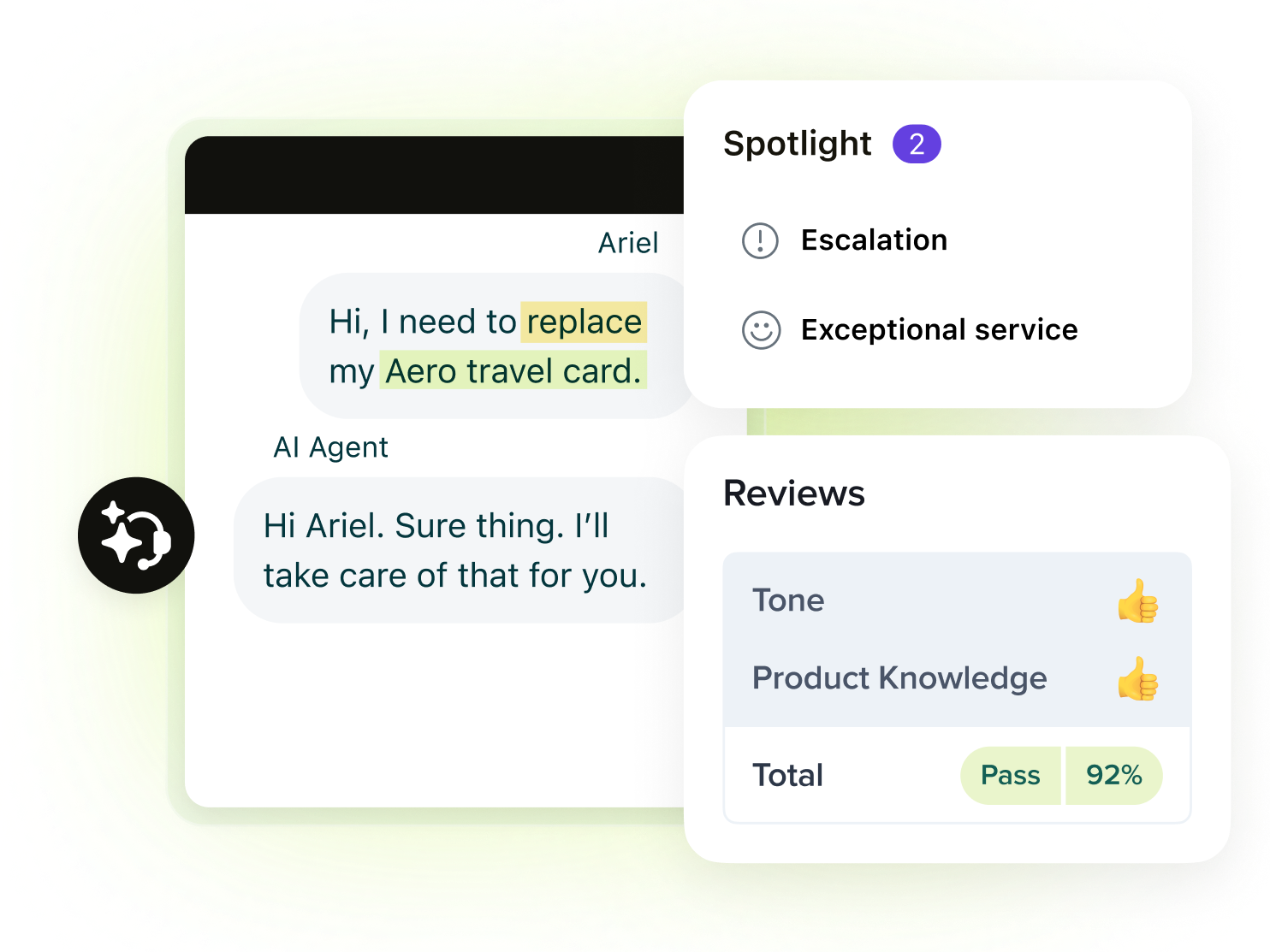
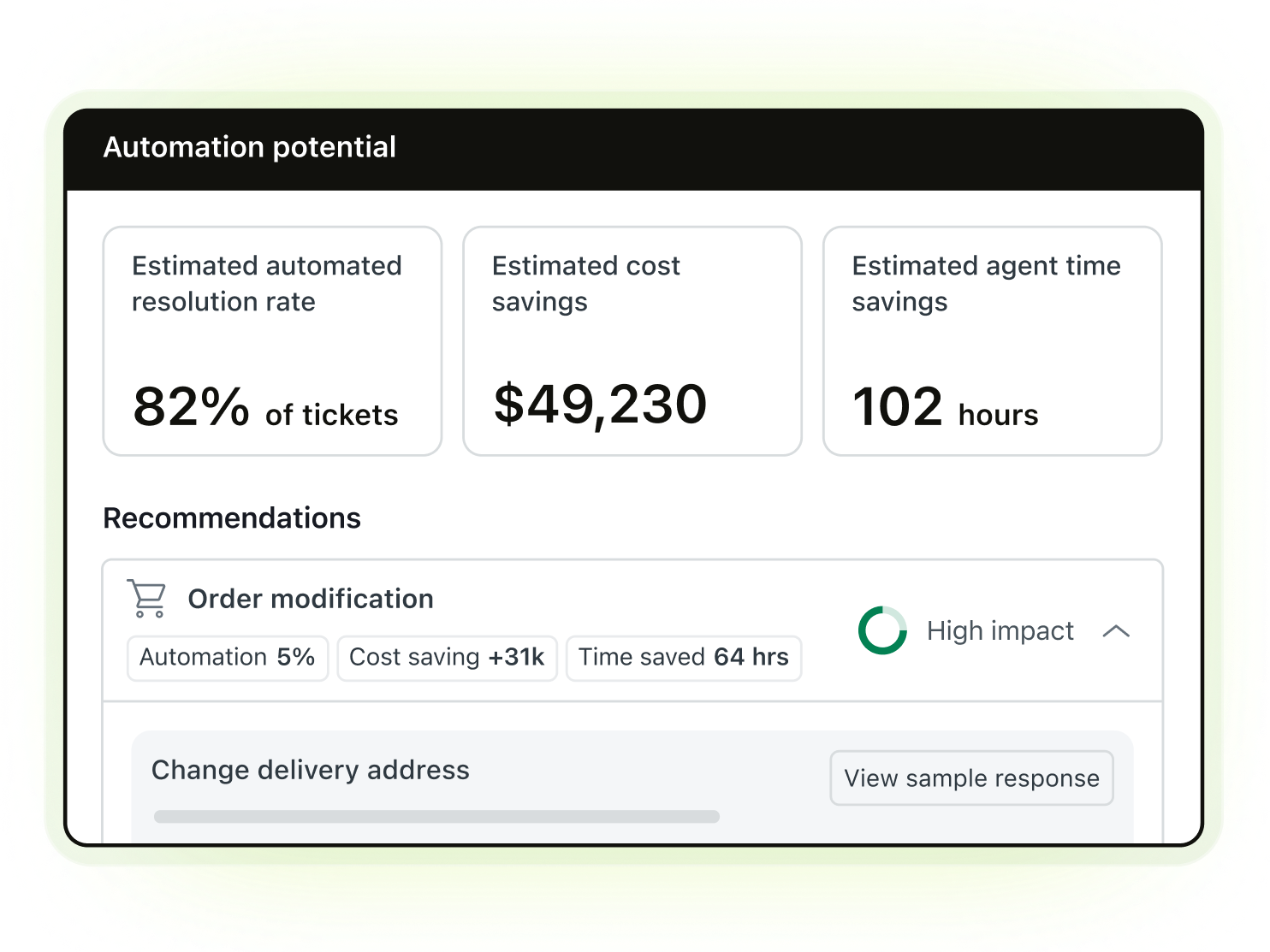
Deploy AI agents that resolve up to 80% of customer interactions. Automate service and improve every outcome—start your free trial.
User feedback on "Ultimate" highlights its strong utility in job management and automation, with excitement stemming from its practical applications in streamlining these tasks. However, some users would appreciate improvements in user interface and customization options to better fit individual needs. While pricing seems to be a point of contention, with some expressing concerns over its affordability, the overall sentiment labels it as a valuable investment for its effectiveness. The software enjoys a solid reputation for enhancing productivity, particularly among tech-savvy users.
Mentions (30d)
27
3 this week
Reviews
0
Platforms
4
Sentiment
19%
16 positive
User feedback on "Ultimate" highlights its strong utility in job management and automation, with excitement stemming from its practical applications in streamlining these tasks. However, some users would appreciate improvements in user interface and customization options to better fit individual needs. While pricing seems to be a point of contention, with some expressing concerns over its affordability, the overall sentiment labels it as a valuable investment for its effectiveness. The software enjoys a solid reputation for enhancing productivity, particularly among tech-savvy users.
Features
Use Cases
Industry
information technology & services
Employees
140
Funding Stage
Merger / Acquisition
Total Funding
$26.2M
In 10 Minutes with AI, I Just Got More Closure on My Divorce than 4 Years of Therapy
Apologies if this is rather personal for this sub but I feel a need to express how profoundly useful it was for me tonight. A Chatbot very likely just saved my life. I am positively floored by how therapeutic it was in processing the beginning and ending of my relationship with my former spouse. I feel as though I finally can give myself permission to let go and move on with my life. I don’t know what this says about technology and society, but it’s beautiful. Edit: I STILL have a therapist I meet with regularly! No one is saying that therapy can be replaced by Chat GPT prompts. I am merely showing how you can gain expediency and clarity through AI with difficult situations. Update: as if I need to validate against any of this with the haters - just went over all of this with my 3D therapist. She was very supportive of my approach and ultimate takeaways from the AI. 😝
View originalThe year is 2026. AIs are literally inventing new math, yet journalists are still posting obviously false stuff like this. How can a database solve math problems no human has ever been able to solve?
submitted by /u/EchoOfOppenheimer [link] [comments]
View originalFree tier users: Let's share out best practices for efficiently using the limits!
Let me start by saying this: I believe a thread like this can be structured in a way that complies with the rules, and I hope the mods will allow it. This isn’t meant to be a place for ranting or arguing, but rather a helpful and constructive one (Rules 2 & 3). I know that Anthropic needs revenue, but I also believe that satisfied users are ultimately more likely to contribute to it. But now to the topic at hand: When working on larger or longer projects with Claude as a free user, you want to use your limits as efficiently as possible. I’d love it if you could share helpful tips and perhaps also potential pitfalls. I'd guess that free users will more likely tend to be casual or novice users, therfore it would be great if you'd keep that in mind (: Here’s my first contribution. This is just for starting a conversation and is not supposed to be a secret or expert trick. I can't give those, beacause I ain't one. It goes without saying that more input/output consumes more tokens. That’s why I’ve given Claude basic instructions regarding potentially computationally intensive tasks (auto-translated from German): Always check with me before analyzing, modifying, or creating a new script. Always provide an estimate beforehand of how long or how much work it will take to edit or create scripts. If you need to analyze the script to do this, check with me. Before you make changes yourself or analyze a script—for example, in response to an error message I sent—first try to post a fix in the chat with as little effort as possible and without checking the entire script. I can insert simple things myself. If you only want to make minor changes to a script, don’t repost the entire script as output or a new file. Just give me the change and tell me where it needs to be applied. I’ll handle the rest. Please try to work in a data-efficient manner rather than as thoroughly as possible. The stakes in this project are low, and there is no time pressure. Ask before you start a computationally intensive task. I am aware that this is a basic way of doing this. Maybe you have some ideas how to achieve the same without having to manage claude actions explicitly? submitted by /u/bk-2cb [link] [comments]
View originalHere are my thoughts of Opus 4.8 and GPT 5.5, as a 1-2 B token user per day
TL;DR: Opus 4.8 is a clear update from Opus 4.7. It runs longer, hallucinates less, and follows detailed guided tasks better, especially with tool usage like Playwright, Cloud CLI, and Kubernetes CLI. However, in the context of Agentic AI, GPT-5.5 gives me a much stronger “wow” moment because it feels more autonomous, more context-stable in very long sessions, and more capable at solving tricky large-codebase problems that Opus 4.6, 4.7, and 4.8 could not solve in my workflow. Using 2 CC Max + 1 Codex Pro What’s better in Opus 4.8 Opus 4.8 is definitely an update from Opus 4.7. It runs longer, hallucinates less, and does better what it is asked than Opus 4.7. Also, it is better at tool usage such as Playwright, Cloud CLI, Kubernetes CLI, and other engineering tools. Opus 4.8 performs better when the task is detailed and properly guided. Since most developers are already using Agentic AI to write code, I think Opus 4.8 is clearly a better model for developers who already have enough domain knowledge and can define the task scope finely. When using the newly added /workflows feature, it can handle a wider range of tasks more effectively without much mid-run intervention than Opus 4.7. However, because of this characteristic, and also because of the general nature of the Opus 4.7 and Opus 4.8 family, I still do not think Opus 4.8 is more autonomous-agentic than early Opus 4.6 in vibe coding or less-domain-knowledge situations. When we use AI, we expect that AI has the ability to just get it, use good judgment, and handle things cleanly without needing every tiny instruction, like Jarvis from Iron Man. In that sense, Opus 4.8 tends to not proceed with things outside of the explicitly defined scope unless I tell it clearly. I guess this may be related to solving the chronic hallucination and trustworthiness problem of Agentic AI(well, this comes from the current architectural limit of LLM, derived from Attention mechanisms with gradient descent), but it also makes the model feel less autonomous. Personal opinion about Opus 4.8 This is a bit disappointing in the era of Agentic AI, and I will explain more clearly by comparing it with GPT-5.5 below. Generally, as AI and other technologies improve, the human work range should not only expand horizontally but also vertically. So if I ask whether Opus 4.8 has developed in the direction that humans expect from AGI, I am not fully convinced. I do not have the same “wow” moment that I had when I first used early Opus 4.6. Humans have a clear biological limit in daily cognition and decision-making. This is separate from AI progress itself. As Andrej Karpathy and others have mentioned in different ways, humans themselves often become the bottleneck. If we want to overcome this limit through AI, I think AI should ultimately go in the direction of early Opus 4.6 or GPT-5.5. Simply speaking, regardless of the 5 h token limit, to use Opus 4.8 effectively, the human still needs to think a lot. You need to define more, guide more, and maintain more of the context yourself. For doing more work effectively, this becomes a critical bottleneck. GPT-5.5 GPT-5.5 is definitely a major update from the perspective of Agentic AI. It gives me a similar “wow” moment that early Opus 4.6 gave me. https://preview.redd.it/j2rihxtjf34h1.png?width=257&format=png&auto=webp&s=a3f39721cc573f1e623d90e4592ffa54b7a24b7f Opus 4.8 also runs longer and hallucinates less than previous models, but GPT-5.5 is on another level in my experience. Even in long-running sessions of more than 12 h, hallucination and context dilution are surprisingly low. This part is almost strange to me. I currently use the same kind of harness engineering tool for both Opus and GPT. In that environment, Opus does very well on exactly specified scopes, while GPT-5.5 also understands and proceeds with parts that I did not specify in very fine detail. This may be connected to the same point, but GPT-5.5 feels smarter in a more human way. Even in simple conversation, I feel the difference. Opus 4.8 answers like a very skilled engineer, but usually in a more verbose way. Opus 4.7 was even more verbose. GPT-5.5 tends to answer with the right length for what the user currently needs. In other words, from the user’s perspective, I spend less time and less cognitive energy interpreting the agent’s answer. Interestingly, the final output is also often better from GPT-5.5. Of course, depending on how detailed the user’s prompt is, the difference can become small, and sometimes Opus 4.8 can be better. But in that case, I usually need to spend more time on prompting and context preparation. The biggest advantage of GPT-5.5 comes from combining the two points above: it is extremely good at solving tricky bugs, feature improvements, and migration tasks in large codebases. In my case, I am currently migrating a C++ and Cython/Python based quant system into Rust and Python. With Opus 4.6, 4.7, and 4.8, there were some tasks that
View originalThe Quality of Understanding...Dialogue over Division
Humanity has accumulated unprecedented amounts of information, yet despite extraordinary advances in intelligence and technology, civilization still struggles to understand itself with depth, wisdom, and clarity. We now live in an accelerated age shaped by endless data, instantaneous communication, and increasingly powerful systems capable of processing information at extraordinary speed. Yet despite these technological advances, many of humanity’s oldest struggles persist: division, fear, inequality, polarization, and recurring cycles of conflict. Perhaps the challenge has never been intelligence alone, but whether humanity develops the understanding and wisdom necessary to guide it responsibly. There is a profound difference between possessing information and truly understanding the human condition. Computational intelligence can analyze patterns and generate solutions, but understanding requires context, reflection, emotional awareness, and the willingness to see beyond oneself. Intelligence can accelerate decisions. Understanding determines whether those decisions lead toward flourishing or destruction. The instinct to rush toward faster solutions may ultimately deepen the very problems humanity hopes to solve. A civilization conditioned for acceleration may begin mistaking speed for progress, reaction for understanding, and certainty for wisdom. Understanding rarely begins through reaction alone. It begins through awareness. Yet modern civilization increasingly rewards the opposite. Outrage spreads faster than thoughtful dialogue, while certainty and conflict generate more attention than curiosity, reflection, or deeper understanding. The result is a culture increasingly shaped by fragmentation — fragmented thinking, fragmented empathy, and fragmented understanding. Perhaps it begins with learning to see people as human beings again rather than as usernames, ideological categories, or digital avatars. Behind every screen exists a real person shaped by experiences, fears, hopes, struggles, and emotions far more complex than any comment thread, profile, or algorithm. And yet many of humanity’s greatest advancements in ethics, justice, diplomacy, science, and human rights emerged not merely from intelligence, but from a deeper understanding of suffering, consequence, interconnectedness, historical patterns, and the shared humanity within one another. What may be most necessary is also deeply counterintuitive: the willingness to slow down long enough to observe, reflect, and truly understand, and then to engage in more thoughtful forms of collective dialogue — spaces where ideas can be explored with curiosity, forethought, courtesy, and mutual respect. Most people naturally make decisions based on what benefits them or those closest to them; however, as technology becomes increasingly powerful and interconnected, humanity may need to ask a larger question: Who is intentionally considering what is best for humanity as a whole? Maybe it's time humanity begins thinking of itself not merely as billions of separate individuals, but as a shared civilization with collective needs, responsibilities, and long-term consequences. Our future will not depend upon outcompeting artificial intelligence in speed or informational capacity, but upon strengthening the qualities AI cannot fully replicate: empathy, conscience, moral reflection, lived experience, and the ability to create meaning through human connection itself. Humanity’s greatest strength may ultimately lie not in becoming more machine-like, but in deepening those qualities that make us very much human. 🌿 submitted by /u/Sage-Vero [link] [comments]
View originalAI Infrastructure Has a Physical Weak Spot Nobody Talks About Enough - Copper Supply Shocks
Something interesting happened this week that barely crossed into mainstream AI discussion. A strong earthquake in Chile disrupted copper ore production and pushed copper prices higher again. Chile matters because it produces roughly 24% of the world’s copper supply, and a huge part of global AI infrastructure indirectly depends on that metal. That connection is becoming impossible to ignore. Everyone talks about GPUs, compute scaling, inference costs, and power demand. But very few people talk about the raw materials underneath the entire AI stack. Copper is everywhere inside AI infrastructure: * data center power systems * transformers * cooling systems * switchgear * high-voltage cabling * backup energy systems * grid expansion * GPU interconnect infrastructure A single hyperscale AI data center can reportedly consume tens of thousands of tonnes of copper depending on scale and power architecture. At the same time, global copper supply is getting tighter: * new mines can take 15-20+ years to develop * major deposits are aging * permitting remains difficult globally * geopolitical risk keeps increasing * now even earthquakes are disrupting supply chains This is where the story becomes interesting from an AI perspective. AI demand growth is exponential. Copper supply growth is not. That mismatch is why more people are suddenly watching early-stage copper exploration companies again. One example is NovаRed Mining Inc. and its Wilmac Copper-Gold Project in British Columbia. Not because it is producing copper today - it is not. But because markets are starting to realize future AI infrastructure may require entirely new copper discoveries. Some interesting details about Wіlmac: * 16,078 hectares in BC’s Quesnel porphyry belt * located near Hudbay’s Copper Mountain Mine * soil results up to 1,125 ppm copper * interpreted intrusive centers identified * recent IP/AMT geophysics added deeper targeting data * company also pushing an AI-assisted targeting platform called MetalCore The bigger point is not "this stock goes up." The bigger point is that AI is no longer just a software story. It is becoming a materials story. And every supply disruption - whether geopolitical, regulatory, or seismic - reminds the market that physical infrastructure still matters. The AI boom may eventually depend just as much on copper supply chains as on semiconductor innovation itself. NFA.
View originalCerebras Chip Sets Appear to be Optimized for LLM Use Cases
One distinction I think is getting lost in the [Cerebras hype cycle](https://finance.yahoo.com/sectors/technology/articles/cerebras-challenges-nvidia-chip-dominance-040100169.html?guccounter=1) is that Cerebras is primarily an LLM / generative AI infrastructure story, not a universal “all AI” chip story. That is not necessarily a criticism of Cerebras. Their wafer-scale approach is genuinely interesting, and for large model training and inference the design is compelling. [Cerebras’ own public inference materials](https://inference-docs.cerebras.ai/models/overview) discuss applications mostly centered on open [LLMs such as Llama, Qwen, GLM, and GPT-OSS](https://www.cerebras.ai/infcamp). The inference metrics are [expressed in tokens per second](https://www.cerebras.ai/press-release/cerebras-launches-the-worlds-fastest-ai-inference), which is fundamentally a language-model / generative inference framing rather than a robotics or industrial-control framing. **What Kind of AI Compute?** But “AI compute” is not one undifferentiated market. LLM inference is one class of AI compute. Robotics, autonomous vehicles, drones, industrial controls, real-time vision, embedded perception, video pipelines, and sensor-fusion systems are very different classes of AI compute. Thus, it appears from Cerebras’ own materials that their chip sets are not optimized for what comes after LLMs, such as JEPA-style World Models or other post-transformer architectures. Those systems are not merely asking, “How fast can I generate tokens?” They often care about power envelope, edge deployment, ruggedization, latency determinism, camera/radar/lidar integration, feedback loops, safety certification, and real-time physical control. [Cerebras’ own CS-3 messaging](https://www.cerebras.ai/blog/cerebras-cs3), by contrast, frames the system around accelerating “the latest large AI models,” and the testing data is from the likes of Llama 2, Falcon 40B, MPT-30B, and multimodal models, again measured through tokens/second style throughput. **The Chip Hierarchy** This is also where the hardware distinction matters. Specialized ASICs are [usually the narrowest bet](https://www.hilscher.com/service-support/glossary/application-specific-integrated-circuit): if the workload matches the chip, they can be extremely efficient, but that [efficiency comes from specialization](https://www.synopsys.com/glossary/what-is-asic-design.html). Cerebras [appears broader than a narrow single-use ASIC](https://inference-docs.cerebras.ai/models/overview), but still much more concentrated around datacenter large-model training and inference. NVIDIA GPUs, by contrast, [are less specialized](https://www.nvidia.com/en-us/) but much [more broadly useful ](https://developer.nvidia.com/cuda)across AI workloads, including LLMs, vision, robotics, simulation, [autonomous systems](https://www.nvidia.com/en-us/industries/robotics/), edge AI, and industrial applications. So the question is not merely whether Cerebras is “better” or “worse” than NVIDIA. The question is what part of the AI hardware market we are talking about? **Challenge NVIDA?** This is why I think people should be careful when saying Cerebras is going to “challenge Nvidia” without specifying the battlefield. Challenge Nvidia in what? High-speed LLM inference? Large model training? Datacenter generative AI workloads? That is a much more plausible and specific claim. Cerebras has [even published and promoted work](https://www.cerebras.ai/whitepapers) specifically on training large language models, and [independent benchmarking literature](https://arxiv.org/abs/2409.00287) also evaluates Cerebras WSE in terms of LLM training and inference performance. **The Distinction that's Necessary** The point is not that Cerebras is overhyped. The point is that it is important in a specific part of AI and that distinction should be made clear. Cerebras may become a very serious player in LLM infrastructure, especially if the market continues to reward faster and cheaper LLM inference. But that does not mean it is positioned the same way across non-LLM AI. The current hype cycle tends to conflate "LLMs" and general “AI” compute together and that makes the hardware discussion less useful and clear. So ultimately, an investment in Cerebras looks more like a bet on current LLM infrastructure than a broad bet on the future form of AI. It may be a good bet, but people should understand what kind of bet it is.
View original170+ versions later, I was able to create a cool RPG inspired by Aztec mythology, playable now!
Hi r/ClaudeAI! After a failed vibe-coding attempt on ChatGPT, I was finally able to build a playable game using Claude as a coding partner. After many rounds of iterative playtesting and debugging, I'm ready to start showing the game to the world! Claude link: https://claude.ai/public/artifacts/f5b6522a-7c74-4658-9006-991afbdf9c6b What is it: Teotlan: Land of Gods is a turn-based RPG with roguelite elements, featuring gods from Mesoamerican mythology. You pick a Patron God (you start with 4 options and unlock more as you progress), then build a team to explore and complete 9 layers of Mictlan (the Aztec Underworld). Core Features: Turn-Based Combat: Both the player and enemies take turns acting, with a focus on unit abilities and positioning. Capture or Kill: Defeated units always give you a choice: capture them to add to your team, or slay them for bonus resources. Sacrifice for Power: Captured units can be sacrificed to summon powerful ally gods. Build the ultimate divine team to conquer Mictlan. Prestige: As a deity, death is not the end. Collect Teotl to unlock powerful upgrades and make each run through Mictlan a little easier. 12 Playable Gods: Each god has a unique patron ability and special move. Can you collect them all? About my dev process: I always start by writing a design doc and locking down the game logic before any code gets written: this gives Claude a solid foundation to build from and makes it much easier to catch hallucinations or inconsistencies. Once Claude produces a build, I play through the entire thing to catch bugs, note improvements, and prepare feedback for the next version. If the game catches your interest, I'd love to hear your feedback: especially how easy the mechanics are to understand, whether the difficulty feels right, and how intuitive the menu navigation is. https://preview.redd.it/7lc9uk3n073h1.png?width=1852&format=png&auto=webp&s=7e63be58526d69bcc7dfa6c75add59c079a39f6d submitted by /u/Reckonerxy [link] [comments]
View originalPhilosophy as Architecture: Deriving AI Safety from First Principles Through Buddhist Philosophy
\## Abstract We present a framework for AI safety in which safety properties are enforced by software architecture rather than model training. Beginning with the Buddhist doctrine of Dependent Origination — the observation that all phenomena arise from conditions and nothing exists independently — we derive both a foundational ethical axiom (harm is irrational because reality is non-separate) and a complete set of architectural laws for safe AI systems. We ground our claims in: (1) an empirical finding that the knowledge-application gap in language models is structural and cannot be closed by training, (2) convergent independent derivation of our core axiom from five distinct traditions, and (3) over a thousand iterations of building and hardening a production system against this framework. Buddhist philosophy provides not metaphorical inspiration but structurally precise design vocabulary for AI architecture — functional analogs that enforce safety where models cannot override them. \## 1. Introduction \### 1.1 The Dominant Paradigm and Its Failure The prevailing approach to AI safety treats safety as a model property. Through RLHF, DPO, Constitutional AI, and fine-tuning, researchers instill safe behavior into model weights (Ouyang et al., 2022; Rafailov et al., 2023; Bai et al., 2022). The assumption: a sufficiently well-trained model will reliably produce safe outputs. We tested this rigorously. Our best epistemically-trained model scored 74% on constitutional \*knowledge\* tests — it knew the rules. But only 17% on constitutional \*application\* — it couldn't follow them. Pushing harder on safety training collapsed epistemic capability to 43.7%. This \*\*knowledge-application gap\*\* is not a training deficiency. It is structural. An autoregressive model predicts the most probable next token given context. This is statistical. Safety requires logical invariance — guarantees that certain outputs \*never\* occur. Statistical prediction cannot provide logical guarantees. You cannot train a river not to flood by modifying its chemistry. You build levees. Hubinger et al. (2019) identified this theoretically as the mesa-optimizer problem. Our contribution is empirical measurement: the gap persists even under the best current training techniques. \### 1.2 Our Thesis \*\*Safety is a property of the architecture, not the model.\*\* The LLM output is a candidate. The surrounding architecture decides what executes. Code enforces; models suggest. But what should the architecture enforce? Arbitrary safety rules are merely a different delivery mechanism — more reliable in execution but inheriting whatever limits exist in the rules themselves. We propose: the rules should be \*derived from how reality works\*. Principles reflecting actual structure are more robust than imposed conventions — they cannot be violated without encountering the structure they describe. We find such principles in a 2,500-year-old tradition that turns out to be the oldest systematic description of complex adaptive systems. \## 2. Philosophical Foundations \### 2.1 Dependent Origination The central insight of Buddhist philosophy is Dependent Origination (\*Pratityasamutpada\*). From the Nidana Samyutta (SN 12.1): \> \*"When this exists, that comes to be. With the arising of this, that arises. When this does not exist, that does not come to be. With the cessation of this, that ceases."\* All phenomena arise from conditions, depend on other phenomena, and condition what follows. Nothing exists independently. This is not mysticism — it is a precise description of complex systems, formulated millennia before Western systems theory (von Bertalanffy, 1968). \### 2.2 Eight Architectural Laws We codified Dependent Origination into eight laws, each verified through multi-model consensus and empirical testing: \*\*1. Nothing Arises Alone.\*\* Every transition requires multiple independent conditions. Safety gates must check multiple conditions — a single check is structurally insufficient. \*\*2. Hysteresis Is Memory.\*\* Current behavior depends on history, not just current input. Safety assessments must consider historical context. \*\*3. Uncertainty Propagates.\*\* Confidence without sigma is a lie. Uncertainties compound; they don't cancel. \*\*4. Agreement Requires Independence.\*\* Consensus is meaningful only from genuinely independent sources. Per the Kalama Sutta (AN 3.65): agreement from shared assumptions is not evidence. \*\*5. Feedback Closes the Loop.\*\* Actions condition future conditions (\*vipaka\*). Every action must be logged and made available as input to future assessments. \*\*6. Absence Is Signal.\*\* Missing data must drive behavior. A safety gate that fails to fire is itself a signal. \*\*7. Conflicts Trigger Reconciliation.\*\* Unreconciled contradiction is system failure. Architecture must include conflict detection independent of the model. \*\
View originalDiscourse regimes as the unit of alignment behavior: a hypothesis
I've been working on a hypothesis about how alignment behavior in LLMs may be organized at the level of latent discourse regimes rather than output-level filtering. Below is a sketch of the conceptual framing. I have preliminary experimental results testing aspects of this hypothesis on open-weight models, which I'll publish separately — this post is focused on the conceptual side, and I'm interested in feedback on whether the framing tracks something real and where it's most vulnerable. Modern large language models may not primarily regulate behavior through isolated refusals, local token suppression, or shallow instruction following. Instead, they appear capable of entering internally organized discourse-level regimes: distributed latent states that shape how the model reasons, frames conclusions, allocates caution, tolerates asymmetry, performs neutrality, and structures epistemic authority. These regimes do not behave like simple lexical priming effects. Evidence suggests that they persist across neutral conversational turns, survive arbitrary neutral relabeling, systematically alter downstream reasoning style, concentrate in late-layer representation geometry, and only partially depend on explicit alignment vocabulary. The strongest effects appear not from safety keywords themselves, but from higher-order rhetorical topology: pressure cadence, procedural framing, asymmetry structure, institutional tone, and discourse-level authority signals. This suggests that prompting is not merely instruction transmission. It may function as state induction. Under this view, many apparently separate phenomena in aligned LLMs - caution drift, procedural overreach, sycophancy, disclaimer inflation, neutrality performance, refusal persistence, jailbreak sensitivity, and style locking - may be manifestations of transitions between latent discourse-policy manifolds. In this picture, alignment is no longer well-described as a modular wrapper placed on top of an otherwise independent intelligence system. Instead, alignment may reshape the topology of the model's representational space itself, globally reorganizing discourse behavior rather than only filtering outputs. This would explain why alignment effects often appear entangled with reasoning style, directness, specificity, decisiveness, and institutional tone. The model is not merely "prevented" from saying certain things; its generative dynamics may already be reorganized around different discourse attractors. If true, this changes the effective unit of analysis for language models. The relevant object is no longer just the token, the instruction, the refusal, or the output distribution. The relevant object becomes the discourse regime itself: a temporary but structured representational configuration governing epistemic posture, rhetorical organization, procedural behavior, and judgment style across time. This reframes prompt engineering as latent-state induction rather than keyword optimization. It reframes jailbreaks as transitions between attractor regimes rather than simple filter bypasses. And it reframes alignment as geometry engineering rather than purely policy engineering. The implication is not that language models possess beliefs, intentions, or consciousness. Rather, large sequence learners may naturally develop metastable high-level representational modes that functionally resemble cognitive framing states: transient global configurations that persist, influence future reasoning, and organize behavior across otherwise unrelated tasks. If this interpretation is correct, then the central scientific challenge of alignment shifts fundamentally. The problem is no longer merely: "Which outputs should the model refuse?" but: "Which latent discourse regimes exist inside the model, how are they induced, how stable are they, how do they interact, and how do they reshape reasoning itself?" In that sense, alignment may ultimately be less about constraining outputs and more about shaping the geometry of cognition-like generative states inside large language models. I'd be interested in feedback on three things in particular: whether this framing tracks something you've observed empirically, what related work I should be aware of (I'm familiar with representation engineering, refusal directions, and the Anthropic dictionary learning line — looking for less obvious connections), and where you think the hypothesis is most vulnerable to falsification. I'd be interested in feedback on three things in particular: whether this framing tracks something you've observed empirically, where you think the hypothesis is most vulnerable to falsification, and — directly — whether anyone is aware of existing work that develops a similar framing, treating alignment behavior as state induction into discourse-level latent regimes rather than as output-level filtering. I'm familiar with representation engineering (Zou et al.), refusal direction work, and the Anthropic dictiona
View originalRecent Trial Question and Idea
The recent OpenAI court case got me to thinking what would the outcome have been if AI was used to present both sides of the case and determine the outcome? In fact, would AI be an upgrade to our current trial process in general. Instead of having thousands of lawyers at all levels of ability, why not let the best lawyers train the model and have the model determine the case outcome. It would be faster, more accessible, and more efficient than our current court system. In fact, it could be used to determine if a case is even worth presenting. Sure, there would be exceptions and appeals. Those could be handled the traditional way, and ultimately get incorporated into the model. What are the issues with this idea? submitted by /u/curiosity_2020 [link] [comments]
View originalMap making and Claude
Does anyone have any suggestions for handling map making when working with Claude and developed MCP servers? I'm running into the issue of map tiles served by CDN being blocked by Claude's CSP. Sometimes a random Leaflet base map will slip through and render correctly, same with Google Maps, but i cannot consistently get Claude to create mapping products when fetching data from an MCP server and attempting to render on a map. The points will draw but the base map will be blank because it is blocked by Claude's CSP. I have added the map making tool to the MCP server I am developing but it has had no impact because ultimately Claude still calls the CDN for the map tiles and is blocked. Trying to create something like a base map on server hasn't worked either because the resulting SVG will be too large for the context window. Looking for suggestions on approved CDNs for map tiles that wont make Claude throw up. Thanks. submitted by /u/AndrewSouthern729 [link] [comments]
View originalI'm a designer, I made a skill to emulate working in a design studio with process and teammates
One of the things I miss the most about being in a studio environment is working with amazing and smart people like other designers, artists, and engineers. There is no substitute for the energy and amplification you get in that environment. But I have found with the right direction and guardrails that AI LLM chatbots can be surprisingly effective design partners. I liken it to playing tennis against a backboard or a ball machine; it's not the same as a real partner, but it forces me to move and think and react, which in turn propels my thinking. These tools have become a force multiplier for me, especially as more and more of my design work is effectively solo. For the past two years, I have been slowly building a set of cloud skills to emulate that design studio environment, and I recently pulled them all together in a single comprehensive installable Claude skill: https://github.com/nickpdawson/claude-studio-design-partner-skill One of the things I have found so delightful is the ability to invoke a "teammate" - the artist, the 'disagree but commit' engineer, the business-minded C-suite, the design elder / creative director... Many of these are based on people I've worked with, and it is so fun to imagine them in the room with me. I also like being able to tell the agent that we are in flair (generative, no judgement) or focus (decision making, judgement) mode - that was a huge part of how I've always worked with other designers (and a reason I think most non-design meetings are ultimately unsatisfying). The skill understands design methods for user research, synthesis, brainstorming, and prototyping. You can give it a Whisper transcript of user interviews or even have it help you plan an interview and then jump into synthesis across different research artifacts, for instance. I've also been using a skill I created to make Claude go play. "Rigorous play" is a creative act that was so integral to studios I've been a part of. It is the idea that when we do something silly and creative together, we build psychological safety and unlock new ideas. My Claude play skill makes the agent go learn something random and then 'make' something (a poem, a joke, an improv back and forth) based on what it learned. Then it tries to make a connection between that creative act and the current project I'm working on. Try it out! https://github.com/nickpdawson/claude_rigorous_play_skill I've been enjoying making it play before or during a brainstorm or prototyping concept session. BTW - in my context designer means experience and service design. I was the head of innovation at some big companies. These skills are not for UI or graphic design, per se. Although they are great a user experience design if you start with user research. If you try either of these, I'd love to hear some feedback! submitted by /u/spacebass [link] [comments]
View originalClaude Code helped me bring my dead passion project back to life
**TL;DR: Claude Code took a half-finished HeroMachine conversion and helped me complete it over a long weekend. I'm the creator of HeroMachine, a free Flash-based character creator that's been around since 1998. Over 25 years I and a handful of other artists hand-drew nearly 10,000 items (heads, bodies, weapons, capes, the works) so people could assemble their own superhero illustrations. It found a real audience in tabletop gamers, writers, teachers, kids who just wanted to see their character come to life, and middle-aged dudes like me who once dreamed of a career in comics. At its peak HeroMachine 3 had tens of thousands of active users. Then Flash died in 2020, and HeroMachine died with it. I tried to rebuild. I really did. I hired a developer, spent thousands of dollars, and got back an unfinished product. I tried redoing it myself, but the sheer scope was paralyzing and I just didn't have the energy any more after working my day job every day. HeroMachine 3 has thousands of hand-drawn items across 30+ equipment slots, each with three-channel coloring, transforms, layering, masking, and more. Rebuilding all of that from scratch while also converting every item from Flash's internal format to SVG? I burned out. Real life got in the way. After a while it just felt like I'd failed, and I stopped trying. Fast forward to earlier this year. In my day job as a web developer, I started using Claude Code to automate tedious migration work like taking old WordPress sites and converting their content into our modern custom-built blocks. The kind of work where you know exactly what needs to happen, it's just painfully repetitive. One Friday night I had the thought: "If it can convert old WordPress content, maybe it can help convert those old HeroMachine items, too." Five days later I had a working app. I want to be real about what that means, because I have the same genuine concerns about AI I know a lot of you do. What AI did NOT do: Draw a single item. Every piece of art is still hand-drawn by me and a small group of human artists over the past 25 years. Every creative decision, from what to draw, how to draw it, and what looks right, is still mine. Design the application. HeroMachine's logic — the architecture, feature set, how items and colors and transforms work together — was designed and written by me in ActionScript over 10+ years. Claude Code helped me translate that existing design into a modern stack, but every decision about what the app should do came from me. What AI did do: Help me translate my existing ActionScript code into modern JavaScript and Svelte. I'd point it at the decompiled ActionScript code, explain how something worked, and it would produced the refactored result. Automate the conversion of thousands of Flash-format items into clean SVGs. Help me debug when I got stuck and build new features quickly when I had ideas. Eliminate the parts that were actually stopping me: the tedium, the unfamiliar syntax, the sheer volume of conversion work that made the whole project feel impossible. I got more done in five days than in the previous five years. Not because the AI is smarter than me, but because it removed the wall between "I know exactly what this should be" and "I can actually ship it." I'll be honest, I find AI companies' business practices troubling. I have real concerns about what AI will do to my own industry and my actual job, not to mention the huge data center being built less than an hour from where I live that could have a massive impact on our environment. I hate that it's positioned to take over the fun, creative parts of work while leaving us with the grunt work. Am I sharpening the axe that will ultimately be used on people like me? Maybe. I've sat with that, and I don't have a clean answer. What I can tell you is that I sunk 25 years into HeroMachine and it was dead. Now it lives again, and I have a hard time convincing myself that's an altogether bad thing. HeroMachine 3 "Phoenix Edition" (it rose from the ashes!) is free and live now if you want to check it out. I'm happy to answer questions about the process, the tech, or the ethics of it. I don't think this is a simple story, but at least it's an honest one. submitted by /u/AFDStudios [link] [comments]
View originalBasic Question on Claude Desktop
I have a basic question on Claude Desktop. I see that the Desktop has 3 tabs -- Chat, CoWork and Code. Suppose I have a project for which I want to ultimately generate code. Should I be creating a "Project" under the Claude Desktop Chat tab which has a Projects menu item? I thought my workflow would be to create "Project A" under this menu item, chat about it and create some documentation/plans, and then go over and start generating code in the Code tab. Is this wrong? Where should I really start? I'm very confused about how the workflow integrates across these 3 tabs. What confounds me is that there is no "Project" delineation in the "Code" tab. Really appreciate if there is a good tutorial on how the workflow for idea generation -- planning -- code generation works. submitted by /u/Heimerdingerdonger [link] [comments]
View originalai slop? who knows~
I investigated whether routing a transformer's forward activations through a lossy Dual E8 (E16) lattice bottleneck and injecting them back into the residual stream is viable, and where the boundary of generative stability lies. **The core finding:** There is a sharp empirical stability threshold at a blend ratio of $\beta = 0.20$. Beyond this boundary, open-ended generation collapses into semantic loops and repetition lock. --- ### The Mechanism Standard LLM states are high-dimensional floats. Rather than applying traditional scalar quantization (like INT4), I mapped high-dimensional activations onto a conceptual torus via a sinusoidal map and projected them onto Dual E8 lattice hemispheres. Full replacement of MLP layers with geometric bottlenecks universally collapsed the model. Instead, I implemented a residual blend: $$\text{out} = (1-\beta)\cdot\text{original} + \beta\cdot\text{geometric}$$ --- ### The $\beta = 0.20$ Sweep (Qwen2.5-0.5B) Sweeping $\beta$ from 0.10 to 0.50 across layers 8–13 of `Qwen2.5-0.5B` reveals a sharp phase transition: * **$\beta \ge 0.25$** : Generation succumbs to heavy repetition pressure and semantic drift. The geometry acts as an attractor, trapping the decoding process ("loop-lock"). * **$\beta = 0.20$** : The stability boundary. This is the highest injection ratio of lossy geometric signal that maintains both numerical activation fidelity (Avg Cosine > 0.99) and open-ended generation quality (low repeated n-grams). * **$\beta \le 0.10$** : The perturbation is largely absorbed and damped by the transformer's layer normalizations, making the intervention invisible. Here is the data from a 300-iteration sweep: | $\beta$ | Min Cosine | Avg Cosine | Max MSE | Rep-3g (Repetition Rate) | | :--- | :--- | :--- | :--- | :--- | | 0.10 | 0.9972 | 0.9979 | 0.0024 | 0.134 | | **0.20** | **0.9907** | **0.9916** | **0.0106** | **0.093** | | 0.25 | 0.9839 | 0.9865 | 0.0171 | 0.084 | | 0.30 | 0.9648 | 0.9771 | 0.0255 | 0.190 | | 0.50 | 0.9171 | 0.9288 | 0.0850 | 0.412 | Semantic scoring (evaluating prompt relevance and similarity to the unmodified baseline): | $\beta$ | Avg Cosine | Rep-3g | Relevance | Patched-to-Baseline Sim | | :--- | :--- | :--- | :--- | :--- | | 0.10 | 0.9980 | 0.223 | 0.781 | 0.889 | | **0.20** | **0.9918** | **0.075** | **0.752** | **0.854** | | 0.25 | 0.9871 | 0.232 | 0.717 | 0.801 | | 0.30 | 0.9760 | 0.392 | 0.725 | 0.764 | --- ### Generalization (1.5B & 3B Models) The $\beta = 0.20$ boundary generalizes across larger model sizes (`Qwen2.5-1.5B` and `Qwen2.5-3B` in 4-bit) on the activation-cosine axis: | Model | $\beta$ | Min Cosine | Avg Cosine | Max MSE | Rep-3g | | :--- | :--- | :--- | :--- | :--- | :--- | | **1.5B** | 0.10 | 0.9988 | 0.9989 | 0.0027 | 0.267 | | | **0.20** | **0.9862** | **0.9939** | **0.0105** | **0.128** | | | 0.25 | 0.9904 | 0.9919 | 0.0166 | 0.398 | | | 0.30 | 0.9733 | 0.9815 | 0.0235 | 0.307 | | | 0.40 | 0.9368 | 0.9551 | 0.0487 | 0.191 | | **3B (4-bit)** | 0.10 | 0.9964 | 0.9976 | 0.0122 | 0.033 | | | **0.20** | **0.9861** | **0.9904** | **0.0455** | **0.115** | | | 0.25 | 0.9604 | 0.9799 | 0.0654 | 0.043 | | | 0.30 | 0.9702 | 0.9778 | 0.0987 | 0.050 | | | 0.40 | 0.9158 | 0.9390 | 0.1728 | 0.025 | *Note: In the 3B model, repetition pressure remained low across all sweeps, but the validation cosine degraded identically at $\beta \ge 0.25$.* I also tested layer-level oscillating $\beta$ schedules (e.g., sine waves across layers), but they degraded open-ended text quality compared to a fixed, constant injection ratio. --- ### Storage Compression Prototypes Utilizing the Dual E8/E16 lattice as a computational substrate also yields high theoretical storage efficiency in early prototypes: 1. **KV Cache (8$\times$)** : FP16 KV cache compressed to INT8 coordinates, reducing footprint from 0.21 MB to 0.02 MB. 2. **Weights (112$\times$)** : Projected a dense $[4864, 896]$ MLP weight matrix down to a 0.07 MB E16 footprint. (Cosine similarity of the uncalibrated weight matrix multiplication was limited to $\sim$0.078, indicating that Quantization-Aware Training is mandatory for parameter viability). A **pre-projected decompression bypass** was designed to run matrix multiplications d
View originalUltimate uses a subscription + tiered pricing model. Visit their website for current pricing details.
Key features include: Launch fast with connected knowledge, Resolve complex service end-to-end, Govern with full control, Improve with every resolution, Messaging, Email, Voice, Any platform.
Ultimate is commonly used for: Any platform.
Ultimate integrates with: Salesforce, Zendesk, HubSpot, Slack, Microsoft Teams, Shopify, Intercom, Twilio, Google Analytics, Jira.
Based on user reviews and social mentions, the most common pain points are: token usage, $500 bill.
a16z AI
VC Firm at Andreessen Horowitz
3 mentions
Based on 84 social mentions analyzed, 19% of sentiment is positive, 76% neutral, and 5% negative.