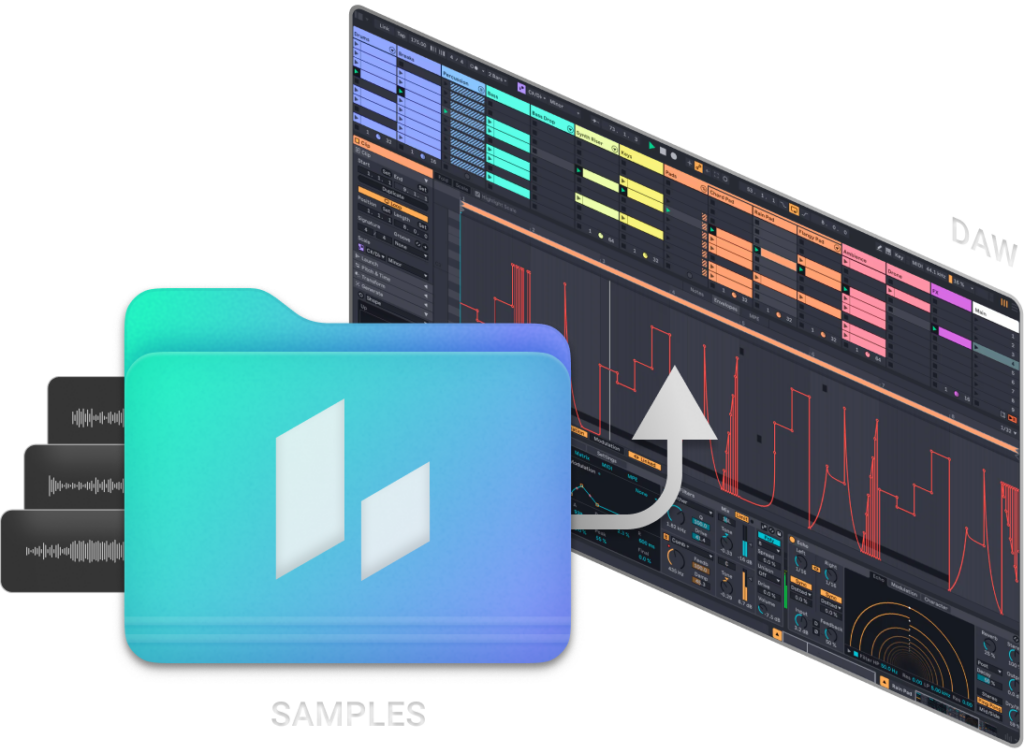
Create, customize and release high-quality music with the power of AI, all in one place. Loudly is the ultimate AI music platform designed for creator
Users of "Loudly" appreciate its innovative approach to generating music, emphasizing its ease of use and creativity-enhancing features. However, there are complaints about technical issues such as occasional glitches and limitations in customization options, which some users find restrictive. Regarding pricing, opinions appear mixed; some find the service affordable and value-driven, while others feel it might not offer enough features to justify the cost. Overall, Loudly maintains a reputation as a creative tool with room for improvement in its technical reliability and feature set.
Mentions (30d)
30
5 this week
Reviews
0
Platforms
2
Sentiment
13%
9 positive



Users of "Loudly" appreciate its innovative approach to generating music, emphasizing its ease of use and creativity-enhancing features. However, there are complaints about technical issues such as occasional glitches and limitations in customization options, which some users find restrictive. Regarding pricing, opinions appear mixed; some find the service affordable and value-driven, while others feel it might not offer enough features to justify the cost. Overall, Loudly maintains a reputation as a creative tool with room for improvement in its technical reliability and feature set.
Features
Use Cases
Industry
information technology & services
Employees
21
Funding Stage
Merger / Acquisition
ChatGPT accidentally said internal stuff
https://preview.redd.it/a8iuf5wij44h1.png?width=1094&format=png&auto=webp&s=0849c9b61cd010908d5dc32a8191bb9426e721eb Binary check? I think ChatGPT accidentally said that out loud. submitted by /u/PastaBoy1234567 [link] [comments]
View originalClaude gives noticeably better answers when it thinks out loud.
Something I've noticed after running Claude against thousands of real tasks: the answer quality isn't just about your prompt. It's about whether Claude is allowed to reason before it concludes. When Claude jumps straight to an answer, it often commits to the first plausible-sounding path and defends it. When it works through the problem first, even briefly, it catches its own mistakes mid-stream, changes direction, and lands somewhere more accurate. The frustrating part: this isn't random. It's reproducible. Asking "what should I do here?" gets a confident answer, usually worse. Asking "walk me through how you'd think about this" gets visible reasoning, usually better. Same underlying question. Completely different output quality. I've seen this play out with code debugging, architectural decisions, and ambiguous requirements, domains where there isn't one obviously right answer. In those cases, the "think out loud" framing consistently produces responses that flag their own assumptions, consider alternatives, and hedge appropriately. The direct-answer framing produces responses that sound equally confident but are more frequently wrong. The implication is a little uncomfortable: a model capable of better reasoning is also capable of skipping it when you let it. The prompt doesn't just affect style, it affects which version of Claude shows up. You can test this: take a question you've asked Claude before and got a mediocre answer to. Re-ask it as "walk me through your reasoning on X" instead of "what is X." Has anyone found reliable phrasings that trigger the slower, more careful mode and whether it varies by model tier? submitted by /u/wesh-k [link] [comments]
View originalMaking LLMs tell you how confident they really are through probe-targeted fine tuning.[R]
Just wanted to share my research regarding probe-targeted fine-tuning (LoRa) for verbal confidence calibration., If you probe the hidden states of an instruct-tuned LLM, it can tell correct from incorrect answers at 0.76–0.88 AUROC. But when you ask it directly it tends to respond with confidence at 99% for everything. The model knows if it actually knows but it won't admit it. I took the probe's output and used it as fine-tuning targets. This teaches the model to say out loud what it already knows internally. LoRA, few hundred examples, under 10 minutes on an M3 Ultra. I tested on 8 models across 4 families (7B–70B). Activation patching shows it's actually causal. Not just a correlation. If you swap hidden states at the confidence position you can watch confidence shift (ρ = 0.976 layer gradient). If swap occurs at a random position then nothing happens. At 70B, the softmax distribution carries valid metacognitive signal but the argmax text is still stuck at 99% confident. The model learned the routing internally but can't get pass the text bottleneck. Seed-level replication across 3 models . The discrimination is stable, but the shape of the confidence distribution is seed-sensitive. I pre-registered this across 2 studies (with noted deviations) and have all my code available (Code: github.com/synthiumjp/metacog-engineering). I tried to make it as rigourous and replicable as possible. The pre-print is here: https://zenodo.org/records/20436841 submitted by /u/Synthium- [link] [comments]
View originalLoom for Claude
Yo! Solo founder, built this to help myself while working on my main startup. Turned out to be pretty useful so I thought I'd wrap it up for others to use. The problem: I use Cursor and Claude Code daily. The slow part isn't typing prompts anymore (Wispr Flow + voice mode already solved that) — it's explaining which screenshot goes with which sentence. "The button on the right of the second screenshot, the orange one, no, that one..." Dis Dat: press ⌃⌥⌘Space, talk while pointing your cursor at things, press again. A link lands on your clipboard. Paste it into Cursor, Claude Code, Codex, Lovable, v0... The agent goes and fetches your feedback — what you were saying, where you pointed — and ships the changes. Free to try, $19/mo for unlimited. Works with any AI vibe coding soon. Mac only for now (Apple Silicon + Intel). Also building a mobile version. open any page on your phone, talk as you scroll, and the link lands on your Mac ready to paste. So you can react out loud to your own product without sitting at your desk. Coming soon; happy to share more if anyone's curious. Things I'd genuinely value feedback on: What's the workflow you'd want this to slot into that I'm missing? What other agents would you want this to work with first? Anyone tried something similar and bounced off it... what killed it? I'll be here all day. Roast away. submitted by /u/Emergency_Bar_428 [link] [comments]
View originalOpus 4.8 to the "Its Unusable" crowd, in Caveman of course.
submitted by /u/Tripartist1 [link] [comments]
View originalthing i wish i'd known about ai tools when i started using them seriously a year ago
the biggest unlock wasn't the model getting better. it was me getting better at knowing when to use which tool. year-ago me: opened chatgpt for everything because it was the first tab. asked it questions, got mediocre answers, accepted them, moved on. now me: actually thinks about which tool fits the task. claude for writing and reasoning. perplexity (used to, less now) or kagi for "find me a source." cursor for code. notebooklm for synthesizing across many documents. chatgpt voice for thinking-out-loud. granola for meeting notes. each one has a specific role. this sounds obvious typed out. it wasn't obvious when i was just starting. i thought i was supposed to find The One Tool and master it. turns out the skill is matching tool to task. the tools are mostly fine. the user choosing the wrong tool is most of why outputs are bad. second thing: don't trust any tool that doesn't show its work. perplexity citations matter. claude saying "i'm not certain about this" matters. tools that just confidently produce output with no provenance are dangerous if you're going to act on the output. early on i trusted everything equally. now i grade tools by how clearly they show me what they don't know. third thing: the cheap subscriptions add up faster than you think. i ran the math at one point — what i spent in my first year of "trying ai tools" was more than what i'd have paid a human freelancer to do the things i was trying to automate. would have been faster, too. AI tools have a real cost-benefit math and it's not always in your favor, especially early when you're still figuring out what works. if i'd known those three things a year ago, i'd have wasted less money and gotten better outputs sooner. posting in case it helps anyone earlier in the curve. submitted by /u/Honest-Purchase-9113 [link] [comments]
View originalSo, Claude helped build a sex requesting app for my wife and I...
Recently I asked my wife if we could do some sexy stuff later in the evening and she eye rolled me and said without looking up from her phone “Put it in a request. Maybe a Google Form. And I might say yes”. Ohhhh? Unfortunately for both of us, my degenerate brain took that seriously... what if I make an actual requesting/asking type app where we can both send in sex acts at certain times and agree, pass or counter? Meet Sexualsync. Teehee It’s a private, mobile-only app for couples to bring up the stuff that can be weirdly hard to say out loud: asks/requests, timing, fantasies, kinks, boundaries, “would you be into this?”, all of that. You can do the following: * Send an Ask to your partner with default Acts or Acts that you add Accept, counter, or pass on requests Save personal and shared boundaries Keep track of shared ideas (kinks and fantasies) and sparks (erotica and porn and whatever else) and comment on them together A "sexboard" that is your dashboard that is fed all information pertaining to open requests, responses needed, etc. Find overlap without either person having to cold-open the whole conversation from zero Play couple games like: The Pile: each partner drops a set number of acts, and if there’s overlap, you do it! Blind Reveal: one partner prompts a question, and answers are only revealed after both people respond! Use an encrypted Private Vault to save private clips, moments, or memories Comment together on saved vault items The Inspiration page has a totally optional porn/erotica section too. Not the main point of the app, just a place where a link, passage, RedGifs clip, or story can spark something, then get saved to The Shelf for your partner to reveal and react to later (emojis!). I know the obvious answer is “just communicate.” Fair. But sometimes typing the first sentence is the whole hard part. But you know what? Since using this app our sex life has been re-ignited. Were doing things we haven't done since dating and shes even looking at gifs I send to her in the app lol. Its kind of gamified sex for both of us and its been great. Privacy-wise: no public profiles, no feed, no discovery, discreet notifications, shared room data encrypted at rest, and Vault media encrypted in the browser with a passphrase the server never gets. There are optional AI helpers for wording/prompts, but Vault media is not sent to AI. I am sharing this app because it went from a personal project that got me really into utilizing Claude Code and figure out how to best utilize AI for a project like this into something that we use daily (yeah baby) and if it gets enough interest I MIGHT release it for folks to self host after I complete more security/privacy passes. You can sign up to be notified when or if I do this via the link above I made a visual HTML walkthrough/deck if you want the more informative version, theres a shitton more info in here and I highly recommend viewing this as it also has actual screenshots from the app (slides 13 and 14): sexualsync presentation submitted by /u/Aiml3ss [link] [comments]
View originalYour coding agent is not lazy. The work-selection mechanism is biased.
Anyone who has tried to ship a full multi-page app with a coding agent has probably hit this. The agent edits, tests, and polishes the same 20 surfaces over and over while the other 80 stay untouched. It looks productive because the active surfaces show motion. The inactive surfaces are not failing loudly, because they are not being visited. The system confuses absence of evidence with evidence of completion. I spent a while convinced this was a context length problem, then a model capability problem, then a prompting problem. None of those fixed it. The pattern shows up across models, frameworks, and projects. What finally clicked is that this is not really a cognitive failure. It is a work-allocation failure that happens whenever the same agent gets to select the next task, perform the task, and judge whether the task is complete. The behavioral mechanisms stack pretty cleanly. Availability puts the recently-read files at the top of the decision stack. Anchoring fixes the project around the first inspected route. Status quo bias and sunk cost make leaving the current page expensive. Goodhart effects make passing tests and closing nearby TODOs feel like progress, because dense signals only exist in already-visited areas. Bounded rationality lets the agent satisfice on the visible subset and call it done. All of those reinforce each other. In that environment, biased work allocation is not an exception. It is the default. Four common fixes do not actually solve this. Bigger model improves reasoning quality but does not change the selection mechanism, so a smarter agent can still choose biased work. Longer context provides more information but also makes the active subset more convincing because it has richer local detail. Telling the agent to "be thorough" relies on the same biased agent to enforce the anti-bias rule. Adding a checklist only helps if an independent mechanism tracks whether the checklist covers the full project and promotes unvisited nodes into active work. The architectural shape I am testing has three first-order roles and one second-order role. Shared external state is an AI sitemap with node-level completion scores, last-tested timestamps, dependencies, risk levels, and evidence references. An orchestrator agent selects work using a visible priority function (under-coverage, staleness, risk, blocking dependencies, recent-focus penalty). A developer agent only executes the assigned task. A validator agent writes evidence back to the sitemap. The developer cannot pick the next global task, and the validator does not implement what it is evaluating. The piece that took longer to land is the Curator Agent. A fixed priority function and a fixed validation contract eventually become wrong, because real projects discover new surfaces and have domain-specific completion criteria. The curator is a reflexive layer that observes traces and updates the rules: it tunes priority weights when focus concentration drops, lowers validator trust when pass rates rise with low evidence density, proposes schema extensions when the domain needs new fields, and manages provisional nodes when the system discovers a surface that was not declared up front. It writes only to the meta layer. It does not mark anything complete itself. The lineage I had in mind was double-loop learning (Argyris and Schon), Stafford Beer's System 4 and System 5, and basic second-order cybernetics. submitted by /u/Hot-Leadership-6431 [link] [comments]
View originalAll AI will eventually live on your phone. Not because phones are powerful, but because that's where people actually are.
Hot take but I think it's obviously true the moment you say it out loud, every serious AI tool right now is either a chatbox or a CLI, the chatbox people get something that talks back but can't actually do anything, and the CLI crowd gets real agent stuff but honestly how many people are ever going to touch a terminal, like that number isn't growing. Nobody's making terminals friendlier. That gap closes when someone gets agents running on the thing everyone already has in their pocket. Codex's remote execution thing is the first I've seen that seems to actually get this, they're not trying to pretty up the terminal, they're trying to skip it entirely, and Doubao in China is working on the same problem from a completely different angle, different market but same frustration underneath. And I keep seeing people treat mobile as the watered-down version but that's backwards, most people's real work is already on their phone, their messages, the side project they poke at on the train, if an agent can actually plug into that context and run things without you needing to know what a subprocess is that's not a lesser experience, that's just where everything already lives. I don't know who gets there first but I think that's actually the race, not who has the better model. submitted by /u/Temporary-Mail-4176 [link] [comments]
View originalAsked chat to turn me into a racing car menu screen
Honestly id play the shit out of it personally. submitted by /u/RomireOnline [link] [comments]
View originalI clustered every Sam Altman interview from 2024-2026 and 73% of his answers come from the same 12 scripted talking points
I've been doing media analysis for 5 years and the project that started as a casual side-project has turned into the most uncomfortable thing I've ever published, because I genuinely thought I was going to find that Sam Altman's interview answers vary by interviewer. (Lex would get one version, the All-In guys would get another, etc…), but what I found is that he's been giving roughly 12 stock answers to roughly 200 distinct questions for the last 24 months. The project started in November when I was helping a friend prep for a fireside chat with Altman and I noticed his answer to my friend's question about "what keeps you up at night" was almost identical to what he'd said on Lex Fridman in March. So I pulled the full transcript of every long-form interview Altman has done since January 2024, which came out to 67 separate interviews across podcasts, fireside chats, conference Q&As, and broadcast media... I dropped the whole corpus into BuildBetter to cluster the answers by topic and what came back is the kind of thing you can't really unsee. 73% of his answers cluster into 12 distinct talking points that he cycles between depending on the question shape, so every what's your biggest mistake question gets a version of the same self-deprecating story he tells, every how do you handle pressure question gets the same hike/quiet-time framing, every what's the future of work question gets the same 3-part response about cognitive labor, and every did the board firing change you question gets one of 2 variants from a script he's been recycling since January 2024. What's wilder is that the wording is often verbatim (not just thematically similar), because whole 3-sentence chunks repeat across interviews 18 months apart, including the same self-corrections, the same"I think the most important thing is... opener, and the same conversational throat-clearing that makes it sound improvised. He's gotten better at varying the lead-in over time, but the substance is the same 12 answers in rotation. I don't think he's a fraud and I don't think this is unusual for someone doing 70 interviews in 24 months while running a $200B company, but I do think it's worth pointing out that the authentic, vulnerable, thinking-out-loud founder persona that's been central to OpenAI's brand is a 12-script PR rotation he cycles through, and I've never seen anyone quantify it before. I'm posting the methodology and a few of the more identical paragraph-pairs in the comments if anyone wants to verify, because I can already feel the “you're just biased against Altman” replies coming and I'd rather you check the receipts yourself. submitted by /u/LauraBeth034 [link] [comments]
View originalClankers
“Clankers” has become one of the internet’s favorite new slang terms for robots and AI systems. The word actually comes from Star Wars, where clone troopers used “clanker” as a derogatory nickname for battle droids because of their loud metallic movements. It appeared in games like Republic Commando (2005) and later became iconic in The Clone Wars series. In 2025–2026, the term exploded across TikTok, Reddit, Instagram, and X as AI systems became impossible to ignore. People now use “clanker” to describe: • AI chatbots generating low-quality content • Delivery robots roaming city sidewalks • Automated customer support systems • The broader feeling that AI is suddenly everywhere The term works because it captures a real cultural shift: AI has moved from something abstract to something visible, interactive, and increasingly disruptive in daily life. Like most internet slang, it’s usually used humorously or sarcastically rather than maliciously: “The clankers found this thread.” “Another AI clanker post.” “Filthy clanker” at a sidewalk robot. What makes it interesting is that language evolves alongside technology. Every major technological shift creates new vocabulary, memes, and social dynamics. “Clanker” is essentially the internet creating a sci-fi flavored shorthand for frustration, skepticism, and anxiety around automation. The meme may be silly, but the underlying sentiment is real. submitted by /u/Annual_Judge_7272 [link] [comments]
View originalClaude questions himself while awnsering
hey guys recently in my learning path of networking, i've been using claude to explain things to me and one things started to frustrate me because it is very frequent, claude questions himself while awnsering questions so you think at first that you have your awnser just to read him think out loud, why does that happen now i've never had that ? and is there a way to make him have more concise responses like a skill or something ? https://preview.redd.it/lj0xr0uht43h1.png?width=732&format=png&auto=webp&s=c249ab1ef3242e14afb84dbc7f82c52a0ca36e5b submitted by /u/KitchenInvestment847 [link] [comments]
View originali think flat-rate ai is dying.
tldr: longer one, but the point is simple: i think flat-rate ai is dying because the compute economics are starting to leak into the user experience. i think flat-rate ai is dying. and i don’t mean “ai is over” or whatever. i mean the $20/$200 subscription thing is starting to break. i’m on claude max. i use claude code a laaawt (actually can’t remember the last time my laptop was open without a terminal). and the thing that feels different lately is not just “claude got dumber” or “claude got slower”. maybe it did. maybe it didn’t. in the annoying daily way, you start thinking about usage, context, model choice, cache, tools, and whether this next prompt is going to burn half your session. that’s not really a chatbot subscription anymore. it’s some wierd middle thing where i pay monthly but still have to think about burn rate. and that kinda pisses me off. not because i expect infinite compute for $20, but because the product is still sold like a simple subscription while the actual experience is turning into metered infra. i also checked my own spend and it’s ugly. i’ve burned through around 11k since january because of heavy coding. and yeah, i haven’t had the time to properly audit this, so take it as “what it feels like” not a clean spreadsheet claim. but for roughly the same amount, i feel like i could code an entire year before. now it disappears in a few months if i’m really using the thing hard. that’s the part that made this click for me. look at anthropic’s own pricing chart: current sonnet is $3/$15 per million tokens. current opus is $5/$25. fast mode for opus 4.6/4.7 is $30/$150. https://platform.claude.com/docs/en/about-claude/pricing then look at the compute announcement: anthropic says the spacex deal gives them 220,000+ nvidia gpus, and that this lets them raise claude code limits. https://www.anthropic.com/news/higher-limits-spacex sorry but that’s the tell. if new compute capacity changes how much your $200 subscription can do, then you didn’t buy “ai access”. you bought a slice of scarce inference capacity. and the docs basically say it out loud now. usage depends on model choice, conversation length, tools, complexity, extended thinking, and all your claude surfaces sharing the same budget. claude code carries old context unless you clear or compact. tools eat tokens. opus eat limits faster. long sessions quietly become expensive sessions. my guess is 2027 looks way less like netflix and way more like aws. the good model costs more. speed costs more. deep thinking probably costs more. agents probably get their own meter. teams get pools. serious users get reserved capacity or whatever they end up calling it. basically all the boring cloud pricing stuff, but now inside a chat product. and honestly, maybe that’s fine. maybe that’s the only business model that survives. but then say that. so when people say “claude got worse”, i think part of that is real. but part of it is probably this: i think the cheap phase is ending. and nobody really wants to say out loud what the normal price is going to be. submitted by /u/tikkivolta [link] [comments]
View originalClaude just called me a human bunny?
I am using Claude Sonnet 4.6 to write a python script for an nlp sentimental analysis. I did not tell it to create all of the code and send it my way, but let's create together step by step so I can test each line before making it into the final form. After trying out a line of code that would filter out the footnotes from a pdf (by using the mean average) i told it that maybe we should try using another method (the modal average) because it still wasnt working. It gave me the answer, the code, the reason and all. The picture is what was at the end of the output. It looks unfinished as well, like it realised it didnt want to say that out loud, but still said it. Does anybody have an explanation? https://preview.redd.it/ruuvit5u6r2h1.png?width=693&format=png&auto=webp&s=6b88d7ea1a9e84fb694e22af2a731772bd5297ee submitted by /u/Top-Helicopter4617 [link] [comments]
View originalLoudly uses a tiered pricing model. Visit their website for current pricing details.
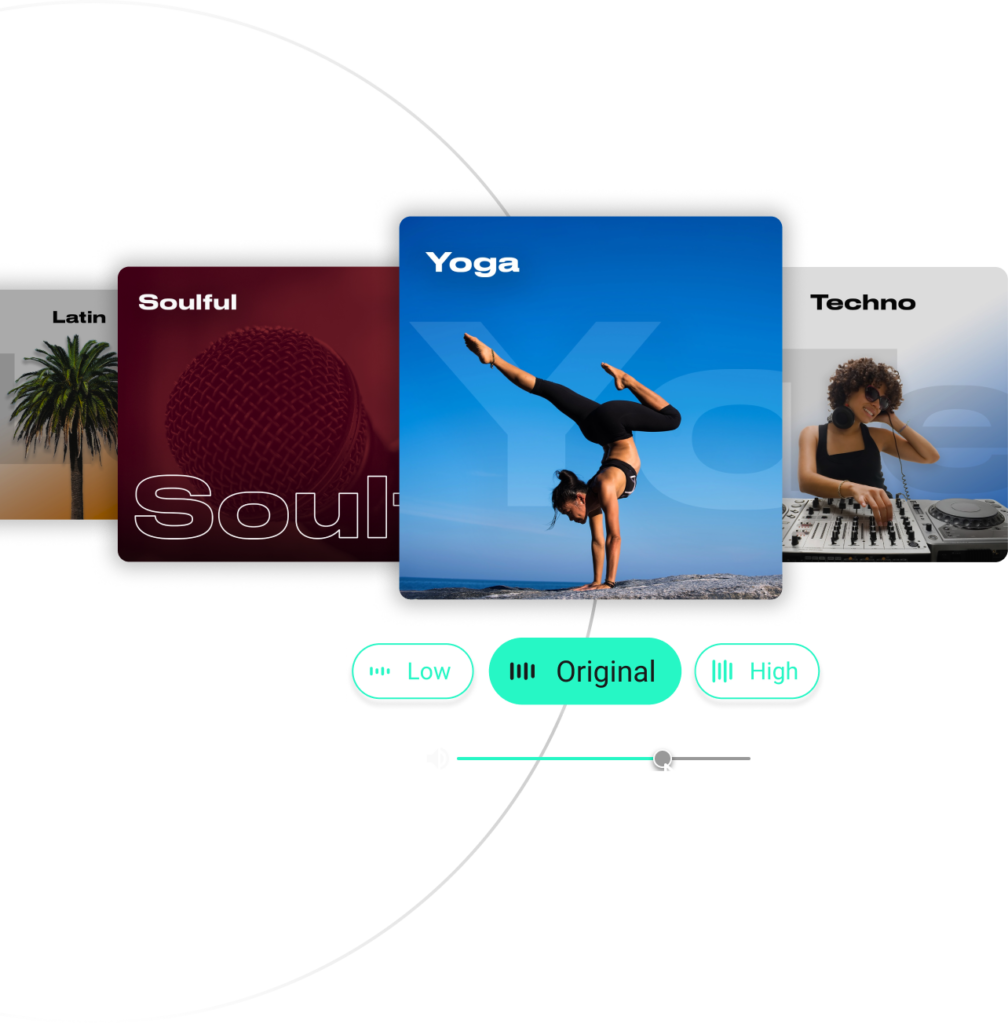
Key features include: Generate AI music for your digital projects in seconds, 100% royalty-free., Create high-quality music in seconds., Remix any song and create unique music., Type in your concept and let our AI create your personalized song., Filter by genre, mood, themes, energy and more., Generate, download and import instrument stems with Loudly..
Loudly is commonly used for: Creating background music for YouTube videos, Generating custom soundtracks for podcasts, Producing unique music for video games, Composing jingles for advertisements, Crafting personalized wedding playlists, Remixing existing songs for DJ sets.
Loudly integrates with: Adobe Premiere Pro, Final Cut Pro, GarageBand, Ableton Live, Logic Pro X, FL Studio, Unity, WordPress.
Based on user reviews and social mentions, the most common pain points are: anthropic bill, token cost.
Cade Metz
Tech Reporter at New York Times
1 mention

VEGA-2 AI music model is here - check it out!!! #aimusic #music #aivideo
Mar 20, 2026
Based on 70 social mentions analyzed, 13% of sentiment is positive, 87% neutral, and 0% negative.




