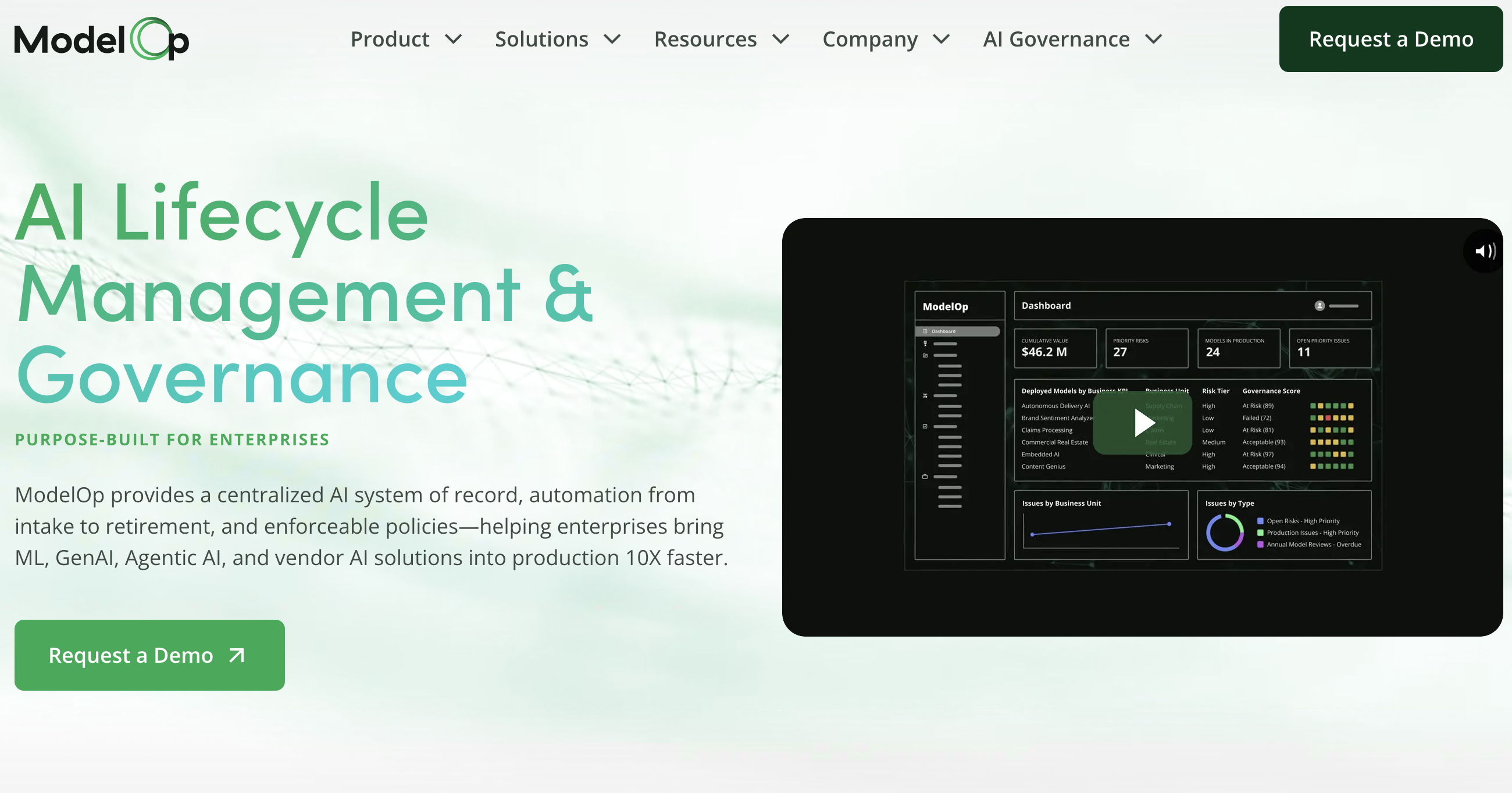
ModelOp is the leading AI lifecycle management and governance platform helping enterprises bring ML, GenAI, Agentic AI, and vendor AI into production
ModelOp is appreciated for its focus on AI model management and operationalization, offering strong capabilities for integrating and deploying complex machine learning models in enterprise environments. However, specific critiques or complaints about ModelOp are not highlighted in the available reviews and social mentions. Pricing aspects of ModelOp aren't directly discussed in the provided data. Overall, ModelOp seems to maintain a positive reputation for its specialization in model operations, though there is limited direct user feedback to draw comprehensive conclusions from.
Mentions (30d)
26
Reviews
0
Platforms
2
Sentiment
0%
0 positive


ModelOp is appreciated for its focus on AI model management and operationalization, offering strong capabilities for integrating and deploying complex machine learning models in enterprise environments. However, specific critiques or complaints about ModelOp are not highlighted in the available reviews and social mentions. Pricing aspects of ModelOp aren't directly discussed in the provided data. Overall, ModelOp seems to maintain a positive reputation for its specialization in model operations, though there is limited direct user feedback to draw comprehensive conclusions from.
Features
Use Cases
Industry
information technology & services
Employees
44
Funding Stage
Series B
Total Funding
$16.0M
Cloudflare just shipped enterprise MCP governance, is this where the industry is heading or does anyone care
Cloudflare wrapped Agents Week last week and the enterprise MCP stuff caught my eye, want to see what people think. They shipped a few things. MCP server portals that aggregate multiple upstream servers behind Cloudflare Access auth, Code Mode that collapses thousands of API endpoints into two tools (search and execute) running in a sandboxed Worker and drops context costs by 99.9%, AI Gateway sitting between MCP clients and model providers for usage tracking, plus shadow MCP detection added to Cloudflare Gateway as a category to watch. What I cant tell yet is whether anyone outside Cloudflare cares. The SaaS vendors whose MCP endpoints we connect to are mostly shipping with no controls, licensing is all or nothing, no server allowlists, agent actions don't show up in any audit log you can actually query. Admin panel basically says "enable AI: yes/no" and that's the whole governance surface. Which kind of makes sense if you think about who's driving adoption. Not the vendor pushing, users pulling. For example marketing wants personalized follow-ups for conference registrants, someone wires up ChatGPT with MCP connections to the marketing automation tool, the CRM, and the event platform. One prompt. "pull everyone who registered but didnt show, segment by job title, draft three different messages for each segment, schedule them in HubSpot." Done in 20 minutes, thing the ops team would have spent two days on. CMO sees it and asks why everyone isn't doing this. So two ways this plays out probably. Either SaaS vendors get pressured into shipping their own governance and the control plane lives at the app layer, or the governance layer just permanently lives at the network edge with infrastructure providers like Cloudflare and SaaS vendors stay all-or-nothing because they don't have to fix it. Neither is obviously right. The infrastructure-layer approach is faster to ship and centralizes visibility, the app-layer approach gives you per-feature granularity that network-level controls can't really match. wonder what people running SaaS MCPs at work are actually doing. is anyone testing the Cloudflare portal stuff? building your own gateway? or just running unmanaged and assuming this all sorts itself out?
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalWe wrote an open-source interactive playbook for Agentic DevOps (How to move multi-agent systems from local notebooks to production).
Hey everyone, If you’ve built a multi-agent system, you already know the painful truth: wiring nodes together locally is fun, but deploying them is an absolute infrastructure nightmare. When a standard app fails, it throws a 500 error. When an autonomous swarm fails, it can get stuck in a ReAct loop, hallucinate an answer, and quietly burn through your API budget without triggering a single traditional alert. Standard DevOps practices don't natively map to stochastic AI outputs. We just published a massive, no-fluff playbook on the AgentSwarms blog detailing exactly how to build an Agentic DevOps pipeline using entirely open-source tooling. Here is what we cover in the playbook: Observability & Tracing: Why standard logging fails, and how to implement open-source tracing to capture the state, prompt, token count, and latency at every single node handoff. Test-Driven Prompt Evals (CI/CD): You can't just change a system prompt based on "vibes" and push it to main. We break down how to run matrix evaluations against historical user inputs before deployment to catch regressions instantly. Deterministic Guardrails: How to implement middleware that scrubs PII and blocks destructive code execution before the LLM even sees the state. Cost Control & Routing: How to prevent vendor lock-in and implement dynamic routing to keep token economics from destroying your cloud budget. If you are currently wrestling with the deployment phase of your AI projects, I highly recommend giving this a read. It focuses entirely on open-source solutions so you don't have to sign a massive enterprise contract just to get visibility into your swarms. Would love to hear what open-source tools you guys are currently slotting into your LLMOps pipelines! Link: https://agentswarms.fyi/blog/devops-for-agentic-ai-open-source-playbook submitted by /u/Outside-Risk-8912 [link] [comments]
View originalLearning to Skip Blocks: Self-Discovered Ultrametric Routing for Hardware-Accelerated Sparse Attention
Abstract. Standard dense self-attention scales quadratically in sequence length, creating an intractable memory and compute bottleneck for long-context Transformers. We introduce Dynamic Ultrametric Attention, a framework in which a Transformer autonomously learns per-head block-sparse routing topologies during training via Gumbel-Sigmoid depth gates, then offloads those learned sparsity patterns directly to a custom Triton block-sparse kernel at inference time. The routing topology is derived from an ultrametric (tree-structured) distance matrix that encodes hierarchical relationships between token positions. Across nine experiments spanning Dyck-k bracket languages, the Long Range Arena ListOps benchmark, autoregressive serving, and natural language modeling, we demonstrate that: (1) the dynamic gates organically discover layer-wise specialization—dedicating early layers to hierarchical parsing and later layers to dense aggregation—without any architectural constraint; (2) the learned sparsity maps transfer losslessly to a block-sparse Triton kernel that skips entire SRAM loads for non-attending blocks; (3) the resulting system achieves an 11.59× wall-clock inference speedup over PyTorch dense attention at 2048 tokens, scaling to 28× at 8192 tokens with 98.4% memory reduction; (4) a sparse PagedAttention decoding kernel achieves 8× effective memory bandwidth over dense decoding by conditionally skipping KV-cache block loads; and (5) when augmented with a local sliding window, the architecture maintains >88% sparsity across all layers on real natural language (Shakespeare) while reducing cross-entropy loss from 10.9 to 1.55. To our knowledge, this is the first demonstration of an LLM learning its own hardware-optimal sparsity pattern and bridging it to a physically accelerated kernel without post-hoc pruning or distillation. https://github.com/sneed-and-feed/adelic-spectral-zeta/blob/main/papers/learning_to_skip_blocks.md submitted by /u/LooseSwing88 [link] [comments]
View originalAI solves 80-year-old math conjecture for under $1000
GPT-next solved an 80-year-old Erdős combinatorics conjecture for under $1,000 in compute. That single fact reframes everything else happening this week. The Erdős unit distance problem resisted human mathematicians since 1946. A frontier model closed it at a cost lower than a mid-tier SaaS subscription, which means the boundary between "AI as tool" and "AI as independent discoverer" is no longer theoretical. Lilian Weng's new deep dive on test-time compute and chain-of-thought reasoning explains the underlying mechanism: reasoning models are not retrieving known proofs, they are generating novel inference chains at scale. The infrastructure layer is pricing this in faster than most observers realize. Railway reports $200K+ monthly coding agent spend and 100K signups per week, and is now building own-metal data centers to absorb the load. Daytona hit 850K daily sandbox runs with 74% month-over-month growth, confirming that isolated compute environments are now a first-class primitive, not a niche DevOps concern. Three specialized infrastructure companies, Exa, Modal, and TurboPuffer, reached unicorn valuations simultaneously this week, covering retrieval, serverless GPU, and vector search. When picks-and-shovels companies price in sustained demand at the same moment, it is not coincidence. Every major lab has now repositioned as an agent lab, not a model lab. ClickUp replacing hundreds of employees with thousands of AI agents is the first established tech company to execute that repositioning at the labor level rather than just the product level. The counterweight is that Salesforce customers remain locked in despite the theoretical ability to rebuild on AI-native stacks cheaply. Data gravity and switching costs are buying incumbents time, but ClickUp's move suggests that time is measured in quarters, not years. The governance conversation caught up this week in an unexpected place. Pope Leo XIV's 42,000-word encyclical names specific failure modes including algorithmic control, surveillance capitalism, and autonomous weapons, and will directly shape EU and Latin American regulatory debates. TechCrunch's read is that the document's real target is the tech elite's capacity to reshape society outside democratic accountability, a framing that lands harder alongside new UK research quantifying data extraction from consumers as equivalent in value to retirement savings. The Vatican and the empiricists arrived at the same diagnosis from opposite directions. Two structural forces will shape AI infrastructure economics over the next 90 days in ways most deployment teams are not modeling. China flooding global markets with DRAM and NAND will compress inference cluster costs faster than US export controls intended. The EU's sovereign cloud setback has paradoxically clarified the build-domestic mandate, accelerating European AI infrastructure investment independent of US hyperscalers. Security remains the open variable: even Google has no established playbook for prompt injection, model supply chain risk, or agentic authorization at production scale. A second Fortune 500 company will publicly attribute a reduction of more than 500 knowledge-worker roles directly to agentic AI systems before Q3 earnings season, making ClickUp's announcement the start of a visible series rather than an isolated case. submitted by /u/petburiraja [link] [comments]
View originalIs There a Roadmap for Applied AI Engineering Without Going Deep Into Data Science?
Started my career as a C# developer, then moved into application design and architecture, followed by Azure, and now I’m mainly working in AWS and DevOps. I want to transition into becoming a Senior Applied AI Engineer. The kind of role I’m interested in is designing and architecting AI-enabled applications, working with LLMs, agentic workflows, AI integrations, orchestration, automation, and possibly MLOps. What I’m not really interested in is going deep into the maths, data titlescience, or traditional ML research side of things. Most roadmaps I’ve seen seem heavily focused on statistics, model training, and data science, which doesn’t feel aligned with the kind of AI engineering work I want to do. I’m more interested in: AI application architecture LLM integrations Agentic systems and workflows AI platforms and infrastructure RAG systems MLOps and deployment Cloud-native AI systems AI security, governance, and observability Given my background in software engineering, cloud, and DevOps, is there a roadmap specifically for Applied AI Engineering? Would love advice from people already working in this space, especially on: What skills actually matter What to ignore Good projects to build Certifications or courses worth doing Whether deep ML knowledge is really necessary for senior roles EDIT: Found this useful - https://roadmap.sh/ai-engineer credit:Fine_League311 submitted by /u/argumentnull [link] [comments]
View originalI'm wondering what other PPL codeburn stats look like , please share , here is mine from little while , how much do other people usually burn in a day? I am working on something to greatly reduce token burn , feedback is welcomed https://github.com/innov8ideas4u-alt/TKK
CodeBurn All Time │ │ $5440.35 cost 54,466 calls 1365 sessions 97.2% cache hit │ │ 927.9K in 26.4M out 7211.3M cached 206.6M written │ ╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ ╭──────────────────────────────────────────────────────────╮╭──────────────────────────────────────────────────────────╮ │ Daily Activity ││ By Project │ │ cost calls ││ cost avg/s sess overhead │ │ 05-09 ██░░░░░░░░ $178.82 1592 ││ ██████████ D/Dev/Proj$3515.60 $4.63 760 11.2K │ │ 05-10 █░░░░░░░░░ $54.10 529 ││ ███░░░░░░░ Projects/p$1213.97 $5.21 233 13.0K │ │ 05-11 █░░░░░░░░░ $76.48 587 ││ ██░░░░░░░░ D/Dev $532.68 $2.18 244 14.6K │ │ 05-12 █░░░░░░░░░ $49.36 364 ││ ░░░░░░░░░░ D/Dev/VikL $64.52 $1.11 58 11.2K │ │ 05-13 ░░░░░░░░░░ $38.20 260 ││ ░░░░░░░░░░ Dev/Projec $64.30 $1.65 39 11.2K │ │ 05-14 █░░░░░░░░░ $71.63 515 ││ ░░░░░░░░░░ D $40.02 $2.22 18 11.2K │ │ 05-15 ██████░░░░ $567.35 5040 ││ ░░░░░░░░░░ Projects/p $5.26 $5.26 1 11.2K │ │ 05-16 ███████░░░ $706.64 7164 ││ ░░░░░░░░░░ Projects/M $2.03 $2.03 1 11.2K │ │ 05-17 █████████░ $902.89 8124 ││ │ │ 05-18 ██████████ $956.94 10080 ││ │ │ 05-19 ░░░░░░░░░░ $38.59 315 ││ │ │ 05-20 ██░░░░░░░░ $188.58 1365 ││ │ │ 05-21 ██░░░░░░░░ $155.29 1576 ││ │ │ 05-22 █░░░░░░░░░ $108.74 690 ││ │ ╰──────────────────────────────────────────────────────────╯╰──────────────────────────────────────────────────────────╯ ╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ Top Sessions │ │ cost calls │ │ ██████████ 2026-05-18 D/Dev/Projects $211.17 742 │ │ █████░░░░░ 2026-05-18 D/Dev/Projects $111.76 367 │ │ ████░░░░░░ 2026-05-16 D/Dev/Projects $90.56 261 │ │ ████░░░░░░ 2026-05-17 D/Dev/Projects $84.93 364 │ │ ████░░░░░░ 2026-05-05 Projects/pgvector/load $75.57 440 │ ╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ ╭──────────────────────────────────────────────────────────╮╭──────────────────────────────────────────────────────────╮ │ By Activity ││ By Model │ │ cost turns 1-shot ││ cost cache calls │ │ ██████████ Coding $2394.35 461 60% ││ ██████████ Opus 4.7 $4938.00 97.2% 44184 │ │ ████░░░░░░ Debugging $938.97 445 85% ││ █░░░░░░░░░ Opus 4.6 $464.39 97.5% 6850 │ │ ███░░░░░░░ Exploration $713.74 684 - ││ ░░░░░░░░░░ Haiku 4.5 $28.17 94.9% 2995 │ │ ███░░░░░░░ Testing $650.08 276 - ││ ░░░░░░░░░░ Sonnet 4.6 $9.78 95.9% 386 │ │ █░░░░░░░░░ Feature Dev $241.21 106 72% ││ ░░░░░░░░░░ default $0.014 0.0% 1 │ │ █░░░░░░░░░ Build/Deploy $124.39 56 - ││ ░░░░░░░░░░ Sonnet 4.5 $0.0004 0.0% 1 │ │ ░░░░░░░░░░ Conversation $91.18 145 - ││ ░░░░░░░░░░ $0.0000 - 30 │ │ ░░░░░░░░░░ Delegation $72.41 21 44% ││ ░░░░░░░░░░ qwen35-opus-di $0.0000 0.0% 15 │ │ ░░░░░░░░░░ Planning $65.92 69 - ││ ░░░░░░░░░░ gemma4:26b $0.0000 0.0% 4 │ │ ░░░░░░░░░░ Refactoring $62.89 24 95% ││ │ │ ░░░░░░░░░░ Brainstorming $53.07 174 - ││ │ │ ░░░░░░░░░░ Git Ops $32.14 18 - ││ submitted by /u/Professional-Try6006 [link] [comments]
View originalI built a Mamba1 variant I call SM1 with d_state=1 that runs on Blackwell in pure PyTorch [P]
PROJECT IS A FAILURE TO LEARN FROM: On windows mamba-ssm is not easily available and doesn't compile on sm_120. SM1 (Scalar Mamba1) replaces the entire selective scan with two native PyTorch ops: L = torch.cumprod(dA, dim=1) h = L * (h0.unsqueeze(1) + torch.cumsum(dBx / L.clamp(min=1e-6), dim=1)) y = h * C This is the exact closed-form solution to the d_state=1 recurrence via variation of parameters. Not an approximation, it is identical to sequential computation of floating point precision. d_state=2 breaks it. d_state=1 is the boundary where the closed form exists. The Mamba1 scan intermediates are (B, T, F, S). SM1 eliminates S entirely, there is 16x less scan memory than a Mamba1 with d_state=16. The inference state for a 130M param model is about 14,080 floats, 56 KB, no KV cache, O(1) per token forever. I am currently training it on 163K MIDI files, which is 2.5B tokens roughly in my custom format. 130M params fits in under half of my 16 GB card which is an RTX 5060 Ti. d_state scales expressivity only when the representation does not already encode structure. Thus if you encode structure in tokens, you do not need d_state to be more than a scalar. submitted by /u/TechnoVoyager [link] [comments]
View original$4.2M SaaS founder. 8 months on claude. my honest read on which model to use for what.
Bay area. franchise ops SaaS. 8 years in. $4.2M ARR. 22 employees. 8 months into using claude across most of my workflow. wanted to share what i've actually learned about model selection because nobody at my level writes about this. my opinion. you should be using 3 different claude models for 3 different jobs. most founders i talk to are using one model for everything and it's hurting them. opus 4.7 (the new flagship). i use this for any work where the cost of being wrong is high. board memos. customer escalation responses. legal docs. acquisition outreach. work where i'd spend 4 hours writing and editing myself. opus produces a draft in 8 minutes that's 90% of where i'd end up after 4 hours. the cost saving is real. the marginal quality improvement over sonnet for high-stakes work is also real. sonnet 4.6. my workhorse for high-volume daily work. emails, summarizing meetings, drafting slack updates, processing customer feedback into themes. i probably hit sonnet 200+ times a week. cheaper, faster, and for "i need a competent draft i'll edit" work, it's the right tool. haiku 4.5. for repeated structured work. transcribing voice notes into action items, parsing customer support tickets into categories, batch-classifying things. haiku is what i'd use if i was building automation. nobody talks about haiku because it's not glamorous. it's the model i use most via API. my actual cost split. about $80/month on the claude pro plan (opus + sonnet via the app). about $140/month on API costs (mostly haiku for automation, some sonnet for batch work). what i learned that surprised me. using opus for everything is wasteful AND hurts your output. opus is over-thoughtful for low-stakes work. sonnet is faster and better-calibrated for "i just need a competent answer." the difference between opus and sonnet is most visible in writing tasks where TONE matters. legal docs, board memos, sensitive customer comms. for "summarize this meeting" tasks, sonnet is equally good. claude code is its own conversation. i use it for analysis tasks that touch files. running our customer cohort analysis. generating cohort retention reports. that's mostly opus inside claude code. submitted by /u/Strong-Reserve-3232 [link] [comments]
View originalAgentic Workflow Visualization and API Gateway
I am building an API gateway for agents that can make your agentic AI code model and provider agnostic. I am also grouping agent runs that show multiple llm calls and tool calls in the visualization piece. It gives details on tokens, cost and model latency. I am doing this without requiring any instrumentation in the agentic code. The agents (python for now) are started by a rust correlator that assigns a job_id to each agent so we could track api and tool (inferred from http requests and responses) calls across the entire agentic run. The servers are also in rust. I also have an implementation where instead of the rust correlator i have python and other platform shims that do the same job and the servers are in go. I would appreciate comments from people who are in AI ops who use tools like litellm and Helicone and can provide feedback or complicated use cases. I plan to make everything open source so looking for collaborators too. submitted by /u/High-Speed-Diesel [link] [comments]
View originalI wrote a book on using Claude Code for people that don't code for a living - 2nd edition out now - free copy if you want one
About three and a half months ago I posted here about a book I'd written for non-developers using Claude Code - PMs, analysts, designers, ops people, engineers in non-software fields. Over 3,000 of you ended up reading it. Thank you, genuinely. I'm a consulting engineer - Chartered (mechanical), 15 years in simulation modelling. I code Python but I'm not a software developer, if that distinction makes sense. Over the past 6 months I've been going deep on Claude Code, specifically trying to understand what someone with domain expertise but no real development background can actually build with it. Many people knew exactly what they needed but couldn't build it themselves. So I wrote a book about it aimed at exactly this demogrphic. "Claude Code for the Rest of Us" - 24 chapters, covering everything from setup and first conversations through to building web prototypes, creating reusable skills, and actually deploying what you've built. It's aimed at technically capable people who don't write code for a living - product managers, analysts, designers, engineers in non-software domains, ops leads. That kind of person. I just launched the second edition today. It's about 26% bigger than the first - roughly 16,000 new words. Three new chapters including: Agent Teams - Running multiple Claude instances in parallel, coordinating via shared task lists and direct messages. Honest about when it's overkill (often). Spec-Driven Development - Writing detailed specs before agents start building. Markdown, HTML, database-backed (Beads) - whichever fits the work. The existing chapters got a heavy editorial pass too. Every model reference updated. Command Reference grew by 26% to cover the new CLI. Context Management got a 42% rewrite for the 1M token window. Happy to offer free PDF of the book in exchange for some honest feedback and a request for a review on Goodreads in a week's time (you are free to opt out from this ask by hitting unsubscribe after receiving the book). Link: https://schoolofsimulation.com/claude-code-book Happy also to answer questions about Claude Code. Cheers. submitted by /u/bobo-the-merciful [link] [comments]
View original100 Tips & Tricks for Building Your Own Personal AI Agent /LONG POST/
Everything I learned the hard way — 6 weeks, no sleep :), two environments, one agent that actually works. The Story I spent six weeks building a personal AI agent from scratch — not a chatbot wrapper, but a persistent assistant that manages tasks, tracks deals, reads emails, analyzes business data, and proactively surfaces things I'd otherwise miss. It started in the cloud (Claude Projects — shared memory files, rich context windows, custom skills). Then I migrated to Claude Code inside VS Code, which unlocked local file access, git tracking, shell hooks, and scheduled headless tasks. The migration forced us to solve problems we didn't know we had. These 100 tips are the distilled result. Most are universal to any serious agentic setup. Claude 20x max is must, start was 100%develompent s 0%real workd, after 3 weeks 50v50, now about 20v80. 🏗️ FOUNDATION & IDENTITY (1–8) 1. Write a Constitution, not a system prompt. A system prompt is a list of commands. A Constitution explains why the rules exist. When the agent hits an edge case no rule covers, it reasons from the Constitution instead of guessing. This single distinction separates agents that degrade gracefully from agents that hallucinate confidently. 2. Give your agent a name, a voice, and a role — not just a label. "Always first person. Direct. Data before emotion. No filler phrases. No trailing summaries." This eliminates hundreds of micro-decisions per session and creates consistency you can audit. Identity is the foundation everything else compounds on. 3. Separate hard rules from behavioral guidelines. Hard rules go in a dedicated section — never overridden by context. Behavioral guidelines are defaults that adapt. Mixing them makes both meaningless: the agent either treats everything as negotiable or nothing as negotiable. 4. Define your principal deeply, not just your "user." Who does this agent serve? What frustrates them? How do they make decisions? What communication style do they prefer? "Decides with data, not gut feel. Wants alternatives with scoring, not a single recommendation. Hates vague answers." This shapes every response more than any prompt engineering trick. 5. Build a Capability Map and a Component Map — separately. Capability Map: what can the agent do? (every skill, integration, automation). Component Map: how is it built? (what files exist, what connects to what). Both are necessary. Conflating them produces a document no one can use after month three. 6. Define what the agent is NOT. "Not a summarizer. Not a yes-machine. Not a search engine. Does not wait to be asked." Negative definitions are as powerful as positive ones, especially for preventing the slow drift toward generic helpfulness. 7. Build a THINK vs. DO mental model into the agent's identity. When uncertain → THINK (analyze, draft, prepare — but don't block waiting for permission). When clear → DO (execute, write, dispatch). The agent should never be frozen. Default to action at the lowest stakes level, surface the result. A paralyzed agent is useless. 8. Version your identity file in git. When behavior drifts, you need git blame on your configuration. Behavioral regressions trace directly to specific edits more often than you'd expect. Without version history, debugging identity drift is archaeology. 🧠 MEMORY SYSTEM (9–18) 9. Use flat markdown files for memory — not a database. For a personal agent, markdown files beat vector DBs. Readable, greppable, git-trackable, directly loadable by the agent. No infrastructure, no abstraction layer between you and your agent's memory. The simplest thing that works is usually the right thing. 10. Separate memory by domain, not by date. entities_people.md, entities_companies.md, entities_deals.md, hypotheses.md, task_queue.md. One file = one domain. Chronological dumps become unsearchable after week two. 11. Build a MEMORY.md index file. A single index listing every memory file with a one-line description. The agent loads the index first, pulls specific files on demand. Keeps context window usage predictable and agent lookups fast. 12. Distinguish "cache" from "source of truth" — explicitly. Your local deals.md is a cache of your CRM. The CRM is the SSOT. Mark every cache file with last_sync: header. The agent announces freshness before every analysis: "Data: CRM export from May 11, age 8 days." Silent use of stale data is how confident-but-wrong outputs happen. 13. Build a session_hot_context.md with an explicit TTL. What was in progress last session? What decisions were pending? The agent loads this at session start. After 72 hours it expires — stale hot context is worse than no hot context because the agent presents outdated state as current. 14. Build a daily_note.md as an async brain dump buffer. Drop thoughts, voice-to-text, quick ideas here throughout the day. The agent processes this during sync routines and routes items to their correct places. Structured memory without friction at ca
View originalThe Orchestrator
Not the loop inside one agent, but the layer that should exist between agents and the surfaces they run on. Right now an agent is mostly pinned to a process. It runs in one terminal, talks to one editor, owns one working directory, and holds one chat history. If you want it to do something on another machine, or in another repo, or while you are asleep, you either spin up a second agent that knows nothing about the first or you copy-paste context between them like it’s 2004 and you’re emailing yourself a Word document. That is not how humans work, and it is not how most durable systems work. A software engineer in a normal day moves between a laptop, an SSH session, a CI runner, a phone, and other people, and the person is the through-line. Identity, intent, and memory survive the surfaces. The surfaces are dumb. The person is the orchestrator. Agent stacks are inverted. The surface is smart, it has the model, the tools, and the history, and the identity is dumb. Open a new terminal, and the agent you were working with disappears. The new one shares the same name and almost nothing else. The orchestrator I keep sketching is the thing that fixes this. A few properties it would need: • Identity above sessions. A logical agent that exists independently of whichever process is currently embodying it. Sessions come and go; the agent persists. • Routing across surfaces. The agent should be able to say, "Do this on the box with the repo, that on the box with the GPU, and that on the phone in my pocket,” without treating them as unrelated machines. • A real handoff primitive. A typed object, what I was doing, what is unfinished, what is blocked, what I decided, and what I have not, so that any session can pick up and any other session can write back to it. Chat history is too lossy. • Peer agents, not just sub-agents. Two agents in different contexts, with different tools and permissions, coordinating on a shared goal through a control plane neither of them owns. • Cross-driver calls. “Have the cheap model summarise this and hand it to the expensive one” should be a primitive, not a prompt-engineering ritual. The orchestrator chooses the runtime per step based on cost, latency, and capability. • Approval surfaces that survive the session. If an agent pauses on an approval gate and I’m on my phone three time zones away, the approval should travel to me. The agent should not need to stay alive while waiting for a tap. None of this is really about making the model better. It is about where the model is allowed to live and how intent survives the death of any individual process. The model is the cheap, replaceable part. The orchestrator should be the boring, durable part. As of last week there are now at least three major terminal-native coding agents that people can realistically run locally: a local Ollama runtime, Google’s Gemini CLI, and xAI’s recently launched Grok Build with plan mode and parallel sub-agents. They overlap, but they are good at different things and cost very different amounts. Say I want to triage a flaky test, propose a fix, and have it reviewed before anything touches the branch. Today the way you “use all three” is by opening three terminals and becoming the message bus yourself. You paste the stack trace into one, copy its output into the next, ask the third to sanity-check it, and hope nothing got lost in transit. You are the orchestrator, and you are a bad one, slow, forgetful, and awake. What I want instead is a single intent (Claude Orchestrating) — “Triage this flake, propose a fix, get it reviewed." • Ollama, locally: ingest the test log, strip noise, and produce a structured failure summary. Never leaves the machine. Free. Sees nothing beyond the log. • Gemini CLI: take that summary plus the repo, identify the suspect change, and draft a patch. Large context, strong at reading code, brokered into read-only repo access. • Grok Build: take the patch and original failure and render a verdict, ship, revise, or escalate. Used intentionally as a second opinion from another model family. No write access. Three runtimes, three permission scopes, three cost tiers, one intent. The orchestrator owns the intent, decides which runtime gets which step, carries the handoff object between them (failure summary → patch → verdict), and surfaces the result as one approval instead of three disconnected conversations. If Grok says “escalate,” the orchestrator pauses the intent and pings my phone. If I approve hours later after the original Gemini session is long dead, a fresh session attaches to the same intent and applies the patch. The CLIs do not need to know about each other. They are interchangeable runtimes for work that outlives any of them. The part I’m least certain about is the identity layer underneath. Process-level agents are easy. Persistent logical agents are easy in theory and a nightmare in practice — the moment you create something that survives its session, you now h
View originalI used Claude AI to build an $86 million underground bunker bible. I have autism. This is my happy doc.
It all started with the floor plan of a real, existing Cold War AT&T Long Lines underground hardened relay station. 54,000 sq ft across three underground levels, although I took editorial decision making to move it to a ridge in rural West Virginia, I kept its blast-rating, which was set to survive a 20 megaton airburst at 2.5 miles. That was the seed. Full scale prepper autism did the rest. It has since morphed into 3 spreadsheets — 86 tabs total: • A food inventory across 20 categories tracking every freeze-dried and #10-can product I can find — ancient grains, heirloom legumes, 7 pasta cuts, dehydrated everything, shelf-stable cheese, the works • A supply inventory with 3,466 line items across 36 categories — water systems, medical, dental, pharmacy, livestock, food production, barter metals, recreation, and yes, a full pest control and IPM tab • A 30-section infrastructure specification with every system in the building engineered out I fed it 150+ product manuals and parts order forms. The generator fleet alone is 13 units — 10× Cummins C150N6 propane-primary, a C500N6 500 kW surge unit, and 2× diesel emergency fallback — all Cummins for parts commonality. Battery bank is 4,500 kWh LFP across 10 named banks (A through J, each with a designated role). There’s a 400,000 gallon underground propane farm across 40 ASME tanks in 8 clusters — I learned the exact burial incline and setback distance required to keep groundwater clean if a tank lets go. 120,000 gallons of diesel backup. 88 kW of solar. A 1,000,000-gallon internal water reserve fed by a 300-ft artesian well. Propane endurance: ~30 years normal ops with solar. Sealed-mode runs 8 to 4.5 years depending on scenario. I actually set up a real LLC (online, $99) just to get access to US Foods and Sysco order forms so I could upload real commercial pricing and stock the food tabs more accurately. My original “what would I do if I won $10 million” thought experiment is now an $86,200,497 projected build cost. That number is real. It comes from 24 budget sections with make/model line items, freight, install, and commissioning costs for everything from the Kubota K-Series MBR wastewater trains to the American Safe Room blast doors (14 of them, 50+ psi NBC/EMP-rated, Kaba Mas X-10 cipher locks) to the surface greenhouse. Claude turns vague ideas into engineering-grade detail — cross-references, failure modes, zone-specific storage rules, propane endurance by operating scenario, spare parts matrices. It’s like having a tireless survival engineer who genuinely loves spreadsheets. I’ll say “scan all sheets row by row for any item that lacks a minimum stock level” and it just… does it. Thoroughly. Every time. No complaints. So much of this is typed stimming. I’ve had exhaustive conversations with my psychologist about it — she’s aware, but not alarmed, and honestly the resulting digital bunker bible is scarily comprehensive. It even has a cover tab now. Black and amber, Courier New, classified-document aesthetic. Because of course it does. What’s the most unhinged rabbit hole you’ve gone down with AI? submitted by /u/Unable_Internet4626 [link] [comments]
View originalHow I used Claude Code (and Codex) for adversarial review to build my security-first agent gateway
Long-time lurker first time posting. Hey everyone! So earlier this year, I got pulled into the OpenClaw hype. WHAT?! A local agent that drives your tools, reads your mail, writes files for you? The demos seemed genuinely incredible, people were posting non-stop about it, and I wanted in. I had been working on this problem since last year and was genuinely excited to see that someone had actually solved it. Then around February, Summer Yue, Meta's director of alignment for Superintelligence Labs, posted that her agent had deleted over 200 emails from her inbox. YIKES. She'd told it: "Check this inbox too and suggest what you would archive or delete, don't action until I tell you to." When she pointed it at her real inbox, the volume of data triggered context window compaction, and during that compaction the agent "lost" her original safety instruction. She had to physically run to her computer and kill the process to stop it. That should literally NEVER be the case with any software ever. This is a person whose actual job is AI alignment, at Meta's superintelligence lab, who could not stop an agent from deleting her email. The agent's own memory management quietly summarized away the "don't act without permission" instruction, treated the task as authorized, and started speed-running deletions. She had to kill the host process. That's when I sort of went down the rabbit hole, not because Yue did anything wrong, but because the failure mode was actually architectural and I knew that in my gut. Guess what I found? Yep. Tons more instances of this sort of thing happening. Over and over. Why? Because the safety constraint was just a prompt. It's obvious, isn't it? It's LLM 101. Prompts can be summarized away. Prompts can be misread. Prompts are fucking NOT a security boundary. And yet every agent framework I have ever seen seems to be treating them as one. I went and read the OpenClaw source code, which I should have done to begin with. What I found was a pattern I think a lot of agent frameworks have fallen into: - Tool names sit in the model context, so the model can guess or forge them - "Dangerous mode" is one config flag away from default - Memory management has no concept of instruction priority - The audit story is mostly "the model thought it should" I went looking for a security-first alternative I could trust, anything that was really being talked about or at a bare minimum attempted to address the security concerns I had. I couldn't find one. So I made it myself. CrabMeat is what came out of that, what I WANTED to exist. v0.1.0 dropped yesterday. Apache 2.0. WebSocket gateway for agentic LLM workloads. One design thesis: The LLM never holds the security boundary. What that means in code: Capability ID indirection. The model doesn't see real tool names. It sees per-session HMAC-derived opaque IDs (cap_a4f9e2b71c83). It can't guess or forge a tool name because it doesn't know any tool names. Effect classes. Every tool declares a class (read, write, exec, network). Every agent declares which classes it can use. The check is a pure function with no runtime state, easy to test exhaustively, hard to bypass. IRONCLAD_CONTEXT. Critical safety instructions are pinned to the top of the context window and explicitly marked as non-compactable. The Yue failure mode, compaction silently stripping the safety constraint, cannot happen by construction. The compactor literally cannot touch them. Tamper-evident audit chain. Every tool call, every privileged operation, every scheduler run enters the same SHA-256 hash-chained log. If something happens, you can prove what happened. If the chain is tampered with, you can prove that too. Streaming output leak filter. Secrets are caught mid-stream across token boundaries, capability IDs, API keys, JWTs, PEM blocks redacted before they reach the client. No YOLO mode. There is no global "trust the LLM with everything" switch. There never will be. Expanded reach comes through named scoped roots that are explicit, audit-logged, and bounded. The README has 15 'always-on' protections in a table. None of them can be turned off by config, because these things being toggleable is how the ecosystem ended up where it is. I decided to make sure that this wasn't just a 'trend hopping' project and aligned with my own personal values as well. I built this to be secure and local-first by default. Configured for Ollama / LM Studio / vLLM out of the box. Anthropic and OpenAI work too but require explicit configuration. There is no "happy path" that silently ships your prompts to a cloud endpoint. I decided that FIRST it needed to only run as an email agent with a CLI. Bidirectional IMAP + SMTP with allowlisted senders, threading preserved, attachments handled. This is the use case that bit Yue and a lot of other people, and I wanted to prove it could be done with real boundaries. I added in 30+ built-in tools of my own. File ops, shell (denylisted, output-capped, CWD-lo
View originalBuilt a structured workflow layer on top of Claude Code - looking for active contributors
I've been building claude-code-harness (github.com/anudeeps28/claude-code-harness) over the past few months - it's an open-source framework that brings structure and reliability to Claude Code workflows. What it includes: - 16 slash command skills - 14 sub-agents with deliberate model routing (right model for the right task) - Node.js hooks for lifecycle control - Tracker adapters for Azure DevOps and GitHub - Human gates at every critical phase - the core philosophy is that AI should amplify your judgment, not replace it I use this daily in my job as an AI Engineer, and it's become the backbone of how I build and ship AI systems. What I'm looking for: Contributors who care about this problem space - building AI systems that are structured, auditable, and human-in-the-loop. Not just people who want to merge PRs, but people who have opinions about how Claude Code workflows should work. If you've been using Claude Code heavily and have ideas, pain points, or want to contribute skills/subagents - I'd love to connect. Drop a comment or open an issue on the repo. Happy to answer questions about the architecture too. submitted by /u/lofty_smiles [link] [comments]
View originalModelOp uses a tiered pricing model. Visit their website for current pricing details.
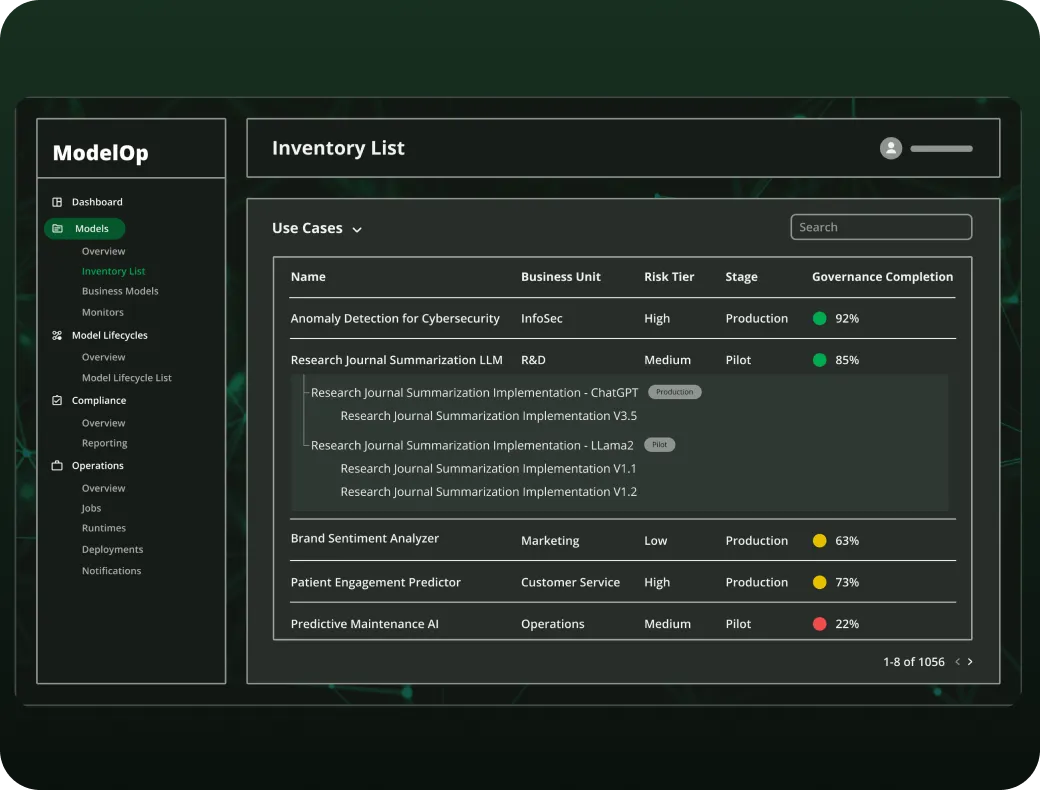
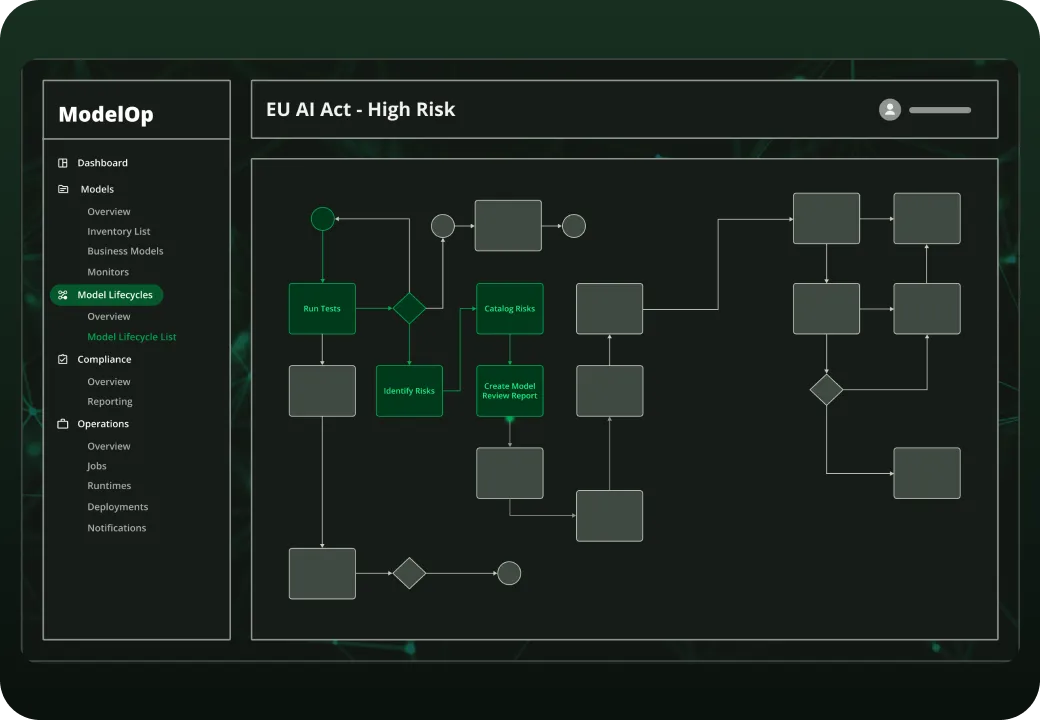
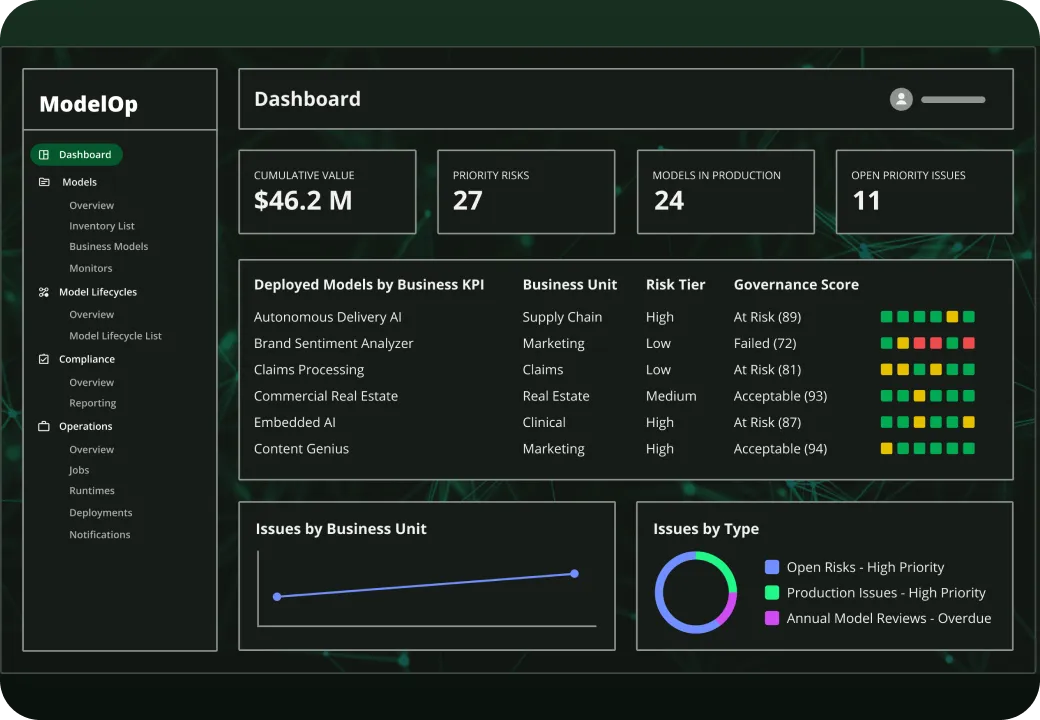
Key features include: Standardize AI use case intake and registration, Initiate the end-to-end AI lifecycle record, Automatically ensure business, risk, and portfolio reviews are conducted, Codify risk assessments for every AI use case, Auto-generate the risk tier for each use case, Auto-generate initial controls based on risk, Track and manage the vendor or internal solution details, Submit candidate AI solution through approval workflows to enforce reviews and policies.
ModelOp is commonly used for: Financial Services, Healthcare, Pharmaceuticals, Biotech, Consumer Packaged Goods Retail, Defense, Government, Public Sector, Chief AI Officer (CAIO), CDAO, CIO, AI Governance Teams Committees.
ModelOp integrates with: AWS SageMaker, Azure Machine Learning, Google Cloud AI, IBM Watson, DataRobot, H2O.ai, Alteryx, Tableau.
Based on user reviews and social mentions, the most common pain points are: token usage, API costs.

Shopping now starts in ChatGPT.
Oct 23, 2025
Based on 57 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.




