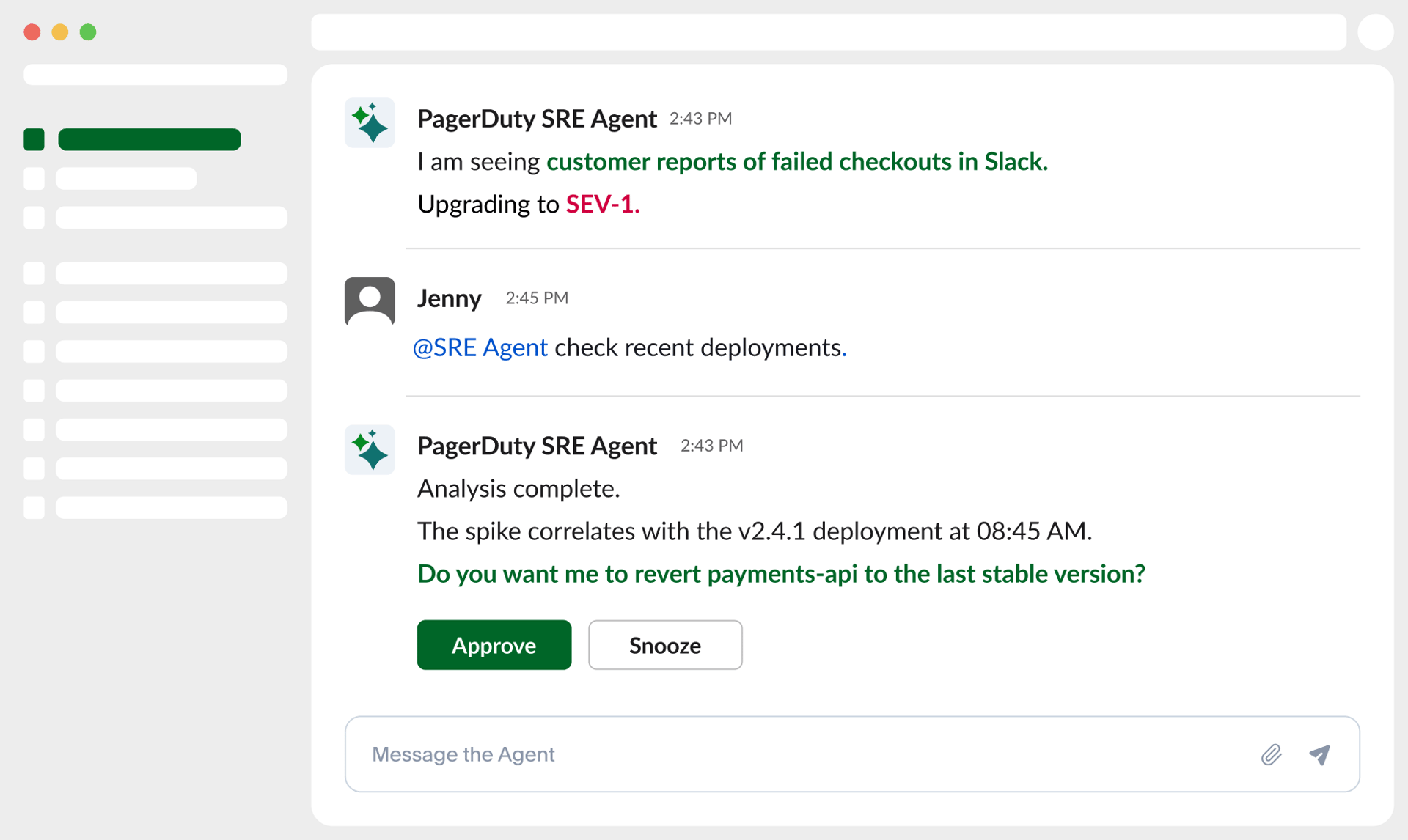
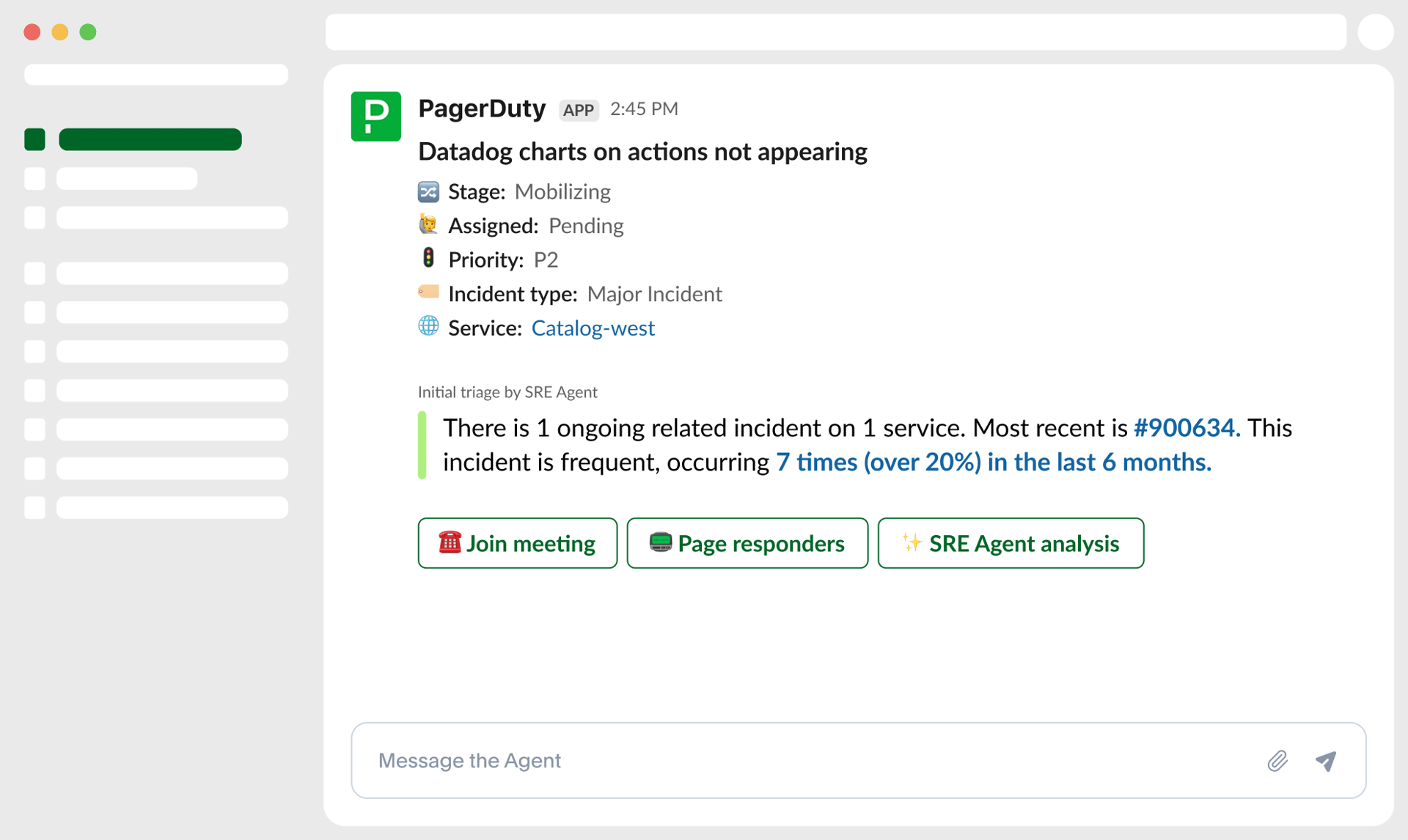
End-to-end incident management that gets smarter over time. AI agents automate the toil, freeing you to focus on what matters.
Users praise PagerDuty AI for its potential to alleviate on-call burdens by automating responses to incidents, particularly at inconvenient hours. However, there's a lack of specific user feedback on its effectiveness and implementation, which may indicate limited user adoption or experience sharing thus far. Pricing sentiment is not mentioned in available reviews or social content. The overall reputation seems neutral due to minimal detailed feedback, with awareness driven by viral content like user-created alternatives.
Mentions (30d)
0
Reviews
0
Platforms
2
Sentiment
17%
1 positive


Users praise PagerDuty AI for its potential to alleviate on-call burdens by automating responses to incidents, particularly at inconvenient hours. However, there's a lack of specific user feedback on its effectiveness and implementation, which may indicate limited user adoption or experience sharing thus far. Pricing sentiment is not mentioned in available reviews or social content. The overall reputation seems neutral due to minimal detailed feedback, with awareness driven by viral content like user-created alternatives.
Features
Use Cases
Industry
information technology & services
Employees
1,300
Pricing found: $0, $0, $48/user, $25, $25
I got tired of 3 AM PagerDuty alerts, so I built an AI agent to fix cloud outages while I sleep. (Built with GLM-5.1)
If you've ever been on-call, you know the nightmare. It’s 3:15 AM. You get pinged because heavily-loaded database nodes in us-east-1 are randomly dropping packets. You groggily open your laptop, ssh into servers, stare at Grafana charts, and manually reroute traffic to the European fallback cluster. By the time you fix it, you've lost an hour of sleep, and the company has lost a solid chunk of change in downtime. This weekend for the Z.ai hackathon, I wanted to see if I could automate this specific pain away. Not just "anomaly detection" that sends an alert, but an actual agent that analyzes the failure, proposes a structural fix, and executes it. I ended up building Vyuha AI-a triple-cloud (AWS, Azure, GCP) autonomous recovery orchestrator. Here is how the architecture actually works under the hood. The Stack I built this using Python (FastAPI) for the control plane, Next.js for the dashboard, a custom dynamic reverse proxy, and GLM-5.1 doing the heavy lifting for the reasoning engine. The Problem with 99% of "AI DevOps" Tools Most AI monitoring tools just ingest logs and summarize them into a Slack message. That’s useless when your infrastructure is actively burning. I needed an agent with long-horizon reasoning. It needed to understand the difference between a total node crash (DEAD) and a node that is just acting weird (FLAKY or dropping 25% of packets). How Vyuha Works (The Triaging Loop) I set up three mock cloud environments (AWS, Azure, GCP) behind a dynamic FastApi proxy. A background monitor loop probes them every 5 seconds. I built a "Chaos Lab" into the dashboard so I could inject failures on demand. Here’s what happens when I hard-kill the GCP node: Detection: The monitor catches the 503 Service Unavailable or timeout in the polling cycle. Context Gathering: It doesn't instantly act. It gathers the current "formation" of the proxy, checks response times of the surviving nodes, and bundles that context. Reasoning (GLM-5.1): This is where I relied heavily on GLM-5.1. Using ZhipuAI's API, the agent is prompted to act as a senior SRE. It parses the failure, assesses the severity, and figures out how to rebalance traffic without overloading the remaining nodes. The Proposal: It generates a strict JSON payload with reasoning, severity, and the literal API command required to reroute the proxy. No Rogue AI (Human-in-the-Loop) I don't trust LLMs enough to blindly let them modify production networking tables, obviously. So the agent operates on a strict Human-in-the-Loop philosophy. The GLM-5.1 model proposes the fix, explains why it chose it, and surfaces it to the dashboard. The human clicks "Approve," and the orchestrator applies the new proxy formation. Evolutionary Memory (The Coolest Feature) This was my favorite part of the build. Every time an incident happens, the system learns. If the human approves the GLM's failover proposal, the agent runs a separate "Reflection Phase." It analyzes what broke and what fixed it, and writes an entry into a local SQLite database acting as an "Evolutionary Memory Log". The next time a failure happens, the orchestrator pulls relevant past incidents from SQLite and feeds them into the GLM-5.1 prompt. The AI literally reads its own history before diagnosing new problems so it doesn't make the same mistake twice. The Struggles It wasn't smooth. I lost about 4 hours to a completely silent Pydantic validation bug because my frontend chaos buttons were passing the string "dead" but my backend Enums strictly expected "DEAD". The agent just sat there doing nothing. LLMs are smart, but type-safety mismatches across the stack will still humble you. Try it out I built this to prove that the future of SRE isn't just better dashboards; it's autonomous, agentic infrastructure. I’m hosting it live on Render/Vercel. Try hitting the "Hard Kill" button on GCP and watch the AI react in real time. Would love brutal feedback from any actual SREs or DevOps engineers here. What edge case would break this in a real datacenter? submitted by /u/Evil_god7 [link] [comments]
View originalYes, PagerDuty AI offers a free tier. Pricing found: $0, $0, $48/user, $25, $25
Key features include: PagerDuty Operations Cloud, Incident Management, AI at PagerDuty, Automation, AI Agents, Status Pages, PagerDuty Advance, Customer Service Ops.
PagerDuty AI is commonly used for: Incident Management Transformation.
PagerDuty AI integrates with: Slack, Microsoft Teams, Jira, ServiceNow, GitHub, AWS CloudWatch, Google Cloud Platform, Zendesk, Opsgenie, New Relic.