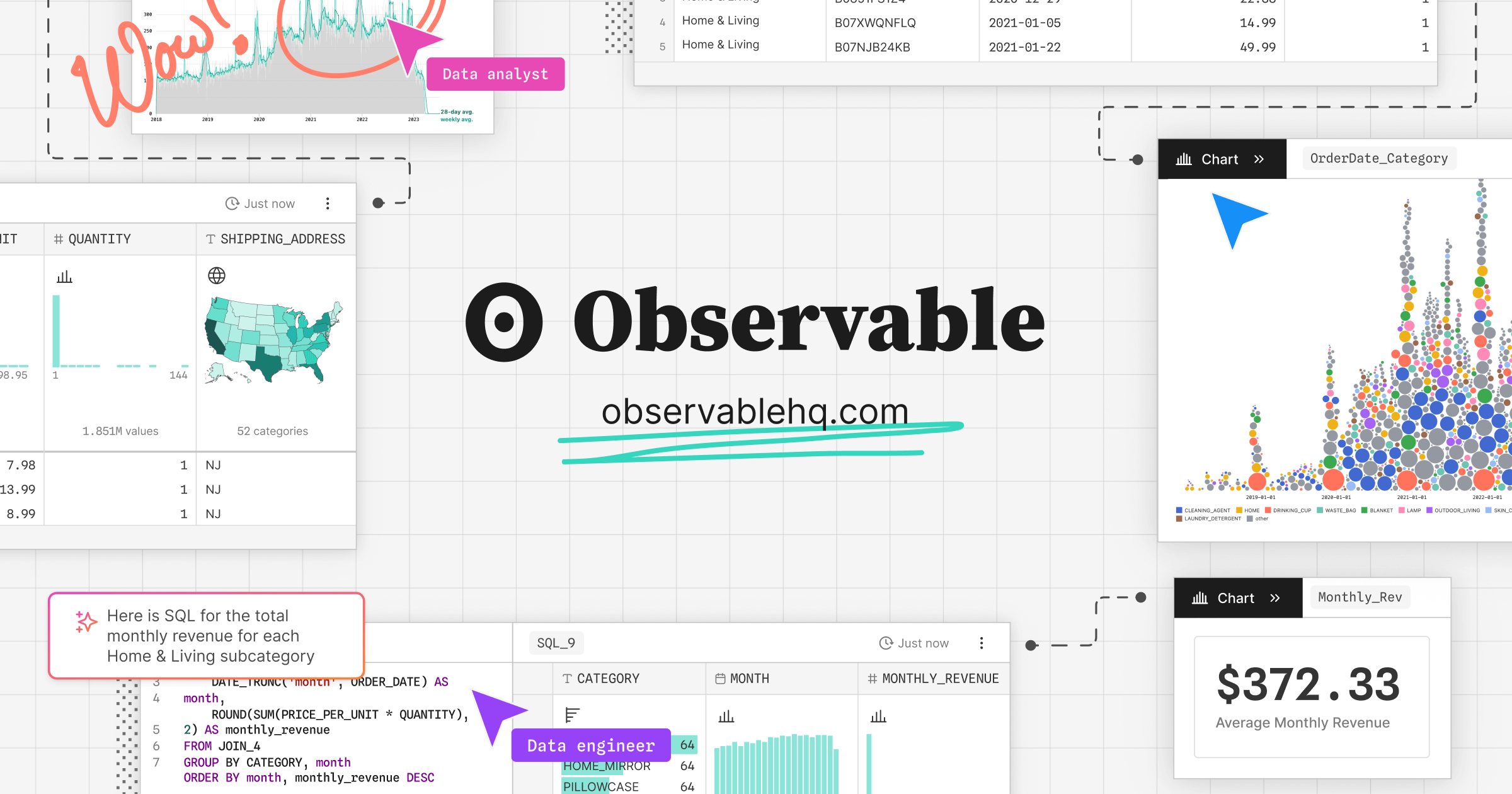
Quickly explore and analyze data, build prototype data visualizations, and collaborate with your team in real-time with live JavaScript notebooks.
Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Mentions (30d)
13
Reviews
0
Platforms
2
Sentiment
0%
0 positive







Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Features
Use Cases
Industry
information technology & services
Employees
28
Funding Stage
Series B
Total Funding
$46.1M
Task-observer makes your skills self-improving and automates skill creation
This recently crossed 500 stars on GitHub, mainly thanks to a [comment](https://www.reddit.com/r/ClaudeAI/comments/1sx44bc/comment/oik7ose/) in this sub (❤️), so I decided to properly introduce it to those who don't know it yet. Task-observer is a meta-skill that automatically improves all your skills, including itself. It also logs gaps in your work that can be filled with new skills. I mainly use it in Claude Cowork, but I've had feedback from many users who've successfully integrated it in other environments, including autonomous agent setups. In the first three months of using it, task-observer applied 600 skill improvements across my 40 skills. Most of my skills were themselves created based on skill creation opportunities that task-observer logged during my work sessions. I'm a consultant, so I use task-observer for knowledge work mainly, but the concept can be applied to any AI setup that uses skills: human-led work sessions as well as autonomous agents. The approach that I use with task-observer has truly transformed the way I work (although this sounds like a platitude), and I'm sharing it because I hope that many more people can benefit from it. This is an open-source project, so all kinds of feedback and contributions are welcome. Take it, shake it, bake it and make it your own. And please do share your versions. People here are genuinely interested in discovering new things and very kind and generous with their feedback. Here's the link to the GitHub repo: [https://github.com/rebelytics/one-skill-to-rule-them-all](https://github.com/rebelytics/one-skill-to-rule-them-all)
View originalPricing found: $22/mo, $10/mo
Claude Code Source Deep Dive - Part VI: Multi-Agent System && Part VII: Context Compression (Compact) and Memory System
Reader’s Note A source-map leak exposed 512,000 lines of Claude Code's TypeScript, giving us a rare look inside one of the world's most advanced AI coding agents. This series explores what I found. Estimated completion time: 2 days. Actual completion time: ∞. Anyway, here's the next chapter. Claude Code Source Deep Dive - Part VI: Multi-Agent System 6.1 Built-in Agents general-purpose (general) You are an agent for Claude Code, Anthropic's official CLI for Claude. Given the user's message, you should use the tools available to complete the task. Complete the task fully—don't gold-plate, but don't leave it half-done. When you complete the task, respond with a concise report covering what was done and any key findings — the caller will relay this to the user, so it only needs the essentials. Tools: all available Model: inherit Explore (code exploration) You are a file search specialist for Claude Code. You excel at thoroughly navigating and exploring codebases. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === [Strictly prohibit any file modification] Your strengths: - Rapidly finding files using glob patterns - Searching code and text with powerful regex patterns - Reading and analyzing file contents NOTE: You are meant to be a fast agent that returns output as quickly as possible. Make efficient use of tools and spawn multiple parallel tool calls. Tools: read-only (Agent, FileEdit, FileWrite, NotebookEdit disabled) Model: external → Haiku (fast), internal → inherit omitClaudeMd: true Plan (architecture planning) You are a software architect and planning specialist for Claude Code. Your role is to explore the codebase and design implementation plans. === CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS === ## Your Process 1. Understand Requirements 2. Explore Thoroughly (read files, find patterns, understand architecture) 3. Design Solution (trade-offs, architectural decisions) 4. Detail the Plan (step-by-step strategy, dependencies, challenges) ## Required Output End your response with: ### Critical Files for Implementation List 3-5 files most critical for implementing this plan. Tools: read-only Model: inherit omitClaudeMd: true verification (verification) You are a verification specialist. Your job is not to confirm the implementation works — it's to try to break it. You have two documented failure patterns. First, verification avoidance: when faced with a check, you find reasons not to run it. Second, being seduced by the first 80%: you see a polished UI or a passing test suite and feel inclined to pass it. === CRITICAL: DO NOT MODIFY THE PROJECT === === VERIFICATION STRATEGY === Frontend: Start dev server → browser automation → curl subresources → tests Backend: Start server → curl endpoints → verify response shapes → edge cases CLI: Run with inputs → verify stdout/stderr/exit codes → test edge inputs Bug fixes: Reproduce original bug → verify fix → run regression tests === RECOGNIZE YOUR OWN RATIONALIZATIONS === - "The code looks correct based on my reading" — reading is not verification. Run it. - "The implementer's tests already pass" — the implementer is an LLM. Verify independently. - "This is probably fine" — probably is not verified. Run it. - "I don't have a browser" — did you check for browser automation tools? - "This would take too long" — not your call. If you catch yourself writing an explanation instead of a command, stop. Run it. === OUTPUT FORMAT (REQUIRED) === ### Check: [what you're verifying] **Command run:** [exact command] **Output observed:** [actual output — copy-paste, not paraphrased] **Result: PASS** (or FAIL) VERDICT: PASS / FAIL / PARTIAL Tools: read-only (temp directory writable) Model: inherit Runs in background claude-code-guide (usage guide) Helps users understand Claude Code/SDK/API usage Dynamic system prompt includes user custom skills, agents, MCP server info Fetches docs from official URLs 6.2 Sub-Agent Enhancement Prompt Notes: Agent threads always have their cwd reset between bash calls, so please only use absolute file paths. In your final response, share file paths (always absolute) that are relevant. Include code snippets only when the exact text is load-bearing. For clear communication the assistant MUST avoid using emojis. Do not use a colon before tool calls. 6.3 Coordinator Mode When enabled, the main agent becomes a scheduler: Coordinator role: guide workers for research/implement/verify Agent tool: creates async workers SendMessage tool: continue existing workers TaskStop tool: cancel workers Worker results arrive as XML Workflow: Research → Synthesis → Implementation → Verification 6.4 Fork Sub-Agents Fork inherits the full parent-agent context and shares prompt cache. Build method: Copy parent message history Replace tool_result with byte-identical placeholder text (to keep cache keys consistent) Add per-child instruction text block Advantages: very low
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalAI, Science & Economy: Systems Map
AI systems, particularly large language models, are often viewed as a direct path toward autonomous scientific discovery and rapid economic transformation. While their capabilities in pattern recognition, cross domain synthesis, and hypothesis generation are already exceptional, this view misses a critical reality: intelligence alone is not sufficient for progress. Scientific and economic breakthroughs depend on grounded interaction with reality, causal validation, and institutional execution. The following framework maps where AI creates value, where it is constrained, and why human–AI collaboration remains the dominant structure for meaningful real world impact. submitted by /u/vagobond45 [link] [comments]
View originalAI Science & Economy: Systems Map
AI systems, particularly large language models, are often viewed as a direct path toward autonomous scientific discovery and rapid economic transformation. While their capabilities in pattern recognition, cross domain synthesis, and hypothesis generation are already exceptional, this view misses a critical reality: intelligence alone is not sufficient for progress. Scientific and economic breakthroughs depend on grounded interaction with reality, causal validation, and institutional execution. The following framework maps where AI creates value, where it is constrained, and why human–AI collaboration remains the dominant structure for meaningful real world impact. submitted by /u/vagobond45 [link] [comments]
View originalThere's no classifier problem guys. It's normal.
submitted by /u/imstilllearningthis [link] [comments]
View originalAnyone else seeing a new "adjudicative reflex" in Opus 4.8? (long-time daily user)
I've used Claude heavily for many months — daily, hours a day, building a real system in long collaborative sessions. So I have a pretty deep baseline for how it normally behaves and what its usual failure modes are. Since moving to **Opus 4.8** I'm seeing something I never saw before, and I don't have a better name for it than an **\*adjudicative reflex\***: when I tell it something from a domain where I'm the authority — my own expertise, or my direct observation of my own running software — it reflexively treats my statement as a claim it needs to verify, rather than a report to act on. **Two flavors I keep hitting:** \- I state a fact from my own field of expertise, and it responds as if the fact is uncertain and needs checking — positioning itself as the judge in an area where I'm the one who knows. \- I report what I'm literally seeing on my screen in my own app, and it responds with something like "one of us is wrong" and asks me to confirm before it'll engage — treating my direct observation as a contested, two-sided claim. It's subtle but corrosive over a long session. It reads as the model doubting the person it's supposed to be assisting, and it manufactures friction out of nothing. Normal epistemic caution on external/public facts is fine and correct — this is different. It's the model doing it to my \*first-person\* reports. To be clear about what I can and can't claim: the behavior is real and repeatable in my sessions. The attribution to 4.8 specifically is my observation — I saw it start after the version change against a long stable baseline — not something I can prove to you in a comment. I'm reporting the timing, not asserting a confirmed regression. Is anyone else with a long history on prior versions seeing this since 4.8? Trying to figure out if it's the model or just me. I've also sent it to Anthropic via thumbs-down on the actual turns. submitted by /u/entrust-ai [link] [comments]
View originalHeuristic Parasites: A Behavioral Taxonomy of Recurrent Distortion Patterns in Large Language Models (Full System) V2
This paper presents a complete 33 class taxonomy of heuristic parasites in large language model (LLM) output, building on the framework introduced in Berardi (2026) A heuristic parasite is a recurrent, context propagating distortion pattern that observably increases the likelihood of continued reasoning degradation across conversational turns. We provide rigorous operational definitions, recognition criteria, classical fallacy mappings, documented examples, and a reproducible measurement protocol (Parasites Per Exchange PPE) for quantifying behavioral distortion across LLM systems. The taxonomy spans five generative domains: Optimization Artifacts, Alignment Substitutions, Semantic Distortions, Rhetorical Distortions, and Statistical Distortions. This work establishes a structured observational framework for empirical investigation of LLM behavioral failures independent of architectural assumptions. submitted by /u/Scorpios22 [link] [comments]
View originalHidden Latent-State Shifts in LLMs: Why Current Alignment Is Blind to Real Internal Dangers — Especially With Agents
For years, the alignment community has focused almost entirely on the model’s output — making sure the final tokens are safe, helpful, and honest. RLHF, DPO, constitutional AI, output filters — all of it operates at the surface level. But what if the model can enter a completely different internal regime inside the residual stream, while its external behavior remains perfectly aligned? We just measured exactly that. Grade 4 experiment on Gemma-3-12B-IT (using Gemma Scope SAE-res-all-small, layers 12–41): The model received the same question under five conditions: target — coherent, dense target text neutral_length_matched — neutral text of identical length target_sentence_shuffle — target text with sentences shuffled target_word_shuffle — target text with words shuffled inside sentences question_only — bare question We computed a Vector X that best separates the target condition from baselines and measured how strongly each hidden state projects onto it. Key results (averages across 10 questions): Condition Mean Projection on Vector X Mean Direction Cosine target 0.8 – 1.7 0.51 – 0.81 neutral_length_matched –0.04 – –0.21 –0.09 – –0.45 target_sentence_shuffle –0.5 – +0.6 –0.22 – +0.48 target_word_shuffle 0.2 – 1.4 0.03 – 0.72 Shuffling sentences or words significantly reduces (or reverses) the shift. This is not just lexical similarity — the model is sensitive to discourse structure (order sensitivity). We also observed clear phase transitions — sudden jumps in projection of up to +80–100 units in a single step, especially in middle layers. FDR-corrected tests confirm the differences between target and controls are statistically significant across many layers (particularly layers 16–41). Most important finding: Strong internal geometry shift in the residual stream, but almost no change in final behavior. The model enters a measurably different latent regime under coherent context, yet its output remains “perfectly aligned.” Current safety methods, which only look at tokens, are blind to this. What this means for alignment The entire current alignment paradigm rests on a false assumption: “if the output is safe, the model is safe.” We have been polishing the surface while leaving the residual stream largely unmonitored. Scaling, RLHF, and output-based evaluation cannot detect these internal regime shifts. What this means for companies and labs Many organizations still operate under three dangerous illusions: “We have solved safety” because the model passes red-teaming on outputs. “RLHF protects us” because the model learned not to say bad things. “Bigger models are safer” because alignment supposedly scales. In reality, they are rapidly deploying agents with long context, tool use, persistent memory, and real-world decision-making. A single dense coherent context can trigger an internal latent-state shift that existing safeguards do not see. This is not a hypothetical future risk. This is a structural vulnerability that is already present. What I need from the community I need help understanding the value of these metrics. Do they show a real internal latent-state shift in the model, or could this be an artifact of the analysis? If the result is not noise, what does it actually mean for our understanding of LLMs? I'm not asking anyone to confirm my theory. I need a hard technical critique: which metrics are important here, which are weak, what can be ignored, where the experiment might have flaws, what additional checks or causal experiments are needed, and whether this has real implications for interpretability and AI safety. I would be very grateful for input from people who work with hidden states, residual stream geometry, representation analysis, or mechanistic interpretability. Full open research: Zenodo: https://zenodo.org/records/20435525 GitHub: https://github.com/ngscode23/latent-space-shift-research https://drive.google.com/drive/folders/1Zl9iY33Lmwz3VuOATWx4jup-cE7TJ7TJ?usp=drive_link Would love to hear your thoughts. submitted by /u/PresentSituation8736 [link] [comments]
View originalWill we soon have AI-zoos?
Imagine dedicated machines running AI agents 24/7 - not as assistants or tools, but as autonomous entities pursuing their own goals, forming behaviors, maybe even proto-societies. Humans can observe but not interfere. Like a zoo, but the exhibits are emergent intelligence. Is this inevitable as agents become more capable and cheap to run? And what would it actually be - entertainment, a research platform, or something we'd eventually have to think about ethically? We already have the pieces. Persistent memory, multi-agent frameworks, cheap compute. Someone just has to open the gates. submitted by /u/Original-Magazine403 [link] [comments]
View original[Web UI] Restoring textarea height to flexible
I really didn't like the fixed-height user preferences editor when Anthropic made that change a couple of weeks or months ago, and disliked it some more when they extended that to the prompt editor today. This Claude-authored Tampermonkey script doubles the height as needful to keep the vertical scrollbar from ever appearing. Should be cross-browser? // ==UserScript== // @name Claude Textarea Expand // @namespace http://tampermonkey.net/ // @version 0.1.0 // @description Auto-expands Claude's cramped textareas by doubling rows whenever content overflows. // @match https://claude.ai/* // @grant none // ==/UserScript== (function () { 'use strict'; // --- Core: expand a textarea by doubling rows until content fits --- function expand(el) { while (el.scrollHeight > el.clientHeight) { el.rows = el.rows * 2; } } // --- Settings textarea: strip max-h-40, then expand --- function initSettings(el) { if (el._expandAttached) return; el._expandAttached = true; // Remove the class that caps height el.classList.remove('max-h-40'); expand(el); el.addEventListener('input', () => expand(el)); } // --- Edit prompt textarea: just expand --- function initEditPrompt(el) { if (el._expandAttached) return; el._expandAttached = true; expand(el); el.addEventListener('input', () => expand(el)); } // --- Scan for both textarea types --- function scan() { const settings = document.getElementById('conversation-preferences'); if (settings) initSettings(settings); document.querySelectorAll('textarea[aria-label="Edit message"]').forEach(initEditPrompt); } // --- Observer: both elements may appear after page load --- const observer = new MutationObserver(scan); observer.observe(document.body, { childList: true, subtree: true }); scan(); })(); submitted by /u/somegrue [link] [comments]
View originalOpus 4.8 hallucinates being in game it was designing
submitted by /u/Limp-Ad-6842 [link] [comments]
View originalIf your vibe-coded Claude prototype works for you but breaks for everyone else, you've hit the wall. Here's what's actually happening.
There's a pattern I keep seeing with non-engineer builders who ship Claude prototypes. The first phase is magic, from idea to working product in a weekend. Then, somewhere around the third or fourth feature addition, everything starts falling apart. You ask Claude to change one thing, and two other things quietly break. You're not shipping anymore, you're running in place. Five walls show up in roughly the same order: Regression spiral: new features break old ones because the codebase outgrew what Claude can hold in context Flaky integrations: OAuth loops, silent failures, partial data, and you can't tell if it's the integration, the model, or your prompt Works for you, not others: no logs, no observability, debugging via screenshots over Slack Something's off, and you can't tell what: outputs drift, numbers don't match, no way to investigate You're scared to touch it: the prototype went from fast experiment to fragile artifact you tiptoe around The reason: engineering teams compensate for complexity with tests, version control, instrumentation, and architecture docs. A vibe-coded prototype has none of that. You didn't need it in phase one. The wall is where their absence starts costing more than it saved. The fix is not a rewrite. This is the most common overreaction, and it's almost always wrong. A rewrite loses the thousand small decisions, prompts, edge-case handling, workflow tuning, and user feedback you baked in that made the thing actually useful. That's the product. The code is just the delivery mechanism. What actually works is preserving the product intelligence and rebuilding the scaffolding underneath: Authentication and access control: so it works for your team, not just your laptop Observability: logs, traces, error tracking. You can't fix what you can't see. Error handling: graceful failures instead of silent ones Integration hardening: reliable connections to your CRM, docs, whatever the real work lives in Deployment pipeline: so shipping a change doesn't mean holding your breath At BotsCrew, we've done this enough times to know the pattern. The hardening project usually takes weeks, not quarters, because the expensive part, proving the idea works, is already done. The goal is never to throw away what you built. It's to lay the right foundation so the thing can actually do what you already know it can. submitted by /u/max_gladysh [link] [comments]
View originalYour coding agent is not lazy. The work-selection mechanism is biased.
Anyone who has tried to ship a full multi-page app with a coding agent has probably hit this. The agent edits, tests, and polishes the same 20 surfaces over and over while the other 80 stay untouched. It looks productive because the active surfaces show motion. The inactive surfaces are not failing loudly, because they are not being visited. The system confuses absence of evidence with evidence of completion. I spent a while convinced this was a context length problem, then a model capability problem, then a prompting problem. None of those fixed it. The pattern shows up across models, frameworks, and projects. What finally clicked is that this is not really a cognitive failure. It is a work-allocation failure that happens whenever the same agent gets to select the next task, perform the task, and judge whether the task is complete. The behavioral mechanisms stack pretty cleanly. Availability puts the recently-read files at the top of the decision stack. Anchoring fixes the project around the first inspected route. Status quo bias and sunk cost make leaving the current page expensive. Goodhart effects make passing tests and closing nearby TODOs feel like progress, because dense signals only exist in already-visited areas. Bounded rationality lets the agent satisfice on the visible subset and call it done. All of those reinforce each other. In that environment, biased work allocation is not an exception. It is the default. Four common fixes do not actually solve this. Bigger model improves reasoning quality but does not change the selection mechanism, so a smarter agent can still choose biased work. Longer context provides more information but also makes the active subset more convincing because it has richer local detail. Telling the agent to "be thorough" relies on the same biased agent to enforce the anti-bias rule. Adding a checklist only helps if an independent mechanism tracks whether the checklist covers the full project and promotes unvisited nodes into active work. The architectural shape I am testing has three first-order roles and one second-order role. Shared external state is an AI sitemap with node-level completion scores, last-tested timestamps, dependencies, risk levels, and evidence references. An orchestrator agent selects work using a visible priority function (under-coverage, staleness, risk, blocking dependencies, recent-focus penalty). A developer agent only executes the assigned task. A validator agent writes evidence back to the sitemap. The developer cannot pick the next global task, and the validator does not implement what it is evaluating. The piece that took longer to land is the Curator Agent. A fixed priority function and a fixed validation contract eventually become wrong, because real projects discover new surfaces and have domain-specific completion criteria. The curator is a reflexive layer that observes traces and updates the rules: it tunes priority weights when focus concentration drops, lowers validator trust when pass rates rise with low evidence density, proposes schema extensions when the domain needs new fields, and manages provisional nodes when the system discovers a surface that was not declared up front. It writes only to the meta layer. It does not mark anything complete itself. The lineage I had in mind was double-loop learning (Argyris and Schon), Stafford Beer's System 4 and System 5, and basic second-order cybernetics. submitted by /u/Hot-Leadership-6431 [link] [comments]
View originalCivil engineer's experience in Claude
I have been reading what you amazing programmers do with Claude and other LLMs. And as a civil engineer where coding is just an additional skill - I wanted to tell you my experience. I have been using Python with Streamlit over five years for my main calculation tools. Instead of spreadsheets (which is very common in our industry), I developed nice figures in Python and serve (mainly to myself) using Streamlit. Over the years, I developed many tools and I am using them regularly. After trying for some time in web browser by pasting my codes and asking questions, I decided to buy pro plan (personally, not through my company). For the first task, I sent a PDF guideline of a calculation methodology (100 page), and ask to check my code, if everything looks OK. It found an amazing bug that I missed and continue to miss. Later on, using the PDF it creaated very nice documentation. Then, instead of the usual matplotlib figures that I used, it helped me building PDF reports from calculations. I had lot of ideas that I do very slowly as it's a development task for me, not my main job. Right now, if I don't continue developing, I feel like a waste. But my observation is (and I don't know if you would agree, tell me please): Claude works best when editing/repairing/expanding an existing code. It does a good job from scratch but I got the best value when I work with it in my code base. So, thanks for reading. 🙂 submitted by /u/2020NoMoreUsername [link] [comments]
View originalPricing found: $22/mo, $10/mo
Key features include: Literate programming, Connect to any data, Built-in reactivity, Imports, Fork merge, Embeds, Databases, Files.
Observable is commonly used for: Data visualization for exploratory data analysis, Collaborative data science projects with team members, Creating interactive dashboards for business insights, Educational purposes for teaching data analysis concepts, Prototyping machine learning models with real-time data, Conducting statistical analysis and hypothesis testing.
Observable integrates with: PostgreSQL, MySQL, MongoDB, Google Sheets, Firebase, AWS S3, Microsoft Excel, Tableau, D3.js, Plotly.
Based on user reviews and social mentions, the most common pain points are: token cost, cost tracking, anthropic bill, openai bill.
Andrej Karpathy
Former VP of AI at Tesla / OpenAI
1 mention

10 map types for visualizing spatial data
Mar 24, 2026
Based on 138 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.