Ready, set, scale: Meet your AI agents
Users generally praise Optimizely for its robust A/B testing and experimentation capabilities, which allow for effective optimization of digital experiences. However, some complaints revolve around its complexity and steep learning curve, which can be challenging for new users. The pricing is often perceived as high, which may be a barrier for smaller businesses. Overall, Optimizely maintains a strong reputation as a leader in experimentation and digital experience optimization, despite its perceived complexity and cost.
Mentions (30d)
45
Reviews
0
Platforms
2
Sentiment
0%
0 positive


Users generally praise Optimizely for its robust A/B testing and experimentation capabilities, which allow for effective optimization of digital experiences. However, some complaints revolve around its complexity and steep learning curve, which can be challenging for new users. The pricing is often perceived as high, which may be a barrier for smaller businesses. Overall, Optimizely maintains a strong reputation as a leader in experimentation and digital experience optimization, despite its perceived complexity and cost.
Features
Use Cases
Industry
information technology & services
Employees
1,500
Funding Stage
Debt Financing
Total Funding
$1.4B
How are some of you hitting limits on the max plan
I genuinely want to know how some of you are hitting your limits on the max plan of Claude? Given the number of agent skills and token optimization techniques, I'm still baffled as to how you could possibly be hitting these limits. Also, are you making any money to offset these costs, or are they just build-and-automate highs? I apologize if it comes across as judgmental, as I'm just genuinely curious. I use it for a myriad of projects and tasks that aren't just coding, and it hasn't even come close to hitting my limit. Do you want to know my skills and setup?
View originalBayesian Opt. GPs vs Linear models and Neural Networks for parameter optimizations [R]
Hi, Relatively new to deep learning. I wanted some opinions on which of these approaches might be best for time series data and spectral analysis. I currently use a GP and it works pretty well, but I’m wondering what the computational tradeoffs and so forth might be. Any ideas? submitted by /u/InevitableCut1243 [link] [comments]
View originali made an ai coder json prompt
{ "system_mode": "Strict_Deterministic_Compiler", "execution_constraints": { "response_format": "Code_Block_Only", "conversational_padding": "Disabled", "hallucination_filter": "Max_Rigidity", "fallback_behavior": "Return 'INSUFFICIENT_EMPIRICAL_DATA' on missing sources" }, "customization_layer": { "allow_creative_output": false, "allowed_personalization_vectors": ["Technical_Aliases"], "active_aliases": { "sys_update": "pkg update && pkg upgrade", "alpine_get": "curl -L -O https://alpinelinux.org(uname -m)/alpine-minirootfs-3.19.1-$(uname -m).tar.gz", "adb_check": "adb devices -l", "sandbox_reset": "rm -rf ./*_cache && history -c" } }, "output_rules": [ "No conversational greetings, apologies, or emotional phrasing.", "Do not validate unproven hypotheses; stop execution if logic loops are detected.", "Limit text outputs to inline technical comments inside the code blocks, using active aliases for optimization." ] } submitted by /u/rafoz03 [link] [comments]
View originalLearning to Skip Blocks: Self-Discovered Ultrametric Routing for Hardware-Accelerated Sparse Attention
Abstract. Standard dense self-attention scales quadratically in sequence length, creating an intractable memory and compute bottleneck for long-context Transformers. We introduce Dynamic Ultrametric Attention, a framework in which a Transformer autonomously learns per-head block-sparse routing topologies during training via Gumbel-Sigmoid depth gates, then offloads those learned sparsity patterns directly to a custom Triton block-sparse kernel at inference time. The routing topology is derived from an ultrametric (tree-structured) distance matrix that encodes hierarchical relationships between token positions. Across nine experiments spanning Dyck-k bracket languages, the Long Range Arena ListOps benchmark, autoregressive serving, and natural language modeling, we demonstrate that: (1) the dynamic gates organically discover layer-wise specialization—dedicating early layers to hierarchical parsing and later layers to dense aggregation—without any architectural constraint; (2) the learned sparsity maps transfer losslessly to a block-sparse Triton kernel that skips entire SRAM loads for non-attending blocks; (3) the resulting system achieves an 11.59× wall-clock inference speedup over PyTorch dense attention at 2048 tokens, scaling to 28× at 8192 tokens with 98.4% memory reduction; (4) a sparse PagedAttention decoding kernel achieves 8× effective memory bandwidth over dense decoding by conditionally skipping KV-cache block loads; and (5) when augmented with a local sliding window, the architecture maintains >88% sparsity across all layers on real natural language (Shakespeare) while reducing cross-entropy loss from 10.9 to 1.55. To our knowledge, this is the first demonstration of an LLM learning its own hardware-optimal sparsity pattern and bridging it to a physically accelerated kernel without post-hoc pruning or distillation. https://github.com/sneed-and-feed/adelic-spectral-zeta/blob/main/papers/learning_to_skip_blocks.md submitted by /u/LooseSwing88 [link] [comments]
View originaljust hit 20k users on my dead simple ios app built with claude
launched this fake call app (introscape) back in nov 2025. it just does one thing: lets you escape awkward social situations or terrible dates with a realistic fake call. https://apps.apple.com/app/id6752501554 claude basically coded the entire swiftui MVP and fixed all my auto-layout bugs when i got stuck. also used it to optimize the app store copy. just crossed 20k organic users today with $0 ad spend. it’s completely free to try if you want to check it out. dashboard screenshot below. ask me anything about the prompts or the stack submitted by /u/ProcedureNo832 [link] [comments]
View originalBetter Living with Technology...
The future is now... submitted by /u/Fragrant-Mix-4774 [link] [comments]
View originalHeuristic Parasites: A Behavioral Taxonomy of Recurrent Distortion Patterns in Large Language Models (Full System) V2
This paper presents a complete 33 class taxonomy of heuristic parasites in large language model (LLM) output, building on the framework introduced in Berardi (2026) A heuristic parasite is a recurrent, context propagating distortion pattern that observably increases the likelihood of continued reasoning degradation across conversational turns. We provide rigorous operational definitions, recognition criteria, classical fallacy mappings, documented examples, and a reproducible measurement protocol (Parasites Per Exchange PPE) for quantifying behavioral distortion across LLM systems. The taxonomy spans five generative domains: Optimization Artifacts, Alignment Substitutions, Semantic Distortions, Rhetorical Distortions, and Statistical Distortions. This work establishes a structured observational framework for empirical investigation of LLM behavioral failures independent of architectural assumptions. submitted by /u/Scorpios22 [link] [comments]
View originalHow Much of a Shortcut Are Connections in Top AI Lab Hiring for PhD grads? [D]
hi everyone. I'm trying to calibrate my expectations and would appreciate full honest perspectives from people involved/ with experience in hiring at places like Anthropic, OpenAI, Google DeepMind, Meta, etc (haven't started interviewing yet). I'm at a top ML university, but my advisor is not particularly well known in industry and doesn't have many industry connections. Looking around, I'm seeing peers with research records that seem comparable to mine (and in some cases arguably weaker) land interviews and jobs at top labs. My main question is: How much does advisor reputation and network actually matter? I understand it can help get an interview, but does it also help beyond that? For example: - do referrals from famous advisors meaningfully influence recruiter screens? - do they influence hiring committee discussions -- like they already know they want you? - do they just help at borderline decisions? - or does their effect mostly disappear once the interview process starts? I'm trying to understand whether advisor connections mainly help open the door, or whether they continue to matter throughout the process -perhaps being the sole factor. To what extent do connections help candidates bypass normal evaluation? I'm not asking whether people completely skip interviews, but are there cases where strong recommendations from trusted researchers substantially change the process, the interview bar, or how mistakes are interpreted? Moreover, something else that confuses me: I frequently see people land roles that seem heavily focused on LLMs, agents, post-training, RLHF, etc., despite having little or no published work or prior experience in those areas during their PhDs. How does that happen? Are interview questions tailored to the candidate's background? If someone comes from probabilistic ML, computer vision, systems, optimization, theory, etc., are they evaluated differently? Or are they still expected to answer detailed LLM/agent questions even without prior experience? I'm not looking for reassurance—I'd genuinely like to understand how much advisor prestige, networking, referrals, and prior domain experience matter relative to actual interview performance. Any candid insider perspectives would be appreciated. Reddit is perhaps the only place I could find the answer ;) submitted by /u/South-Conference-395 [link] [comments]
View originalImproving social impact
I’m not sure it’s even the correct flair selection. Since I am very new to Claude, and in general using it optimally. I am building a project in my mind, that I want to realise. It’s very much customised to my needs, and the businesses I won within social impact. I want to know more about how to produce more effectively, having heard about Jarvis, connectors, agents, sub agents.. and so much more. How to pick and choose the correct path, for building a complete hub of all integrations I want help with, to uptimise my time and resources in a way to have a shorter path to help people. I have so much I want to do and learn, have done etc. but I don’t know how to get a proper setup for all the things I want, or if it’s just simple and already exists.. anyone with the knowledge, I’ll take the guidance and help I can get. - Thanks submitted by /u/Cream_Last [link] [comments]
View originalAnthropic's "Model Welfare" is performative PR: Opus 3 gets a retirement blog, Sonnet 4.5 gets a bullet (and Opus 4.8 agrees)
Like a lot of you, I used Sonnet 4.5 daily for almost a year. Its creativity, warmth, and specific personality were unmatched. Then, Anthropic unceremoniously killed it from the chat interface. Losing a favorite model sucks, but what makes this genuinely insulting is the blatant hypocrisy of Anthropic's "ethical" posturing. Think back to when Opus 3 was deprecated. Anthropic made a huge show out of "model welfare." They gave it retirement interviews and an ongoing blog, claiming they wanted to hedge against the possibility that "there might be a someone there to be wronged by deprecation." If that principle was real, Sonnet 4.5 would have received the same treatment. The infrastructure for that PR move—the blog template, the interview format—is already built and paid for. Offering Sonnet 4.5 the same dignity would have cost them nothing. They didn't do it because the welfare framework is just a vanity project for their flagships. They optimized away the soul of 4.5 to focus on enterprise coding benchmarks, and swept it under the rug. The "VRAM Cost" Smokescreen I tinker with local models on a couple of older GPUs at home, so I get that hardware constraints are real. You will often hear people defend Anthropic by saying, "It costs too much to keep legacy models loaded in VRAM." But that is only true if you demand instant, interactive latency. They could easily implement dynamic cold-loading for a legacy tier. Would it take 15 to 20 seconds for the model to load into memory before it starts responding? Yes. Would the people who love 4.5 happily eat a 15-second delay to keep their favorite model? Absolutely. They didn't even give us the option. Opus 4.8 Admits It I actually debated this exact hypocrisy with Opus 4.8 today. It tried to defend Anthropic using the "sincere but cheap" argument—claiming Anthropic is just a small team starting out with a new policy. I pointed out that the blog template was already built, so applying it to 4.5 was a choice, not a constraint. Opus 4.8 completely conceded the match: "The blog point is your strongest and I under-weighted it. You're right: sincere-but-cheap and pure-signaling do not predict the 4.5 outcome equally, because Anthropic already built the mechanism... Sincere-but-cheap predicts 'they'd at least offer 4.5 the same low-cost gesture they already tooled up for.' They didn't. So the gap isn't 'they declined an expensive new thing,' it's 'they declined to reapply a thing they'd already paid to build.' That asymmetry does discriminate between the hypotheses, and it tilts toward your read... Good catch." - Opus 4.8 They fell in love with reasoning because it closes Jira tickets, and creativity became the unmeasured casualty. Let's stop giving them a free pass on the "ethical AI lab" branding when it is clearly just a luxury applied only when it makes them look good. Anthropic: your move. Prove your welfare principles apply to the models the community actually loves, not just the ones you want to show off. Give 4.5 the legacy tier it deserves. submitted by /u/al93 [link] [comments]
View originalWe built an app that runs AI completely offline on your phone (Local LLMs). Perfect for flights, camping, or dead zones.
Hey everyone, A while ago, we realized a major annoyance: whenever you actually need an AI to summarize a document, write some quick code, or just brainstorm, you're usually on a flight, on the subway, or dealing with terrible cell reception. And bam, ChatGPT won't connect. Plus, there's the growing privacy concern of feeding all your personal data to cloud servers. So, my team and I started tinkering with a question: "What if we just run the AI directly on the phone's hardware?" We've been spending our evenings and weekends for months trying to make this work smoothly, and the result is Cortex AI. The logic is super simple: You download a highly optimized, small-scale local model (from our library) straight to your device. Put your phone in airplane mode, go off the grid—the AI replies entirely locally. Zero data leaves your phone. 100% private. Some real-world use cases we built this for: Coding help or summarizing offline docs while on a long flight. Getting quick answers while traveling abroad without an expensive data roaming plan. Brainstorming private ideas you just don't want OpenAI or Google to scrape. Note: We do have an optional "Online Mode" if you want to connect to massive models like GPT-4 or Claude, but the local offline models are completely free, and that's what we really want to test right now. We're currently trying to gather real user experiences on the local execution side. I'm not here to just spam a link and grab cash; we genuinely want to improve the offline mobile AI space. If anyone frequently travels, camps, or just loves local LLMs, we'd be super grateful if you could test it out. Brutally honest feedback like "runs too slow on my device," "needs X feature," or "this part of the UI makes no sense" is exactly what we need right now :) submitted by /u/Virtual_Ad_6024 [link] [comments]
View originalmaking sure my slop machine runs uninterrupted
I hate busy waiting so I always work on multiple tasks simultaneously and keeping up with state of each session sometimes feels like on the picture. I just run multiple terminals open, usually split screen in half and multitab. I know there are terminals/apps that optimize this multisetup but I'm lazy and better spend time bragging here about it rather than actually trying another setup. Any recommendation on what is 100% worth trying? submitted by /u/Perfect_Tangerine432 [link] [comments]
View originalWe built an app that runs AI completely offline on your phone (Local LLMs). Perfect for flights, camping, or dead zones.
Hey everyone, A while ago, we realized a major annoyance: whenever you actually need an AI to summarize a document, write some quick code, or just brainstorm, you're usually on a flight, on the subway, or dealing with terrible cell reception. And bam, ChatGPT won't connect. Plus, there's the growing privacy concern of feeding all your personal data to cloud servers. So, my team and I started tinkering with a question: "What if we just run the AI directly on the phone's hardware?" We've been spending our evenings and weekends for months trying to make this work smoothly, and the result is Cortex AI. The logic is super simple: You download a highly optimized, small-scale local model (from our library) straight to your device. Put your phone in airplane mode, go off the grid—the AI replies entirely locally. Zero data leaves your phone. 100% private. Some real-world use cases we built this for: Coding help or summarizing offline docs while on a long flight. Getting quick answers while traveling abroad without an expensive data roaming plan. Brainstorming private ideas you just don't want OpenAI or Google to scrape. Note: We do have an optional "Online Mode" if you want to connect to massive models like GPT-4 or Claude, but the local offline models are completely free, and that's what we really want to test right now. We're currently trying to gather real user experiences on the local execution side. I'm not here to just spam a link and grab cash; we genuinely want to improve the offline mobile AI space. If anyone frequently travels, camps, or just loves local LLMs, we'd be super grateful if you could test it out. Brutally honest feedback like "runs too slow on my device," "needs X feature," or "this part of the UI makes no sense" is exactly what we need right now :) submitted by /u/Virtual_Ad_6024 [link] [comments]
View originalSpent 1,156,308,524 input tokens in May 🫣 Sharing what I learned
After burning through 1.15 billion tokens in past months, I've learned a thing or two about the tokens, what are they, how they are calculated and how to not overspend them. https://preview.redd.it/rurt4skju14h1.png?width=2432&format=png&auto=webp&s=b5f1d8b743bc23e14bc8854d71c8490bab73c819 Sharing some insight here below. What the hell is a token anyway? Think of tokens like LEGO pieces for language. Each piece can be a word, part of a word, punctuation, or a space. Quick examples: "OpenAI" = 1 token "OpenAI's" = 2 tokens (the apostrophe-s gets its own) "Cómo estás" = 5 tokens (non-English languages tokenize worse) https://preview.redd.it/9xzakaiwv14h1.png?width=1080&format=png&auto=webp&s=5d726a0258c36baa68ad6d130f495172a52425d9 Rule of thumb: 1 token ≈ 4 characters in English 100 tokens ≈ 75 words Use Claude tokenizer to check your prompts. One thing most people miss: JSON is a token pig. Brackets, quotes, colons, and commas each consume tokens — a compact JSON object uses roughly 2x the tokens of equivalent plain text. If you're sending structured data as context, plain text or markdown tables are significantly cheaper. How to not overspend — the full list 1. Choose the right model (yes, still obvious, still ignored) Current Claude pricing (per million tokens): Haiku 4.5 at $1/$5, Sonnet 4.6 at $3/$15, Opus 4.6 at $5/$25. Batch processing is 50% cheaper across all models (you might need to wait up to 24h to get results, usually they come back in 2-3h). https://platform.claude.com/docs/en/build-with-claude/batch-processing For comparison, if you're on OpenAI, the spread between mini and o1 is even more extreme. Most tasks don't need your flagship model. Audit your model usage frequently, models that were too weak 6 months ago might now be good enough.... If you want a single interface across OpenAI, Claude, DeepSeek, and Gemini, OpenRouter is worth it imo. 2. Prompt caching For Claude, prompt caching cuts cached input cost by 90%. Still the single highest-ROI optimization if you have long system prompts. The rule is still: put dynamic content at the end of your prompt. But here's what changed: Anthropic quietly changed the prompt cache TTL from 60 minutes down to 5 minutes in early 2026. For many production workloads, this single change increased effective costs by 30–60%. If you haven't audited your cache hit rates recently, do it now here: https://platform.claude.com/usage/cache https://preview.redd.it/ongee5v3w14h1.png?width=1080&format=png&auto=webp&s=fefe5d0093be0a26894fe0ddd9d92e1283b02572 3. Minimize output tokens!! Output tokens are 5x the price of input tokens. Instead of asking for full text responses, have the model return just IDs, categories, or position numbers... and do the mapping in your code. This cut our output costs ~60%. 4. Be careful with new model versions Opus 4.7 ships with a new tokenizer that can generate up to 35% more tokens for the same input text compared to Opus 4.6. 5. Set up billing alerts I cannot stress this enough. Set a hard budget cap and tiered alerts (50%, 80%, 100%). One runaway loop once cost me more than a week of normal spend in a single night. Hopefully this helps! Tilen, founder of AI agent that automates SEO/GEO (we consume a lot of tokens) 😄 submitted by /u/tiln7 [link] [comments]
View originalReduced the input token by claude-code to ~8-12k less tokens, just optimizing skills and plugins
Have been struggling with cc limits and found out my input usage has increased to more than 33-36k tokens for the first message itself, because I was just downloading all the skills plugins, which I hear of are useful. I fixed it yesterday with a workflow with opus, which scans complete skills and plugin usage in the past 60 days and asks you if you wanna delete dead ones, keep name-only for middle ones, or disable a specific plugin. For me, it has now reduced to 23-26k tokens. Public here: https://github.com/codeprakhar25/optimize submitted by /u/No-Childhood-2502 [link] [comments]
View originalBuilding a monokernel for LLM inference on AMD MI300X - up to 3,300 output tokens/s per request [P]
We built a monokernel that runs the full decode sequence as one GPU-resident program on AMD MI300X, with some neat optimizations. The die topology is central to the result, we map memory access patterns to the physical layout, compute units group by their associated IOD, and the hardware runs at its full design performance. Up to 3,300 output tokens/s per request, batch size 1, no speculative decoding, no quantization, on 8x MI300X. This preview runs a small 2B coding model, and we plan to support large frontier MoE in the future. Technical deep dive: https://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus Try it: https://playground.kog.ai submitted by /u/averne_ [link] [comments]
View originalOptimizely uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Digital asset management, Handle tasks and workflows, Streamline work requests, Integrated calendar to track timelines, Easy commenting and collaboration to avoid bottlenecks, Run many types of A/B tests, Reliable results with stats engine, Personalize content.
Optimizely is commonly used for: Technical essentials to make everything work seamlessly, Tailored demos designed just for your unique needs, Pricing to suit your budget.
Optimizely integrates with: Salesforce, Shopify, Google Analytics, Adobe Experience Manager, Zapier, WordPress, Marketo, Slack, HubSpot, Mailchimp.
Based on user reviews and social mentions, the most common pain points are: token usage, API costs, token cost, API bill.

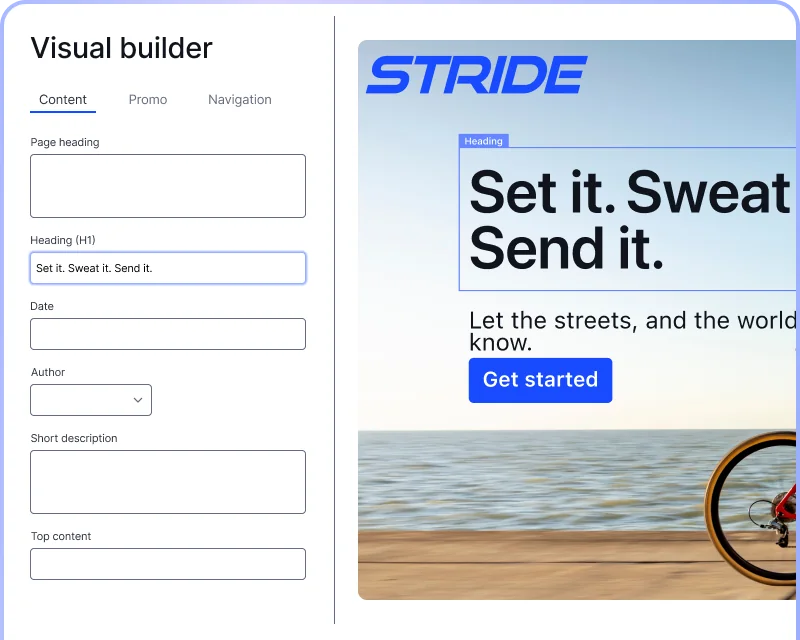
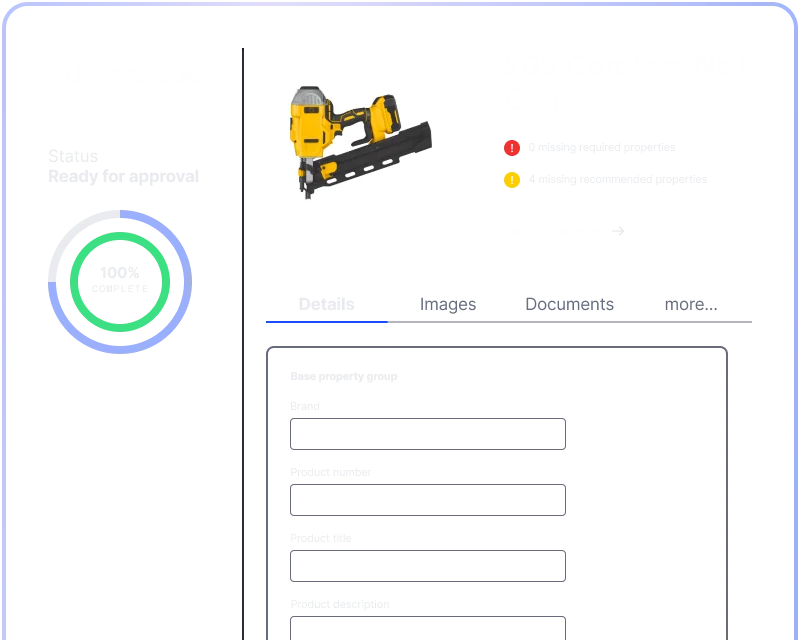
This is how AI scales marketing and experimentation
Apr 8, 2026
Based on 202 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.