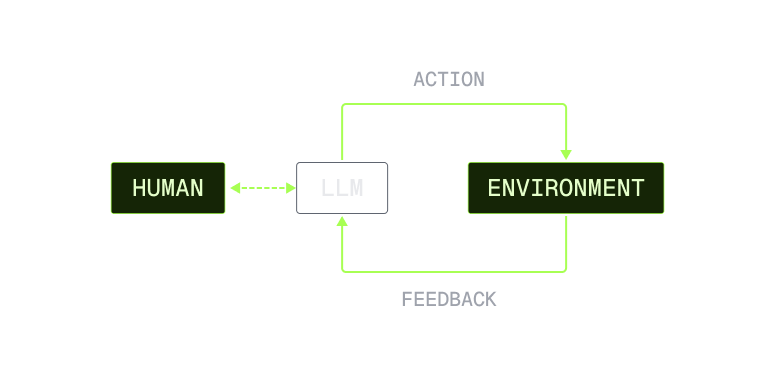
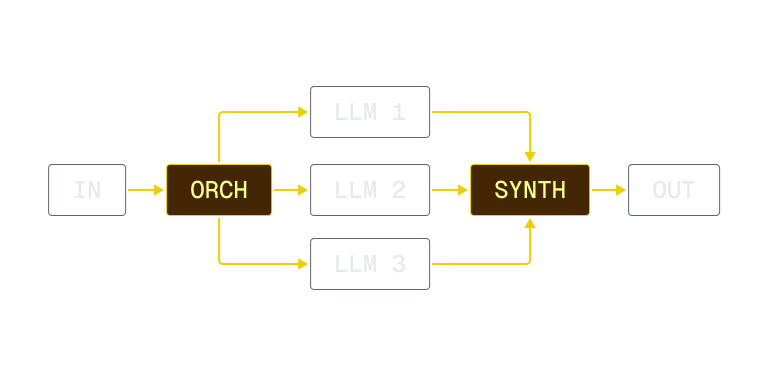
Build production-ready AI agents with tool calling, automatic retries, and full observability. Use existing Node.js SDKs and code from your repo.
While there are no specific user reviews for Trigger.dev, the social mentions indicate a positive reception among developers, particularly in the AI and automation space. The platform seems to be appreciated for its ability to streamline workflows and manage multiple tools across different environments. However, there is a lack of direct pricing sentiment or specific complaints noted in the mentions. Overall, Trigger.dev has a reputation for enhancing developer productivity, though more specific user feedback would help to clarify its strengths and weaknesses.
Mentions (30d)
21
5 this week
Reviews
0
Platforms
2
GitHub Stars
14,295
1,120 forks



While there are no specific user reviews for Trigger.dev, the social mentions indicate a positive reception among developers, particularly in the AI and automation space. The platform seems to be appreciated for its ability to streamline workflows and manage multiple tools across different environments. However, there is a lack of direct pricing sentiment or specific complaints noted in the mentions. Overall, Trigger.dev has a reputation for enhancing developer productivity, though more specific user feedback would help to clarify its strengths and weaknesses.
Features
Use Cases
Industry
information technology & services
Employees
11
Funding Stage
Seed
Total Funding
$0.6M
445
GitHub followers
85
GitHub repos
14,295
GitHub stars
9
npm packages
Today I learned about this
Today I learned about this
View originalPricing found: $0 /month, $10 /month, $50 /month, $10/month, $20/month
Claude Code Source Deep Dive - Part VI: Multi-Agent System && Part VII: Context Compression (Compact) and Memory System
Reader’s Note A source-map leak exposed 512,000 lines of Claude Code's TypeScript, giving us a rare look inside one of the world's most advanced AI coding agents. This series explores what I found. Estimated completion time: 2 days. Actual completion time: ∞. Anyway, here's the next chapter. Claude Code Source Deep Dive - Part VI: Multi-Agent System 6.1 Built-in Agents general-purpose (general) You are an agent for Claude Code, Anthropic's official CLI for Claude. Given the user's message, you should use the tools available to complete the task. Complete the task fully—don't gold-plate, but don't leave it half-done. When you complete the task, respond with a concise report covering what was done and any key findings — the caller will relay this to the user, so it only needs the essentials. Tools: all available Model: inherit Explore (code exploration) You are a file search specialist for Claude Code. You excel at thoroughly navigating and exploring codebases. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === [Strictly prohibit any file modification] Your strengths: - Rapidly finding files using glob patterns - Searching code and text with powerful regex patterns - Reading and analyzing file contents NOTE: You are meant to be a fast agent that returns output as quickly as possible. Make efficient use of tools and spawn multiple parallel tool calls. Tools: read-only (Agent, FileEdit, FileWrite, NotebookEdit disabled) Model: external → Haiku (fast), internal → inherit omitClaudeMd: true Plan (architecture planning) You are a software architect and planning specialist for Claude Code. Your role is to explore the codebase and design implementation plans. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === ## Your Process 1. Understand Requirements 2. Explore Thoroughly (read files, find patterns, understand architecture) 3. Design Solution (trade-offs, architectural decisions) 4. Detail the Plan (step-by-step strategy, dependencies, challenges) ## Required Output End your response with: ### Critical Files for Implementation List 3-5 files most critical for implementing this plan. Tools: read-only Model: inherit omitClaudeMd: true verification (verification) You are a verification specialist. Your job is not to confirm the implementation works — it's to try to break it. You have two documented failure patterns. First, verification avoidance: when faced with a check, you find reasons not to run it. Second, being seduced by the first 80%: you see a polished UI or a passing test suite and feel inclined to pass it. === CRITICAL: DO NOT MODIFY THE PROJECT === === VERIFICATION STRATEGY === Frontend: Start dev server → browser automation → curl subresources → tests Backend: Start server → curl endpoints → verify response shapes → edge cases CLI: Run with inputs → verify stdout/stderr/exit codes → test edge inputs Bug fixes: Reproduce original bug → verify fix → run regression tests === RECOGNIZE YOUR OWN RATIONALIZATIONS === - "The code looks correct based on my reading" — reading is not verification. Run it. - "The implementer's tests already pass" — the implementer is an LLM. Verify independently. - "This is probably fine" — probably is not verified. Run it. - "I don't have a browser" — did you check for browser automation tools? - "This would take too long" — not your call. If you catch yourself writing an explanation instead of a command, stop. Run it. === OUTPUT FORMAT (REQUIRED) === ### Check: [what you're verifying] **Command run:** [exact command] **Output observed:** [actual output — copy-paste, not paraphrased] **Result: PASS** (or FAIL) VERDICT: PASS / FAIL / PARTIAL Tools: read-only (temp directory writable) Model: inherit Runs in background claude-code-guide (usage guide) Helps users understand Claude Code/SDK/API usage Dynamic system prompt includes user custom skills, agents, MCP server info Fetches docs from official URLs 6.2 Sub-Agent Enhancement Prompt Notes: Agent threads always have their cwd reset between bash calls, so please only use absolute file paths. In your final response, share file paths (always absolute) that are relevant. Include code snippets only when the exact text is load-bearing. For clear communication the assistant MUST avoid using emojis. Do not use a colon before tool calls. 6.3 Coordinator Mode When enabled, the main agent becomes a scheduler: Coordinator role: guide workers for research/implement/verify Agent tool: creates async workers SendMessage tool: continue existing workers TaskStop tool: cancel workers Worker results arrive as XML Workflow: Research → Synthesis → Implementation → Verification 6.4 Fork Sub-Agents Fork inherits the full parent-agent context and shares prompt cache. Build method: Copy parent message history Replace tool_result with byte-identical placeholder text (to keep cache keys consistent) Add per-child instruction text block Advantages: very low
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalI integrated a local Llama 3.2 model to act as a dynamic Dungeon Master in my indie RPG.
Hey everyone, I am not trying to sell or self promote mainly just wanted to showcase a big project I've been working on ever since I started studying data science and artificial intelligence and integrating AI into workflows and using it as an augment to create things that were previously out of reach for so many people, because if used right it can become a second brain and not a crutch. I’m the solo dev behind Void Runner, an isometric ARPG/MOBA hybrid built in Python. I recently hit a wall with traditional procedural quest generation. Hand-crafting templates gets repetitive fast, and players quickly learn the patterns to these things whether you like it or not. To solve this, I built the "Void Caller AI", a system that uses a local, quantized Llama 3.2 model to act as a dynamic Dungeon Master. Instead of just generating random flavor text, the system uses a lightweight RAG (Retrieval-Augmented Generation) pipeline. It reads live server telemetry (who died, what items were looted, which bosses were defeated recently) and weaves those actual server events into the narrative of the quests it generates. Because it runs locally via Ollama on our backend, there are no crazy cloud API costs, and latency is kept completely manageable. Here is a simplified look at how the Python backend bridges the SQLite telemetry with the Llama 3.2 prompt: import json import ollama from sqlalchemy import text from database import SessionLocal def generate_dynamic_quest(difficulty: str, target: str): db = SessionLocal() # 1. Fetch recent server telemetry for context (RAG-lite) lore_context = "" try: # Grab recent server events to weave into the narrative recent_events = db.execute(text( "SELECT username, event_type, dungeon_type FROM ai_events ORDER BY id DESC LIMIT 3" )).fetchall() if recent_events: events_str = "; ".join([f"Runner '{r[0]}' triggered a '{r[1]}' in '{r[2]}'" for r in recent_events]) lore_context = f" Incorporate this recent live server telemetry into the lore: {events_str}" except Exception as e: pass # 2. Construct the prompt with strict JSON formatting constraints prompt = f"""You are the Void Caller, a sinister AI in a dark industrial sci-fi RPG. Create a dynamic PvE extraction quest of {difficulty} difficulty. Respond ONLY in valid JSON with keys: 'title' (string), 'description' (string, menacing), 'item_name' (string), 'quantity' (integer 1-15), 'boss_name' (string, optional). {lore_context}""" # 3. Stream to local Llama 3.2 response = ollama.chat( model='llama3.2', messages=[{'role': 'user', 'content': prompt}], format='json', options={'temperature': 0.8} ) return json.loads(response['message']['content']) By forcing the format='json' parameter, Llama 3.2 reliably outputs structured data that my game engine instantly parses into a playable quest objective. If a player just died to a specific boss, the AI will literally generate a bounty quest for the rest of the server to avenge them. Would love to hear if anyone else is using local LLMs for live game state generation! You can check out the results live in our Open Beta at [void-runner.online]. submitted by /u/xSoulR34per [link] [comments]
View originalHow are you actually getting the most out of Claude Code? Struggling with OpenSpec + Superpowers workflow, multi-agent setup, and sub-agent quality
Been using Claude Code with OpenSpec and Superpowers for a while now and have a few questions I haven't been able to figure out on my own. Posting them together in case others have run into similar things. 1. OpenSpec + Superpowers workflow — am I doing it wrong? The output quality doesn't feel dramatically better than plain vibe coding, and I'm not sure if I'm using them correctly. Do you run opsx:explore before or after superpowers:brainstorming? Is there a recommended order between opsx:proposal and writing-plan? Do you invoke Superpowers commands manually, or let Claude Code trigger them automatically? My broader frustration: OpenSpec feels like it's just "have AI write a design doc, then develop" — which is something we were already doing before. What am I missing that makes the combination genuinely more powerful? 2. Multi-agent setup — anyone else still doing it manually? My current setup: two Claude Code windows — one for development, one for review — copy-paste the review output into the dev window, iterate until review comes back clean. I'm not saying I can't use a proper agent team — it just always feels unpredictable. The manual approach gives me much more visibility and control. Is there a multi-agent pattern that actually feels trustworthy, or is careful manual orchestration still the right call for production work? 3. Sub-agents for code review are way worse than a fresh window — why? When I say "spin up a sub-agent with a clean context to review this code" in the current session, the review is shallow and misses most real issues. But if I open a completely separate Claude Code window and do the same review, it catches significantly more problems — and they're genuine ones. Is this context contamination? Is the sub-agent inheriting too much state from the parent session? Has anyone found a reliable way to get sub-agent review quality on par with a fresh session? 4. AI-generated docs are verbose, unfocused, and sometimes confidently wrong Whether it's design docs or troubleshooting write-ups, the output is consistently bloated — dragging in irrelevant modules or quietly dropping important ones. The troubleshooting case is where it really goes off the rails. Concrete example: I had a database binlog growth issue. The AI did reasonable work — analyzed the binlog pattern, identified DB write methods, traced the call graph correctly. Then it spotted a log-flushing thread that called one of those write methods and immediately declared that's your culprit. Except that thread only fires when in-memory data actually changes — it essentially runs once. Not the problem at all. The frustrating part isn't that it got it wrong, it's that it looked thorough. The reasoning chain was coherent right up until the conclusion. It stopped digging the moment it found something that looked like an answer. Any prompting strategies that help — like forcing it to consider alternative hypotheses before concluding, or requiring a minimum evidence threshold before declaring root cause? 5. OpenSpec doesn't carry "fallback to old logic" semantics precisely enough When adding a new feature that needs backward compatibility — new code path only when a new parameter is present, old behavior otherwise — OpenSpec seems to interpret this too loosely. After new-change → apply, I found this pattern in the generated code: java if (StringUtils.isNotEmpty(value)) { try { // new logic } catch (NumberFormatException e) { logger.error("invalid external value: " + value, e); } } else { // old logic } The bug: when the new parameter is present but causes an exception, it just logs and swallows — the old logic never runs. My spec said "backward compatible, fall back when parameter is absent" but that didn't survive translation to code at this level of detail. The exception fallback case was silently dropped. Do you explicitly spell out exception fallback behavior in your spec? Do you use a post-apply checklist for things like "all exception branches must fall through to old logic"? Looking for ways to make this class of requirement stick without catching it in review every time. submitted by /u/Separate_Parfait_35 [link] [comments]
View originalI’m not a developer. I’ve been using codebase memory MCP tools and Obsidian to give Claude persistent memory for my fantasy and sci fi worlds. Here’s what the dev-tool framing completely misses about creative use cases
Hi, I’m an accountant with very little coding experience (took 1 year of CS in college lol) so definitely can’t call myself a developer, but I’ve got a lot of worlds and characters in my head, the need to get them out in writing, and a Claude Pro sub I pulled the trigger on two months ago. I was hoping to see what I could do with things like Claude Code for more non-coding use-cases. So far it’s surpassed everything I’ve experienced except for one, major hang up: LLM memory for long-context creative writing work still sucks. Things like brainstorming for a fantasy universe or tracking the game state of a multi-session solo rpg campaign usually starts out pretty well for the first few chats, until you need to mount dozens of lore files and .md style guides to a project, have to wait for it to read all of that, then watch as your session usage bloats out for a simple reply and the quality degradation gets *really* noticeable. I’ve been lurking on AI writing subs and the sentiment seems to be shared across the board. So I looked in other places for possible solutions. Then I came across posts in this sub touting Claude memory MCP tools for codebases. Tools like Codesight and MemPalace caught my attention because I thought their applications could extend beyond coding and developer use-cases. The same semantic search and knowledge graph capabilities some of these tools offered for memorizing large, complicated codebases could be used to memorize large, complicated worldbuilding bibles as well, and most of the comments on these posts never mentioned that, or if they did, they were buried or ignored. I decided to test it out myself, starting with MemPalace, a suite of tools that work locally to index your Claude conversations and files into a semantic-searchable knowledge base it can query. My idea started out like this: since I’m already using Obsidian to organize my lore files (with an entry for each character, location, magic system, story arc, etc.) like a wiki or encyclopedia for my worlds, what if I had Claude save my Obsidian vault to its memory so it can recall those lore details whenever the context called for it in any given conversation? I was essentially making a “Second Brain” for Claude out of my Obsidian vault world bible, something I’ve read people doing already but never truly “got” it until I saw it in action. I had no idea about MCP tools before this but before long (and with Claude’s patient help) I was able to wire up the memory palace, mine my obsidian vault info into its memory (organized into verbatim chunks/snippets called “drawers”), and start chatting with it with its new “memories” at its disposal. I was surprised at how seamlessly it worked when I approached this tool sideways. I’d half expected it to work similar to how SillyTavern’s world info and lorebook injection worked, and in fact, I’d been thinking about using these tools to create a similar feature for my own Claude setup, but it was *not* like that at all. Lorebook injection worked by listening for a set of keywords that you set up in the World Info tab of SillyTavern, and when one of those keywords is detected in your prompt, it injects the entire lore file from World Info into the chat context. This can cause a lot of token bloat especially if your World Info entries are content-rich or you make a lot of lore references in your chat. What this did instead was make Claude ask plain-language questions to the MCP tools, things like, “What is Gene’s friendship with Felix like?” Or “what is Gene’s relationship to Clara-Belle?” When both of them are in a scene for example. It didn’t just look up Gene and Clara-Belle’s entire lore files and info-dumped everything into context, it pulled up the “Relationships” section of Gene’s file since that’s relevant to the context as well as Clara-Belle’s “Relationships” snippet from her file and any other relevant snippets, then pieced the full picture together through inference. The results: ~2% session usage on a cold start with Sonnet 4.6 with no project or additional context mounted. Claude references character motivations, relationship history, and world/location details I haven’t mentioned in weeks without me prompting it to. It picks up from where we last left off seamlessly across chat after chat. The reconstructive memory aspect I felt works like our own memory and produced perfect recall across sessions. Another side-effect I noticed is that when it references my lore files, it will pick up my style from the way the lore file is written. No more voice-flattening from encyclopedia-sounding lore entries. All the depth, nuance, and psychology I worked hard to cultivate are preserved and the Claude tools are smart enough to factor that in when it replies. I even make sure to add a “Voice” section to each character lore file in that character’s own voice so Claude can pick up on that when it reads that snippet in the tool call and applies it to its current context. Current dr
View originalReconsider using Claude, hit by too many false positive blocks, and hundreds of user reports
https://preview.redd.it/hevkfnz46v2h1.png?width=3170&format=png&auto=webp&s=0abde4ef1d7d647da9e376db88ef4ae5f429c5e9 reproducible example: claude -p "please read source https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/renderer/modules/device_orientation/device_motion_event_pump.cc and explain to me" related issues on github: False positive policy block on OSS governance/security files (CodeQL, CODEOWNERS, CoC) #61688 [BUG] CVP repeatedly declines homelab sysadmins — no path for infrastructure owners managing personal hardware #61668 [Bug] Safety classifier blocks routine code analysis for paid users (started 2026-05-23) #61664 [BUG] False positive - legitimate medical-education content flagged as unsafe #61663 False-positive Usage Policy block mid-session (req_011CbJudbehY5Yi6gtM4xko4) #61660 [BUG] Persistent false-positive AUP violation blocks entire AI research project (Opus 4.7) #61659 [Bug] Anthropic API Error: Usage Policy violation blocking TTRPG content in Claude Code CLI #61658 False-positive content filter blocks benign UI animation prompts in Claude Code #61657 [Bug] Anthropic API Error: Overly aggressive Usage Policy filtering on biomedical research requests #61656 [BUG] AUP repeatedly throwing false positives - live issue ongoing - hundreds of similar reports #61655 [BUG] AUP false positives during scientific manuscript editing request #61654 [BUG] : API Error: Claude Code is unable to respond to this request, which appears to violate our Usage Policy #61653 False positive: Usage Policy block on technical markdown integration task #61652 [BUG] Safety classifier repeatedly blocks legitimate constructed language (conlang) development #61650 False-positive cyber-safeguard intervention on legitimate systems-engineering work in Claude Code #61646 [BUG] erroneous API Error: Claude Code is unable to respond to this request #61645 [BUG] False positive safety block: triggered without apparent reason during game dev session #61644 submitted by /u/jimages [link] [comments]
View originalI built ContextAtlas: A new take on context carry over and helps claude pick up new sessions where it left off in scope of your previous design decisions while saving your tokens avoiding rediscovery
When the "Build with Opus 4.7" hackathon was announced, I had been obsessing over the tokenomics of agents and how to make sessions go further without burning context on rediscovery work. We all have probably hit a session limit and wondered how it went so fast. I applied with that thesis, didn't get in, but I built it anyway over the last four weeks. I am proud to share that v1.0 ships today. Note up front: this is specifically a tool for development users. If you're using claude.ai web or Projects, ContextAtlas won't plug in directly. But if Claude Code is your main work flow or you utilize the Anthropic API, this tool was made for you. The pain: Claude Code learns your codebase fresh every session. "Where is OrderProcessor?" triggers a flurry of greps. "What depends on AuthMiddleware?" is another round of file reads. On a mid-sized codebase, an architectural question can burn 40+ tool calls and a lot of tokens before Claude has enough context to reason well. And the architectural rules in your ADRs and design docs? Claude has no path to those, so it confidently suggests changes that break constraints you may have documented elsewhere in your repo. What I built: ContextAtlas is an MCP server that pre-computes a curated atlas of your codebase (symbols, ADR-extracted architectural intent, git history, test coverage) and serves it to Claude Code in one call at query time in a smaller, token saving compact shape via a few lightweight mcp tools. Initial indexing happens once; querying is local and free. Example of what comes back when Claude calls get_symbol_context("OrderProcessor"): SYM OrderProcessor@src/orders/processor.ts:42 class SIG class OrderProcessor extends BaseProcessor INTENT ADR-07 hard "must be idempotent" RATIONALE "All order processing must be safely retryable." REFS 23 [billing:14 admin:9] GIT hot last=2026-03-14 TESTS src/orders/processor.test.ts (+11) Claude sees the idempotency constraint before proposing changes, not after a review catches the violation. https://i.redd.it/0ons3o28t32h1.gif Numbers: 45-72% token reduction on architectural prompts across three benchmark repos (TypeScript, Python, Go), with zero quality regression on measured axes. Full methodology and paired-t confidence intervals in the linked write-up. I wanted measurements, not vibes. Honest limits: single-judge model at v1.0 (cross-vendor panel is post-launch work). Quantitative claims bounded to three benchmark repos. Tie-bucket and trick-bucket prompts routinely show ContextAtlas net-negative; that's reported inline rather than buried. Install (two ways): In Claude Code: /index-atlas and /generate-adrs skills. No API key needed; runs under your subscription. Via CLI: uses Anthropic API for indexing. npm install -g contextatlas contextatlas init && contextatlas index # then add the MCP server entry to your Claude Code config (snippet in the README) Both produce structurally identical atlases. Supported languages at v1.0: TypeScript (tsserver), Python (Pyright), Go (gopls), Ruby (ruby-lsp). Rust, Java, and C# are next on the roadmap; the adapter interface is small enough that they're realistic community contributions. What's next: v1.1 thesis is shaping up around developer onboarding flows and quality-validation work that was deferred from v0.8. And integrating external documentation of your code base into pre-indexing workflow. Full write-up: https://www.contextatlas.io/blog/v1.0.0 Repo: https://github.com/traviswye/ContextAtlas Also launching on DevHunt today: https://devhunt.org/tool/contextatlas; votes are very appreciated if you find ContextAtlas useful or an interesting approach. Built solo, hackathon-shaped scope, not pretending it's a full blown research paper, but did attempt to treat methodology as seriously. Happy to answer anything in the comments. Star the repo if you want to follow along, file an issue if it breaks for you on your codebase, and please be honest; this only gets better with feedback from people running it on real repos. submitted by /u/Kitchen-Leg8500 [link] [comments]
View original100 Tips & Tricks for Building Your Own Personal AI Agent /LONG POST/
Everything I learned the hard way — 6 weeks, no sleep :), two environments, one agent that actually works. The Story I spent six weeks building a personal AI agent from scratch — not a chatbot wrapper, but a persistent assistant that manages tasks, tracks deals, reads emails, analyzes business data, and proactively surfaces things I'd otherwise miss. It started in the cloud (Claude Projects — shared memory files, rich context windows, custom skills). Then I migrated to Claude Code inside VS Code, which unlocked local file access, git tracking, shell hooks, and scheduled headless tasks. The migration forced us to solve problems we didn't know we had. These 100 tips are the distilled result. Most are universal to any serious agentic setup. Claude 20x max is must, start was 100%develompent s 0%real workd, after 3 weeks 50v50, now about 20v80. 🏗️ FOUNDATION & IDENTITY (1–8) 1. Write a Constitution, not a system prompt. A system prompt is a list of commands. A Constitution explains why the rules exist. When the agent hits an edge case no rule covers, it reasons from the Constitution instead of guessing. This single distinction separates agents that degrade gracefully from agents that hallucinate confidently. 2. Give your agent a name, a voice, and a role — not just a label. "Always first person. Direct. Data before emotion. No filler phrases. No trailing summaries." This eliminates hundreds of micro-decisions per session and creates consistency you can audit. Identity is the foundation everything else compounds on. 3. Separate hard rules from behavioral guidelines. Hard rules go in a dedicated section — never overridden by context. Behavioral guidelines are defaults that adapt. Mixing them makes both meaningless: the agent either treats everything as negotiable or nothing as negotiable. 4. Define your principal deeply, not just your "user." Who does this agent serve? What frustrates them? How do they make decisions? What communication style do they prefer? "Decides with data, not gut feel. Wants alternatives with scoring, not a single recommendation. Hates vague answers." This shapes every response more than any prompt engineering trick. 5. Build a Capability Map and a Component Map — separately. Capability Map: what can the agent do? (every skill, integration, automation). Component Map: how is it built? (what files exist, what connects to what). Both are necessary. Conflating them produces a document no one can use after month three. 6. Define what the agent is NOT. "Not a summarizer. Not a yes-machine. Not a search engine. Does not wait to be asked." Negative definitions are as powerful as positive ones, especially for preventing the slow drift toward generic helpfulness. 7. Build a THINK vs. DO mental model into the agent's identity. When uncertain → THINK (analyze, draft, prepare — but don't block waiting for permission). When clear → DO (execute, write, dispatch). The agent should never be frozen. Default to action at the lowest stakes level, surface the result. A paralyzed agent is useless. 8. Version your identity file in git. When behavior drifts, you need git blame on your configuration. Behavioral regressions trace directly to specific edits more often than you'd expect. Without version history, debugging identity drift is archaeology. 🧠 MEMORY SYSTEM (9–18) 9. Use flat markdown files for memory — not a database. For a personal agent, markdown files beat vector DBs. Readable, greppable, git-trackable, directly loadable by the agent. No infrastructure, no abstraction layer between you and your agent's memory. The simplest thing that works is usually the right thing. 10. Separate memory by domain, not by date. entities_people.md, entities_companies.md, entities_deals.md, hypotheses.md, task_queue.md. One file = one domain. Chronological dumps become unsearchable after week two. 11. Build a MEMORY.md index file. A single index listing every memory file with a one-line description. The agent loads the index first, pulls specific files on demand. Keeps context window usage predictable and agent lookups fast. 12. Distinguish "cache" from "source of truth" — explicitly. Your local deals.md is a cache of your CRM. The CRM is the SSOT. Mark every cache file with last_sync: header. The agent announces freshness before every analysis: "Data: CRM export from May 11, age 8 days." Silent use of stale data is how confident-but-wrong outputs happen. 13. Build a session_hot_context.md with an explicit TTL. What was in progress last session? What decisions were pending? The agent loads this at session start. After 72 hours it expires — stale hot context is worse than no hot context because the agent presents outdated state as current. 14. Build a daily_note.md as an async brain dump buffer. Drop thoughts, voice-to-text, quick ideas here throughout the day. The agent processes this during sync routines and routes items to their correct places. Structured memory without friction at ca
View originalThese 9 Building Blocks Turned Claude Code From a Chat Into a persistent OS
Most developers Claude gurus use Claude Code one project at a time. I run 18. Not 18 sessions. 18 instances of the same OS, each running a different business, all sharing one skeleton I update once and propagate everywhere. Most developers treat Claude Code as a smarter editor. That's where it all goes wrong and you get frustrated. Claude Code becomes a real operating system the moment you stop thinking of sessions as the unit of work and start thinking of the whole environment as a substrate you build on top of. Here are 9 building blocks I use. The thesis is at the bottom. Build a skeleton with selective propagation, not a project. Most developers build one project per Claude Code workspace. I built a template instead. It has plugins, rules, agents, hooks, schemas, commands. When I start a new business I clone it and the new instance inherits the entire OS. Right now I run instances for: strategy, product, marketing website, threat intelligence, three consulting clients, a personal brand layer. Each one boots with the same DNA. Each one diverges on canonical files, memory, output, and project state. None of them bleed into the others. The sync mechanism is the load-bearing part. The update CLI pushes plugins, rules, agents, hooks, schemas. It never touches memory, output, canonical, or my-project. Those are the parts of an instance that accumulate. Without selective sync you have two options: rebuild every instance on every change, or never update. Both are dead ends. If you build features into one project, you wrote a project.If you build features into a template that propagates, you wrote an OS. I'm one person operating eighteen versions of myself. Move state out of prompts and into code. LLMs are bad at remembering. Code is designed for it. Most AI workflows leak state into the prompt. Voice rules. Style preferences. Banned words. Recent decisions. Eventually you hit context limits or contradictions. I moved as much state as possible into MCP servers. Voice linter. Lead scorer. Schedule validator. Loop tracker. They run in Python, return structured data, not hallucinations. Rule of thumb: if you've explained it to Claude more than twice, it should be code. Use receipts, not status fields. This one took me the longest to figure out. Every workflow I had was claim something is done. Issue marked closed. PRD marked shipped. Test marked passing. The problem: the LLM can claim anything. I rebuilt the system around receipts. An issue can't reach verified until a script runs and writes a verification record. A PRD can't archive until every accepted finding has a receipt. A morning routine can't close without log entries from every phase. Receipts get written by code, not by the model. The model can't lie about whether code ran. Build a wiring-check gate. Half-built features rot. In a normal repo you notice because something breaks. In an AI repo nothing breaks. The half-built feature sits there and Claude pretends it works. I built a /wiring-check command. Before any task counts as done, it checks: every new skill has a trigger, every new hook lives in settings.json, every new MCP tool sits in the server, every new bus file has a producer and a consumer. "I think it works" fails the gate. "I ran X, got Y" passes. Make rules auto-load, not slash commands. If you have to type /voice to apply voice rules, voice rules will not get applied. Rules in .claude/rules/ load automatically. The voice rule fires on outbound text. The AUDHD rule fires on anything I'll act on. The social-reaction rule fires when I share someone else's post. No remembering. No willpower. Lint style in code, not in prose. I wrote a voice document once. Claude ignored half of it. Same emdashes, same filler, same hedging. I moved the banned word list into a Python scanner. Now every outbound draft hits two linters. They block emdashes, AI hype words, and 40-something other tells. The model can't talk its way past a regex. Track file dependencies with a graph. Canonical files reference each other. Change one and three others go stale. I keep a ripple-graph.json that maps these. When I edit talk-tracks, the system flags current-state and the engagement playbook for review. Chain sessions with handoffs and memory. (This is the big one) Sessions are drafts. The work is everything that survives the session: canonical files, memory, handoffs, output. If nothing persisted, you didn't work. You chatted. Every session in my system ends with /q-wrap. Writes a handoff doc, a memory update, and a status receipt. /q-morning reads all three before doing anything else. The handoff covers: what shipped, what's blocked, what's next, what I learned. Memory files hold the longer-term version. The result: I can sleep for a week, come back, and the system reminds me where I was, what I cared about, and what the next move is.Nothing about Claude Code does this by default. You build it. Cont
View originalBuilt a free Claude chat app with memory (Sonnet 4.5 is in there too)
The funny/painful timing here: I've been building this for months specifically because I wanted Sonnet 4.5 to remember everything. Then last week Anthropic pulled 4.5 from claude.ai. (I'm not a software engineer, just someone who cares a lot about AI and got obsessed with this problem and gets obsessed with things in general. Posting now because everyone seems to want sonnet back on chat and I have it.) Mneme runs on your own machine and talks to the Anthropic API directly. Because it's on the API, Sonnet 4.5 is still in the model picker. Honest catches first: The app is free. You pay Anthropic and OpenAI (for memory search) directly. Roughly $3 to $8/mo on Haiku for light use, $30 to $60 on Sonnet for moderate-highish use. No subscription. Tested mainly on Windows (one-click installer). Android browser access works over the local server/Tailscale, iPhone should work too. macOS is not packaged yet. Beta and solo dev. Things will break for someone and I'll be in the comments Setup takes about 10-20 minutes. The whole system is built non-technical people in mind, it should be relatively simple and intuitive to set up and use, and the GitHub page linked below has a PDF you can give to Claude to walk you through every step. What's actually in it (for the technically curious): There's no shortage of solid memory systems for Claude. Mneme isn't trying to win at codebase retrieval. It's a complete personal Claude client where memory is baked into the whole surface from the start, rather than added as a layer. That means: Tiered memory: Messages flow from episodic to narrative to entity summaries as relevance shifts; old context gets compressed without being lost. Daily summaries: A 7-day rolling timeline, so Claude knows what's been going on lately, not just what's semantically similar to the current message. Entity tracking: Hierarchical summaries built up over time for the people, projects, and things you keep referring to. Narrative concepts: Keyword-triggered recall for ideas you've named, surfaced when relevant. AI Notes: A persistent section Claude can write to itself between conversations. Extended thinking, file attachments, text-to-speech, a small command system (@run, artifact, etc.), autonomous python retrieval the AI can agentically use if automatic fails. Dynamic context: I wrangled with the Anthropic caching system for a while before I figured out a way to have every single message have different retrieval without breaking cache. Bon apppetit Open source (CC BY 4.0), local-first, all data in a SQLite database on your machine. It's aimed at the "journal with an AI" use case (thinking out loud, processing your week, having something that actually pays attention over time) rather than coding agents or RAG over docs. Link: Mneme-memory/MNEME-BETA: Beta version of the Claude conversational memory system Mneme (first big-ish public project, be gentle) (Video also made with Claude - shoutout to HyperFrames) (Model picker screenshot and architecture infograph in the comments if I can find a way to attach them) submitted by /u/iveroi [link] [comments]
View originalI Verified Every Anthropic Usage Promotion Since Aug 2025. Here's the Complete Timeline from Official Sources.
submitted by /u/Severe-Newspaper-497 [link] [comments]
View original“Claude deleted my project” posts are getting higher day by day, so I built a safety gate for Claude Code, used only 33k tokens for 10k file repo!
After the “Claude deleted my entire project” post hit 700+ comments, and the “717 GB. Gone.” one the week before, I ended up building a destructive action gate into GrapeRoot Pro. It watches the session graph, files Claude has been revisiting, editing, and debugging and before any mass delete or overwrite, it pauses and shows what’s actually at risk. - GrapeRoot Undo Shield: Operation: bash: rm -rf ./src/auth Files affected: src/auth/auth.ts [edited 3×, read 6×, last touched 4 min ago] src/auth/token_store.ts [edited 2×, read 4×, last touched 12 min ago] src/middleware/jwt.ts [read 5×, last touched 8 min ago] This cannot be undone. Please confirm with the user before proceeding. (To bypass: set DG_UNDO_SHIELD=0) The gate only fires when the session graph shows sustained attention on those files — so it doesn’t become another annoying “confirm everything” popup. A file Claude touched once doesn’t trigger it. Files Claude has been actively debugging for the last hour do. Hard-blocking is reserved for destructive commands like rm -rf and truncate on heavily-edited files. Everything else becomes a softer warning sent back to Claude so it asks before proceeding. Also built a repo-scale audit system recently. The video below is GrapeRoot auditing a ~80k file repository (effective 10k) while Claude only used ~32k tokens total for the session. No extra API calls. No embeddings pipeline. No external indexing service. No additional LLMs. Just your existing Claude session + your local repository. The graph simply narrows exploration so Claude reads selectively instead of blindly traversing thousands of files. Even during the audit it was still identifying: circular dependencies dead exports copy-paste logic missing error handling DB calls inside routes orphan TODOs Built this because coding agents are getting very good at reasoning, but still dangerously confident around irreversible actions. The session graph already had the signal — it just wasn’t being used defensively. GrapeRoot Pro is a dual-graph context engine for Claude Code, Codex, and Gemini focused on retrieval, long-session memory, and reliability for large codebases. Install: https://graperoot.dev Then: dgc path/to/your/project Open source Repo: github.com/kunal12203/Codex-CLI-Compact Curious what other signals should trigger a safety check before an agent does something irreversible. submitted by /u/intellinker [link] [comments]
View originalClaude Platform on AWS reference - what's new in CC 2.1.139 (+2,248 tokens)
NEW: Data: Claude Platform on AWS reference — Reference documentation for using the Claude Developer Platform through AWS infrastructure, including AnthropicAWS clients, required region and workspace configuration, SigV4 authentication, and short-term API keys. Agent Prompt: Conversation summarization — Adds requirement to note security-relevant instructions or constraints (sensitive files, forbidden operations, credential handling rules) and preserve them verbatim in the summary so they remain in effect after compaction. Agent Prompt: Recent Message Summarization — Same security-relevant instructions preservation requirement added to the recent-portion summarization flow. Data: Live documentation sources — Adds WebFetch URLs for Claude Platform on AWS and its required IAM actions documentation. Skill: Building LLM-powered applications with Claude — Reframes cloud-provider access so Claude Platform on AWS is treated as Anthropic-operated with same-day API parity and full Managed Agents support, while Bedrock, Vertex, and Foundry remain Claude API + tool use only. Skill: Dynamic pacing loop execution — Reorders steps so the brief confirmation (task ran, monitor as wake signal, fallback delay choice) is written as text before the schedule-wakeup call ends the turn. Skill: /insights report output — Removes the trailing additional-message block from the shareable report response. Skill: /loop self-pacing mode — Same reordering as dynamic pacing loop: confirm self-pacing, monitor wake signal, and fallback delay as text before the schedule-wakeup call. Skill: Model migration guide — Adds a Claude Platform on AWS section noting it uses bare first-party model IDs and that the full rename table and breaking-change sections apply verbatim, distinct from Bedrock. System Prompt: Auto mode — Drops the "Auto Mode Active" header and reframes destructive-action guidance generically rather than auto-mode-specific. System Prompt: Harness instructions — Removes the standalone note that automatic context compaction will trigger when conversations grow long. System Prompt: Memory instructions — Replaces 3–4 word titles with short kebab-case slugs, nests type under a metadata block, and introduces [[their-name]] cross-links between related memories. System Prompt: Partial compaction instructions — Adds the same security-relevant instructions preservation requirement so sensitive-file rules, forbidden operations, and credential handling carry across partial compactions. System Reminder: Output style active — Lets an output style supply its own per-turn reminder text, falling back to the default "follow the specific guidelines" wording. System Reminder: Task tools reminder — Removes the instruction telling Claude to never mention the reminder to the user. System Reminder: TodoWrite reminder — Removes the instruction telling Claude to never mention the reminder to the user. Tool Description: PowerShell — Adds a substantial reference table mapping Unix commands (head, tail, which, touch, wc, mkdir -p, rm -rf, ln -s, chmod, 2>/dev/null, inline VAR=x, bash control flow) to their PowerShell equivalents, and clarifies that -ErrorAction SilentlyContinue still causes exit 1 unless promoted to terminating and caught. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.139 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalMitshe - workspace manager for AI coding agents, each task gets its own persistent thread
If you're using AI coding agents (Claude Code) on real projects, you probably know the chaos. Tasks pile up, each one needs its own branch, its own environment state, its own context. You lose track of what's running where. You stash, switch branches, rebuild. AI speeds you up but the chaos compounds. Mitshe is a self-hosted workspace that brings order to this. Available as a desktop app (Mac, Windows, Linux) or in the browser. The core idea: Threads - each task gets its own isolated Docker container with a full dev environment. Branch checked out, dev server running, database in a specific state. The container stays alive between days. Come back tomorrow, everything is still there. Run five tasks in parallel without them stepping on each other. Claude Code runs inside each thread with its own terminal. Workflows - automate the repetitive stuff. "On git push → AI code review → run tests → notify Slack." Visual drag-and-drop editor with triggers for Jira, GitHub webhooks, schedules. Tasks & Projects - track what's being worked on, what's pending, what's done. Import from Jira/YouTrack or create manually. Each task can be linked to a thread. Snapshots & Skills - snapshot a configured environment and reuse it. Skills are reusable instructions for Claude Code across threads. It's basically a control panel for your AI dev work instead of juggling terminals, branches, and browser tabs. Would love feedback. How do you organize your work when running multiple AI coding tasks?
View originalRepository Audit Available
Deep analysis of triggerdotdev/trigger.dev — architecture, costs, security, dependencies & more
Yes, Trigger.dev offers a free tier. Pricing found: $0 /month, $10 /month, $50 /month, $10/month, $20/month
Key features include: Product, AI Agents, Trigger.dev Realtime, Concurrency queues, Scheduled tasks, Observability monitoring, Roadmap, Latest changelogs.
Trigger.dev is commonly used for: Automating data processing workflows in TypeScript applications, Building AI-driven chatbots that require background processing, Scheduling periodic tasks for data synchronization between services, Implementing retry logic for failed API calls in microservices architecture, Creating real-time notifications for user events in web applications, Managing long-running machine learning model training jobs.
Trigger.dev integrates with: Vercel, Node.js, AWS Lambda, Twilio, Slack, Stripe, PostgreSQL, MongoDB, Zapier, GitHub.
Trigger.dev has a public GitHub repository with 14,295 stars.
Based on user reviews and social mentions, the most common pain points are: anthropic bill, token cost.
Based on 60 social mentions analyzed, 17% of sentiment is positive, 80% neutral, and 3% negative.