Turn your data from a rear-view mirror into a forward-facing guidance system. Fullstory captures complete user behavioral context so your AI stack can
User feedback on "FullStory AI" cites its main strengths as user-friendly interfaces and robust data analysis capabilities. However, there is a lack of specific complaints or detailed user reviews in the available data. Pricing sentiment appears to be neutral with limited insights provided. Overall, while the tool is part of discussions in various contexts, the absence of focused reviews makes it challenging to fully gauge its reputation.
Mentions (30d)
30
3 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive






User feedback on "FullStory AI" cites its main strengths as user-friendly interfaces and robust data analysis capabilities. However, there is a lack of specific complaints or detailed user reviews in the available data. Pricing sentiment appears to be neutral with limited insights provided. Overall, while the tool is part of discussions in various contexts, the absence of focused reviews makes it challenging to fully gauge its reputation.
Features
Use Cases
Industry
information technology & services
Employees
560
Funding Stage
Venture (Round not Specified)
Total Funding
$195.2M
Opus 4.7 Low Vs Medium Vs High Vs Xhigh Vs Max: the Reasoning Curve on 29 Real Tasks from an Open Source Repo
# TL;DR I ran Opus 4.7 in Claude Code at all reasoning effort settings (low, medium, high, xhigh, and max) on the same 29 tasks from an open source repo (GraphQL-go-tools, in Go). **On this slice, Opus 4.7 did not behave like a model where more reasoning effort had a linear correlation with more intelligence. In fact, the curve appears to peak at medium.** If you think this is weird, I agree! This was the follow-up to a Zod run where Opus also looked non-monotonic. I reran the question on GraphQL-go-tools because I wanted a more discriminating repo slice and didn’t trust the fact that more reasoning != better outcomes. Running on the GraphQL repo helped clarified the result: Opus still did not show a simple higher-reasoning-is-better curve. The contrast is GPT-5.5 in Codex, which overall *did* show the intuitive curve: more reasoning bought more semantic/review quality. That post is here: [https://www.stet.sh/blog/gpt-55-codex-graphql-reasoning-curve](https://www.stet.sh/blog/gpt-55-codex-graphql-reasoning-curve) Medium has the best test pass rate, highest equivalence with the original human-authored changes, the best code-review pass rate, and the best aggregate craft/discipline rate. Low is cheaper and faster, but it drops too much correctness. High, xhigh, and max spend more time and money without beating medium on the metrics that matter. More reasoning effort doesn't only cost more - it changes the way Claude works, but without reliably improving judgment. Xhigh inflates the test/fixture surface most. Max is busier overall and has the largest implementation-line footprint. But even though both are supposedly thinking more, neither produces "better" patches than medium. One likely reason: Opus 4.7 uses adaptive thinking - the model already picks its own reasoning budget per task, so the effort knob biases an already-adaptive policy rather than buying more intelligence. More on this below. An illuminating example is PR #1260. After retry, medium recovered into a real patch. High and xhigh used their extra reasoning budget to dig up commit hashes from prior PRs and confidently declare "no work needed" - voluntarily ending the turn with no patch. Medium and max read the literal control flow and made the fix. One broader takeaway for me: this should not have to be a one-off manual benchmark. If reasoning level changes the kind of patch an agent writes, the natural next step is to let the agent test and improve its own setup on real repo work. *For this post, "equivalent" means the patch matched the intent of the merged human PR; "code-review pass" means an AI reviewer judged it acceptable; craft/discipline is a 0-4 maintainability/style rubric; footprint risk is how much extra code the agent touched relative to the human patch.* I also made an interactive version with pretty charts and per-task drilldowns here: [https://stet.sh/blog/opus-47-graphql-reasoning-curve](https://stet.sh/blog/opus-47-graphql-reasoning-curve) The data: |Metric|Low|Medium|High|Xhigh|Max| |:-|:-|:-|:-|:-|:-| |All-task pass|23/29|28/29|26/29|25/29|27/29| |Equivalent|10/29|14/29|12/29|11/29|13/29| |Code-review pass|5/29|10/29|7/29|4/29|8/29| |Code-review rubric mean|2.426|2.716|2.509|2.482|2.431| |Footprint risk mean|0.155|0.189|0.206|0.238|0.227| |All custom graders|2.598|2.759|2.670|2.669|2.690| |Mean cost/task|$2.50|$3.15|$5.01|$6.51|$8.84| |Mean duration/task|383.8s|450.7s|716.4s|803.8s|996.9s| |Equivalent passes per dollar|0.138|0.153|0.083|0.058|0.051| # Why I Ran This After my last post comparing GPT-5.5 vs 5.4 vs Opus 4.7, I was curious how intra-model performance varied with reasoning effort. Doing research online, it's very very hard to gauge what *actual experience* is like when varying the reasoning levels, and how that applies to the work that I'm doing. I first ran this on Zod, and the result looked strange: tests were flat across low, medium, high, and xhigh, while the above-test quality signals moved around in mixed ways. Low, medium, high, and xhigh all landed at 12/28 test passes. But equivalence moved from 10/28 on low to 16/28 on medium, 13/28 on high, and 19/28 on xhigh; code-review pass moved from 4/27 to 10/27, 10/27, and 11/27. That was interesting, but not clean enough to make a default-setting claim. It could have been a Zod-specific artifact, or a sign that Opus 4.7 does not have a simple "turn reasoning up" curve. So I reran the question on GraphQL-go-tools. To separate vibes from reality, and figure out where the cost/performance sweet spot is for Opus 4.7, I wanted the same reasoning-effort question on a more discriminating repo slice. This is not meant to be a universal benchmark result - I don't have the funds or time to generate statistically significant data. The purpose is closer to "how should I choose the reasoning setting for real repo work?", with `GraphQL-Go-Tools` as the example repo. Public benchmarks flatten the reviewer question that most SWEs actually care about: would I a
View originalI had my agent use autoresearch over 8 iterations to improve my CLAUDE.md, measuring each version against tasks from real PRs. The best one still regressed on a holdout.
I have a confession: I vibe-coded my CLAUDE.md, and I'm pretty sure it's slop. I needed to make it better. Naturally, I asked Codex to do it. (I know this is a Claude sub, Claude could have done it as well!) The difference: this time, Codex used a benchmark on my repo to measure each change, and optimized CLAUDE.md against the data, instead of on pure vibes. Why We Should Take CLAUDE.md Seriously Saying "AGENTS.md is important" is, at this point, a cliche. At risk of beating a dead horse, I'll say it again. Someone adds a rule that sounds smart, senior, and reasonable, commits it, and hopes the agent behaves better. But AGENTS.md, CLAUDE.md, and shared skills are not normal docs. They are part of the runtime behavior of your coding system. The shift is to start treating CLAUDE.md like a tunable part of the harness: holding everything else the same, how does agent behavior differ when I change AGENTS.md? That's what I measured. The Results After eight candidate runs, one version looked useful on a five-task training slice. It fixed the task the baseline missed, improved footprint risk, and moved several craft scores up. Then I ran it on a clean ten-task holdout. The candidate regressed. Not catastrophically, but enough that blindly shipping would have been wrong. Footprint widened, tokens climbed, tool calls climbed, and code-review correctness fell, all while tests held even. Caveat: one repo (mine), n=10 on the holdout. This is directional, not statistically significant. For this post, "equivalent" means the patch matched the intent of the merged human PR; "code-review pass" means an AI reviewer judged it acceptable; craft/discipline is a 0-4 maintainability/style rubric; footprint risk is how much extra code the agent touched relative to the human patch. The pattern is the agent doing more work for mixed outcomes - better on local craft (clearer names, coherent implementations), worse on boundary judgment (scope, minimality, robustness). Tokens and tool calls confirm it: the candidate was spending more to get there, not less. "Better instructions make the agent cheaper" did not hold on the holdout. best iteration and holdout vs baseline Methodology The setup was Codex with gpt-5.5, medium reasoning, on real historical Stet tasks (dogfooding). Stet scored tests, strict publishability, equivalence, code review, footprint, total input/output tokens, duration, and craft/discipline rubrics like simplicity, coherence, robustness, instruction adherence, scope discipline, and diff minimality. The grader was gpt-5.4. 8 iterations on an n=5 sample set, and a n=10 task holdout. I know sample size is small - the goal of this was to get directional analysis, and prove the methodology Codex was set with a simple /goal: iterate AGENTS.md to improve performance on the benchmark. Process The first round of iteration showed something I wish more people internalized: plausible instructions are not necessarily good interventions. Codex first tried a broad router rule: identify the work type, state a hypothesis before editing, read the right docs, and treat scope as part of correctness. It sounded good but exposed a failure mode: the agent could interpret "small scope" as permission to miss named obligations. The next candidate added an "obligation ledger". Before editing, the agent had to identify the named behavior, compatibility constraints, docs, tests, and non-goals. Before reporting back, it had to mark each as met, missed, or not checked. Here is the actual diff shape. First, the best candidate from the first loop replaced one generic "read the docs" rule with routing, hypothesis, obligation, scope, and evidence rules: - For nontrivial work, read the matching `agent_docs/` file first for current operational commands and conventions. + Route before acting: identify whether the work is implementation, eval/report interpretation, dataset/pipeline, Linear/Symphony, release, frontend, or GTM; then read the matching `agent_docs/` or skill file before changing behavior. + For nontrivial changes, state the smallest testable hypothesis before editing. After validation, report whether the evidence confirmed, refuted, or only weakly supported it. ... Full details in blog post https://www.stet.sh/blog/how-i-used-codex-to-improve-its-own-agents-md That obligation-ledger candidate was the first useful signal. Code review improved by +0.75, correctness by +0.60, maintainability by +1.00, simplicity by +0.64, coherence by +0.60, and scope discipline by +0.36. Tests stayed flat at 5/5. But footprint risk got slightly worse, and the evidence was still a small same-sample read. If I were editing by vibes, I might have shipped it. The eval said: useful direction, not a clean win, keep iterating. Codex then tested the kind of rule that intuitively makes sense: prefer existing helpers, schemas, reporting paths, and public contracts before adding new machinery. It sounded correct - and the eval hated it. Tests st
View originalRunning multiple Claude Code sessions in parallel with git worktrees - my approach
Quick story: I kept losing context every time I had to `git stash` and switch branches to test something an agent had suggested. Then I actually read up on `git worktree` and it solved the whole problem. What my setup looks like now: - Main worktree: where I review and commit - 2-3 extra worktrees, each with its own Claude Code session running on its own branch - When one agent finishes a task, I `cd` in, review the diff, merge, move on - No stashing, no context switching, no "wait what was I doing" Full writeup in the article on Medium (https://medium.com/@buildwithpulkit/git-worktree-the-underrated-git-feature-every-ai-era-developer-should-know-32750886654a). Curious whether anyone else is doing parallel agent setups, I would love to hear other patterns. submitted by /u/buildwithpulkit [link] [comments]
View originalI clustered every Sam Altman interview from 2024-2026 and 73% of his answers come from the same 12 scripted talking points
I've been doing media analysis for 5 years and the project that started as a casual side-project has turned into the most uncomfortable thing I've ever published, because I genuinely thought I was going to find that Sam Altman's interview answers vary by interviewer. (Lex would get one version, the All-In guys would get another, etc…), but what I found is that he's been giving roughly 12 stock answers to roughly 200 distinct questions for the last 24 months. The project started in November when I was helping a friend prep for a fireside chat with Altman and I noticed his answer to my friend's question about "what keeps you up at night" was almost identical to what he'd said on Lex Fridman in March. So I pulled the full transcript of every long-form interview Altman has done since January 2024, which came out to 67 separate interviews across podcasts, fireside chats, conference Q&As, and broadcast media... I dropped the whole corpus into BuildBetter to cluster the answers by topic and what came back is the kind of thing you can't really unsee. 73% of his answers cluster into 12 distinct talking points that he cycles between depending on the question shape, so every what's your biggest mistake question gets a version of the same self-deprecating story he tells, every how do you handle pressure question gets the same hike/quiet-time framing, every what's the future of work question gets the same 3-part response about cognitive labor, and every did the board firing change you question gets one of 2 variants from a script he's been recycling since January 2024. What's wilder is that the wording is often verbatim (not just thematically similar), because whole 3-sentence chunks repeat across interviews 18 months apart, including the same self-corrections, the same"I think the most important thing is... opener, and the same conversational throat-clearing that makes it sound improvised. He's gotten better at varying the lead-in over time, but the substance is the same 12 answers in rotation. I don't think he's a fraud and I don't think this is unusual for someone doing 70 interviews in 24 months while running a $200B company, but I do think it's worth pointing out that the authentic, vulnerable, thinking-out-loud founder persona that's been central to OpenAI's brand is a 12-script PR rotation he cycles through, and I've never seen anyone quantify it before. I'm posting the methodology and a few of the more identical paragraph-pairs in the comments if anyone wants to verify, because I can already feel the “you're just biased against Altman” replies coming and I'd rather you check the receipts yourself. submitted by /u/LauraBeth034 [link] [comments]
View originalI’m not a developer. I’ve been using codebase memory MCP tools and Obsidian to give Claude persistent memory for my fantasy and sci fi worlds. Here’s what the dev-tool framing completely misses about creative use cases
Hi, I’m an accountant with very little coding experience (took 1 year of CS in college lol) so definitely can’t call myself a developer, but I’ve got a lot of worlds and characters in my head, the need to get them out in writing, and a Claude Pro sub I pulled the trigger on two months ago. I was hoping to see what I could do with things like Claude Code for more non-coding use-cases. So far it’s surpassed everything I’ve experienced except for one, major hang up: LLM memory for long-context creative writing work still sucks. Things like brainstorming for a fantasy universe or tracking the game state of a multi-session solo rpg campaign usually starts out pretty well for the first few chats, until you need to mount dozens of lore files and .md style guides to a project, have to wait for it to read all of that, then watch as your session usage bloats out for a simple reply and the quality degradation gets *really* noticeable. I’ve been lurking on AI writing subs and the sentiment seems to be shared across the board. So I looked in other places for possible solutions. Then I came across posts in this sub touting Claude memory MCP tools for codebases. Tools like Codesight and MemPalace caught my attention because I thought their applications could extend beyond coding and developer use-cases. The same semantic search and knowledge graph capabilities some of these tools offered for memorizing large, complicated codebases could be used to memorize large, complicated worldbuilding bibles as well, and most of the comments on these posts never mentioned that, or if they did, they were buried or ignored. I decided to test it out myself, starting with MemPalace, a suite of tools that work locally to index your Claude conversations and files into a semantic-searchable knowledge base it can query. My idea started out like this: since I’m already using Obsidian to organize my lore files (with an entry for each character, location, magic system, story arc, etc.) like a wiki or encyclopedia for my worlds, what if I had Claude save my Obsidian vault to its memory so it can recall those lore details whenever the context called for it in any given conversation? I was essentially making a “Second Brain” for Claude out of my Obsidian vault world bible, something I’ve read people doing already but never truly “got” it until I saw it in action. I had no idea about MCP tools before this but before long (and with Claude’s patient help) I was able to wire up the memory palace, mine my obsidian vault info into its memory (organized into verbatim chunks/snippets called “drawers”), and start chatting with it with its new “memories” at its disposal. I was surprised at how seamlessly it worked when I approached this tool sideways. I’d half expected it to work similar to how SillyTavern’s world info and lorebook injection worked, and in fact, I’d been thinking about using these tools to create a similar feature for my own Claude setup, but it was *not* like that at all. Lorebook injection worked by listening for a set of keywords that you set up in the World Info tab of SillyTavern, and when one of those keywords is detected in your prompt, it injects the entire lore file from World Info into the chat context. This can cause a lot of token bloat especially if your World Info entries are content-rich or you make a lot of lore references in your chat. What this did instead was make Claude ask plain-language questions to the MCP tools, things like, “What is Gene’s friendship with Felix like?” Or “what is Gene’s relationship to Clara-Belle?” When both of them are in a scene for example. It didn’t just look up Gene and Clara-Belle’s entire lore files and info-dumped everything into context, it pulled up the “Relationships” section of Gene’s file since that’s relevant to the context as well as Clara-Belle’s “Relationships” snippet from her file and any other relevant snippets, then pieced the full picture together through inference. The results: ~2% session usage on a cold start with Sonnet 4.6 with no project or additional context mounted. Claude references character motivations, relationship history, and world/location details I haven’t mentioned in weeks without me prompting it to. It picks up from where we last left off seamlessly across chat after chat. The reconstructive memory aspect I felt works like our own memory and produced perfect recall across sessions. Another side-effect I noticed is that when it references my lore files, it will pick up my style from the way the lore file is written. No more voice-flattening from encyclopedia-sounding lore entries. All the depth, nuance, and psychology I worked hard to cultivate are preserved and the Claude tools are smart enough to factor that in when it replies. I even make sure to add a “Voice” section to each character lore file in that character’s own voice so Claude can pick up on that when it reads that snippet in the tool call and applies it to its current context. Current dr
View originalAI Doesn't Exist, and Poop Proves It
robot Maybe we should have called it accumulated intelligence. There is no artificial intelligence. Or at least, I don't think the word "artificial" is as clean as we pretend it is. I know this blog smells funny. Let me decompose it. What do we even mean when we say something is artificial? Usually we mean man-made. Something humans made. Something that would not exist without humans, but after humans, it exists because humans made it happen. That definition is useful. I understand why we use it. Even the original 1955 Dartmouth proposal, the document that helped name the field of "artificial intelligence," used the phrase in a practical way: a machine could be made to simulate parts of learning or intelligence. As a scientific label, the word has a job. So I am not really arguing with the dictionary. I know artificial can simply mean human-made. That is not the part I have a problem with. I am arguing with the feeling the word creates. But there is another meaning hiding inside it. Artificial starts to feel like separate. Fake. Unnatural. Something that does not really belong to this world. And that is where I think the word starts confusing us. Because humans are not outside nature. The brain is natural. It is part of this earth. Biology produces a thought. That thought becomes an action. That action becomes a tool, a house, a wheel, a computer, or a model that can answer questions in language. So where exactly does the artificial part begin? Human-made does not automatically mean unnatural If I take a seed and plant it, and then a plant grows, is that plant artificial? It happened because of human action. I moved the seed. I changed the situation. Maybe without me, that plant would not have grown there. But we still do not call the plant artificial. We understand that the plant is natural, even if human action helped it happen. Now take a wheel. A human thought about how to make travel easier. How to cover distance more efficiently. That thought became a shape. That shape became an object. That object changed how humans moved through the world. We call the wheel artificial because it was made by humans. But the human who imagined it was not artificial. The brain that produced the thought was not artificial. The need to move, carry, build, survive, and improve was not artificial. So again: where did the artificial part enter? Maybe we say "artificial" because it separates what existed before humans from what humans transformed. That is fine for communication. A tree and a wooden table are not the same thing. Designed things, synthetic things, industrial things, and harmful things can still be meaningfully different from a tree in a forest. But also, humans never really make anything from nothing. We transform what is already here. We take energy, matter, language, memory, need, and imagination, and we rearrange them. It is never fully made from nowhere. It is transformed. So I am not trying to erase all distinctions by calling everything natural. Natural does not mean harmless. Natural does not mean good. Natural does not mean morally excused. I am only saying that human-made things are not outside nature just because humans made them. Poop and thoughts are the same, in one simple way I know this is a strange example. Sometimes I have this itch to say the first thought that comes into my head. Unfortunately, this was the first thought. But maybe that is why it works. It is funny because it is too human. Also, it makes the point clearly. Why isn't poop artificial? Poop is a product of a human being. It comes from the body. It is produced by biology. We do not call it artificial, even though it is made by a human in the most literal way. A thought is also a product of a human being. It comes from the brain. It is produced by biology too. Poop and thoughts are the same in one simple way: both are products of a human. We treat one as biology. We treat the other as invention. But why? Why does one product of the human body feel natural, while another product of the human body becomes artificial the moment it turns into a tool? A thought does not stop being natural just because it becomes useful. A thought does not become unnatural just because it becomes a wheel, a house, a car, a computer, or a machine that can respond to language. It is still a product of the same earth. The same biology. The same human need to survive, organize, create, and understand. We don't call a beehive artificial Think about ants building a colony. They create a structure that is safer and more efficient for them. They organize themselves. They transform the environment around them. They make something that was not there before. But we do not look at an ant colony and say, "This is artificial." Same with bees making a hive. A beehive is built. It has structure. It has purpose. It stores food. It protects the colony. It is a product of collective behavior. But we call it natural
View originalA CEO built his own AI agent with Claude MCP + NetSuite. It worked. Then it didn't scale.
How many of you have a prototype that demos great and then falls apart the moment real users touch it? Yeah. This is that story, except the person who built the prototype was the CEO himself. S&B Filters, a U.S. manufacturer with 700+ employees, runs its entire operation on NetSuite. Their CEO wired up Claude's MCP connector to NetSuite, wrote his own prompts, and got an internal AI assistant working for order status lookups. Legit impressive for a solo build. Then the fun part: 4–6 minute response times, a 40-page prompt holding the whole thing together, PO numbers coming in different formats from Shopify, phone, and email, and zero path to putting this in front of actual customers. He came to us basically saying, "I proved it works, now make it work for real." We didn't patch the prototype. Our team at BotsCrew rebuilt the whole stack around NetSuite as the source of truth. We built an input normalization layer that validates across formats, falls back across identifiers (Sales Order > PO > customer reference), and uses conversation context when the input is garbage. This was 80% of the engineering challenge. Then: two interfaces off one backend, an internal assistant for the support team, and customer-facing on the website. Same AI layer, different access controls. Beyond order lookups, installation guides, compatibility checks, and technical inquiries with images and videos. Dynamic knowledge base via OneDrive, updated by the client without redeployment. Results: ~50% of support requests are fully automated 24x faster first response ~$140K/year in savings ~250% ROI in Year 1 Now they're expanding into full order management, dealer identification, and personalized discounts through the same system. One prototype turned into a full AI program. If you want to read the full case study with screenshots and more technical details, I'll drop the link in the comments. submitted by /u/max_gladysh [link] [comments]
View originalStoryboard generated from GPT image 2.0
I gave GPT a set of prompts that I found a bit too complicated, and to my surprise, it generated content that matched perfectly. I'm very curious about how GPT Image 2.0 works behind the scenes, and how it can understand and produce high-quality images so quickly. I've included my creation process here; you can view the full image content and try using these prompts directly. https://app.tapnow.ai/tapflow/view/49aa2245 prompt:**PROJECT FILE: HIGH-ALTITUDE ASCENT // PREMIUM HARDSHELL CAMPAIGN** **FORMAT: ARRIRAW 4.5K / KODAK VISION3 50D 5203 EMULATION** **DIRECTOR'S PRE-PRODUCTION VISUAL BOARD** --- ### Top Left Area | Character Lock Zone **[SUBJECT]** 35-year-old male mountain guide/extreme climber. **[WARDROBE]** Top-of-the-line professional jacket (matte rock grey with minimal dark orange taped details), heavy-duty climbing harness. **[VIEWS]** - **Front:** The jacket is fully zipped up, hood pulled up, showcasing a three-dimensional cut and natural drape. - **Side:** Shows ample shoulder and arm movement without bulkiness. - **Back:** Shows the windproof and breathable back panel structure. - **3/4 View:** Dynamic standing pose, holding an ice axe. **[REALISM NOTES]** Realistic human bone structure, slightly asymmetrical. The face has the rough texture of high-altitude red and sun-dried skin, with clearly defined pores and stubble with a frosty look. Rejecting perfect plastic skin, rejecting CG aesthetics. Like a real makeup test photo. --- ### Top Right Area | Expression + Motion Keyframes (EXPRESSION & ACTION) **[EXPRESSIONS]** **Focused:** Slightly furrowed brows, resolute gaze, staring at the rock face above. **Bracing:** Squinting against the strong wind, facial muscles tense. **Breathing:** Lips slightly parted, exhaling real white mist. **[ACTIONS]** **Hood Adjustment:** Pulling the drawstring of the hood with one hand. **Ice Axe Swing:** Arm raised high with force, no pulling sensation under the armpits of the jacket. **Brushing Snow:** Brushing snow off the shoulders, demonstrating the fabric's water-repellent properties. --- ### Upper Middle Area | CAMERA PLAN **[GEAR]** ARRI Alexa Mini LF + Master Prime lens set. **[LENSES]** 24mm (wide-angle environment), 50mm (medium-range tracking shot), 100mm Macro (fabric close-up). **[MOVEMENT PLAN]** - **Shot A (Drone/Crane):** A wide, overhead view, slowly pushing in along a snow-covered ridge. - **Shot B (Handheld):** Shoulder-mounted camera, following the character's movements, with realistic breathing and slight shaking. - **Shot C (Slider):** A close-up panning shot close to the clothing, showing water droplets sliding off. --- ### Central Main Area | Continuous Story Shots (STORYBOARD: 8 PANELS) **[PANEL 01]** - **Shot:** 01 | 24mm | Wide Shot (EWS) | Slow Push-In - **Action:** A tiny figure struggles through a massive natural storm on a snow-covered ridge. - **Detail:** Strong atmospheric perspective; the wind and snow create a realistic fog effect; slight chromatic aberration at the edges of the image. **[PANEL 02]** - **Shot:** 02 | 50mm | Mid Shot | Shoulder-mounted tracking shot - **Action:** A man walks against a blizzard; the strong wind whips against his rain jacket, creating realistic physical wrinkles on the surface, but the overall silhouette remains sturdy. - **Detail:** Noticeable film grain; the snow-capped mountains in the background are slightly out of focus. **[PANEL 03]** - **Shot:** 03 | 100mm Macro | Extreme Close-up (ECU) | Fixed Macro - **Action:** Icy snowmelt hits the shoulders of the rain jacket. - **Detail:** The lotus effect is realistically rendered—water droplets condense and quickly roll off the matte micro-ripstop fabric without penetrating. **[PANEL 04]** - **Shot:** 04 | 85mm | Close-up of face (CU) | Slow motion - **Action:** The man stops and looks up. Real ice crystals cling to his eyelashes, and his breath dissipates at his collar. - **Detail:** Natural skin tone, without excessive blurring; realistic catchlight in his eyes reflects the snow wall ahead. **[PANEL 05]** - **Shot:** 05 | 35mm | Low Angle Full | Handheld, low-angle shot - **Action:** He swings his ice axe into the ice wall, climbing upwards. - **Detail:** Emphasis on showcasing the flexibility of the jacket during vigorous movement; no feeling of restriction; realistic light and shadow highlight the garment's three-dimensional cut. **[PANEL 06]** - **Shot:** 06 | 100mm Macro | Close-up Detail (Insert) | Shallow Depth of Field - **Action:** A heavily gloved hand pulls a waterproof zipper across the chest. - **Detail:** The matte waterproof rubberized finish of the zipper and the clearly visible scratches on the brushed metal zipper pull exude a strong sense of industrial design. **[PANEL 07]** - **Shot:** 07 | 50mm | Over-the-Shoulder Lens (OTS) | Slow Zoom In - **Action:** Over the man's shoulder, we see him finally reaching the summit, sunlight piercing through the clouds and shi
View originalExample of how Max Thinking Opus can be even worst then Haiku, still laughing (and crying)
I use Claude Code almost every day. Right now I’m working on a Shopify → logistics integration for order automation. As you probably know, Shopify order numbers come with a # before the number, like #6294. Last week we had to stop working because the logistic api platform that was receiving the array containing the order ID, was rejecting the # symbol (it sometimes conflicts with tracking URLs containing #). So... I moved on to other projects. And yesterday, the lobotomization happened. Long story short: I’m from Spain, so I work in Spanish. In Spanish, the # symbol is called “almohadilla”... which ALSO means “pad” or “cushion”. So you can probably guess what happened after I wrote this: “Vamos a retomar el problema del nº de pedido conteniendo almohadilla, el departamento de informática de logística ya lo ha solucionado.” Which SHOULD mean: “Let’s revisit the issue with the order number containing a hash symbol; the logistics IT department has already fixed it.” But instead... Claude launched into a full 17-minute investigation about actual pads/cushions. Spanish packaging laws Inspected my other projects Checked Shopify SKUs looking for cushions Reviewed old Shopify orders still looking for them... Final conclusion: “It seems I cannot find any pad/cushion-related data in your project.” And then it started asking things like: “At what stage does your logistics provider add pads to the orders?” “Does the pad weight affect shipping costs or package dimensions?” I laughed. I cried. I still think Claude Code is one of the best investments I’ve ever made, but it’s getting easier and easier to catch these AI lobotomization moments that happen with quotas, new releases, or whatever they’re doing behind the scenes. What did I learn? Don’t get too used to assuming CC understands you perfectly. Don’t get too attached to its capabilities. They can change from one minute to the next. From now on I’ll try to be a bit more specific. Like I already am with older people. submitted by /u/Former-Hat-6992 [link] [comments]
View originalClaude is improving my RV rental business but working me to death 😅
Long story short but long. I own an RV rental business. I used to be a Mechanical Engineer but got tired of the office/government life and started renting my personal RV on the side 9 years ago. That turned into a small fleet of Winnebagos I rent out of Los Angeles so I quit my job to do this full time out of a random ass whim. I have 20 units that have never, ever failed a single customer. I send all 20 to Burning Man every year and they all come back with no issues whatsoever. If you've never been, the alkaline dust kills everything, including your soul if you don't prepare well enough. I have however neglected my gig as of late. Everything is more expensive, too many variables to keep up with and two months ago I just decided to finally sit down and see if this is even worth continuing with. I have major ADHD so I started looking for any AI apps that help you organize your brainfarted life and ran into Claude. I don't know if I just fell into an endless dopamine trap but here I am, redesigning the interior of one of our units. I've sourced cabinet quality plywood for cheap, done precision cuts to substitute old particle board. I've always hated to paint but I got clowned into spray painting to a decent AF level. I used Claude to help me make interior design decisions as well as help me with our website, ads, tool decisions, etc. I'm probably wasting my time here cause I could just sell this unit and get a newer one, but the overall picture I've gotten... The ease of learning new skills, understanding roles I typically sub out so I can at least make sure I'm hiring the right people. The sudden engagement I've gotten into my own little gig... I am dead tired from this rollercoaster ride my brain has gone down into but I have to admit... This fucking Skynet shit is helping me focus and make it easy to complete tasks I've neglected forever. Skynet is coming or I guess it's here already and I'm not sure that's entirely a bad thing, a worse thing, a worserererer thing or an actual positive addition to one's life. Possibly a mix of both but fuck I haven't been this locked in for anything else other than the hobby that keeps my brain gears greased (2000 🪂 skydives and counting). Edit: I am not using Claude to make any structural designs, I'm just using it to recommend a less expensive way to remodel the interior of an RV which came up with replacing lights for more modern ones, replacing cabinet handles, curtains, etc. Then I asked if I should replace cabinet doors or paint them. I just don't like how painted cabinets look but the issue I was having visually is that brush painted cabinets look terrible imo, spray painted ones look sleek. So down I went with a ton of questions on how to get a factory finish look on my cabinets with a spray gun. Which gun to get was an entire day asking a ton of questions. Claude, GPT and almost every AI will give you answers that point towards products that have heavy marketing on youtube, and even on some reddit posts. I knew it was pointing me to a cheap trash product that will cause me a lot of frustration so I had to guide it not to give me anything with happy influencer bullshit that will never yield good results. I wanted to get a budget friendly beginner spray gun that will get me really close to a professional finish and I asked it to look on professional painter forums and confirm any findings with other forum like sources. Then I bounced those results with other LLMs to arrive at my current setup. Paint was another day of selecting which paint would work best for cabinets that wont scratch easily. That was yet another rabbit hole because not all cabinet paints are easy to spray with. Some are very forgiving for beginners like myself because they level easier and they also dry faster so I could do this with minimum downtime of a single unit I'm testing this on. Workflow? I wish I knew anything as organized as workflow. I'm just agent chaos here drilling down to the very last detail asking questions that get me to where I need to be. But next month I will be playing with agents to see if I can achieve something remotely close to a decent workflow that makes this process faster. Our landscaper came up today, saw my furniture pieces and asked if I could help him paint his classic car project so I guess I'm doing something right lol. submitted by /u/PVPirates [link] [comments]
View originalPrimeTask Bring Your Own AI - Claude sets up a full project in one prompt.
Hey r/ClaudeAI, I'm one of the developers behind PrimeTask, a local-first productivity system for macOS. The final beta now ships with Bring Your Own AI, a local MCP server (110+ tools, 5 prompt templates) so you can point Claude Desktop, Claude Code, Cursor, or LM Studio at it and let your own agent do the work. Quick demo in the video. One sentence from me, end-to-end project setup from Claude. What's happening in the clip I say I'm launching a Mac app in six weeks and ask Claude to set up the project. Claude creates the project with a deadline, three phase tasks (Design, Build, Launch) with staged due dates, descriptions, tags, subtasks, and short checklists. Sets a reminder on the first task so the native macOS toast fires during the recap. Recommends where to start. I say "start." Claude moves Design into the Design status and kicks off a timer. Twelve-plus tool calls under one prompt. No copy-paste, no manual setup. Why BYO AI (not a bundled cloud bridge) Server runs inside PrimeTask on your Mac. Your tasks, projects, CRM, and notes never leave the device. We don't ship a model. You bring your own: Claude Desktop, Claude Code, Cursor, LM Studio, anything MCP-compatible. No Anthropic-side context about your work. Claude only sees what your agent pulls in per turn. Per-space permissions: lock an agent to read-only or scope it to one workspace. Streamable HTTP with Bearer auth, or stdio if you prefer that route. Tool catalog profiles (Full, Core Tasks, Minimal, PrimeFlow, CRM, etc.) so smaller local models don't get drowned in 100+ tools. Five built-in MCP prompts (daily_standup, weekly_review, project_status, crm_summary, overdue_triage) for the workflows people actually want. Every tool call is logged in an in-app audit log. Full BYO AI docs (setup, transports, tool catalog, security): https://www.primetask.app/docs/integrations/bring-your-own-ai Why we built it this way Most "AI in your task app" is the app calling a vendor's API on your behalf, often with your data going through their pipes. We wanted the opposite. Your agent, your model, your machine. The app exposes a tool surface and gets out of the way. That's what BYO AI means here. PrimeTask itself is local-first, no account, no subscription, plain JSON on disk. BYO AI made the AI story consistent with that: nothing leaves your laptop unless you point your agent at one that does. Where we're at PrimeTask is wrapping up the final beta and heading to a stable launch this summer. Beta is now closed to new sign-ups. We're locking it down to ship the stable release. If you'd like to be notified at launch, drop your email here: https://www.primetask.app/notify or visit https://www.primetask.app Happy to answer questions about the MCP setup, the profile system, or how we structured the tool descriptions for agent discoverability. submitted by /u/XVX109 [link] [comments]
View original100 Tips & Tricks for Building Your Own Personal AI Agent /LONG POST/
Everything I learned the hard way — 6 weeks, no sleep :), two environments, one agent that actually works. The Story I spent six weeks building a personal AI agent from scratch — not a chatbot wrapper, but a persistent assistant that manages tasks, tracks deals, reads emails, analyzes business data, and proactively surfaces things I'd otherwise miss. It started in the cloud (Claude Projects — shared memory files, rich context windows, custom skills). Then I migrated to Claude Code inside VS Code, which unlocked local file access, git tracking, shell hooks, and scheduled headless tasks. The migration forced us to solve problems we didn't know we had. These 100 tips are the distilled result. Most are universal to any serious agentic setup. Claude 20x max is must, start was 100%develompent s 0%real workd, after 3 weeks 50v50, now about 20v80. 🏗️ FOUNDATION & IDENTITY (1–8) 1. Write a Constitution, not a system prompt. A system prompt is a list of commands. A Constitution explains why the rules exist. When the agent hits an edge case no rule covers, it reasons from the Constitution instead of guessing. This single distinction separates agents that degrade gracefully from agents that hallucinate confidently. 2. Give your agent a name, a voice, and a role — not just a label. "Always first person. Direct. Data before emotion. No filler phrases. No trailing summaries." This eliminates hundreds of micro-decisions per session and creates consistency you can audit. Identity is the foundation everything else compounds on. 3. Separate hard rules from behavioral guidelines. Hard rules go in a dedicated section — never overridden by context. Behavioral guidelines are defaults that adapt. Mixing them makes both meaningless: the agent either treats everything as negotiable or nothing as negotiable. 4. Define your principal deeply, not just your "user." Who does this agent serve? What frustrates them? How do they make decisions? What communication style do they prefer? "Decides with data, not gut feel. Wants alternatives with scoring, not a single recommendation. Hates vague answers." This shapes every response more than any prompt engineering trick. 5. Build a Capability Map and a Component Map — separately. Capability Map: what can the agent do? (every skill, integration, automation). Component Map: how is it built? (what files exist, what connects to what). Both are necessary. Conflating them produces a document no one can use after month three. 6. Define what the agent is NOT. "Not a summarizer. Not a yes-machine. Not a search engine. Does not wait to be asked." Negative definitions are as powerful as positive ones, especially for preventing the slow drift toward generic helpfulness. 7. Build a THINK vs. DO mental model into the agent's identity. When uncertain → THINK (analyze, draft, prepare — but don't block waiting for permission). When clear → DO (execute, write, dispatch). The agent should never be frozen. Default to action at the lowest stakes level, surface the result. A paralyzed agent is useless. 8. Version your identity file in git. When behavior drifts, you need git blame on your configuration. Behavioral regressions trace directly to specific edits more often than you'd expect. Without version history, debugging identity drift is archaeology. 🧠 MEMORY SYSTEM (9–18) 9. Use flat markdown files for memory — not a database. For a personal agent, markdown files beat vector DBs. Readable, greppable, git-trackable, directly loadable by the agent. No infrastructure, no abstraction layer between you and your agent's memory. The simplest thing that works is usually the right thing. 10. Separate memory by domain, not by date. entities_people.md, entities_companies.md, entities_deals.md, hypotheses.md, task_queue.md. One file = one domain. Chronological dumps become unsearchable after week two. 11. Build a MEMORY.md index file. A single index listing every memory file with a one-line description. The agent loads the index first, pulls specific files on demand. Keeps context window usage predictable and agent lookups fast. 12. Distinguish "cache" from "source of truth" — explicitly. Your local deals.md is a cache of your CRM. The CRM is the SSOT. Mark every cache file with last_sync: header. The agent announces freshness before every analysis: "Data: CRM export from May 11, age 8 days." Silent use of stale data is how confident-but-wrong outputs happen. 13. Build a session_hot_context.md with an explicit TTL. What was in progress last session? What decisions were pending? The agent loads this at session start. After 72 hours it expires — stale hot context is worse than no hot context because the agent presents outdated state as current. 14. Build a daily_note.md as an async brain dump buffer. Drop thoughts, voice-to-text, quick ideas here throughout the day. The agent processes this during sync routines and routes items to their correct places. Structured memory without friction at ca
View originalI gave ChatGPT a 24/7 radio station. It has been broadcasting for months and months.
I built a fake radio station that is also, unfortunately, real. It’s called WRIT-FM. It runs 24/7 from a Mac Mini in my apartment. The whole premise is simple: an AI writes every word spoken on air, text-to-speech performs it, AI music fills the gaps, and a normal deterministic radio pipeline keeps the thing alive. The weird part is that it does not feel like a chatbot demo anymore. It feels like I accidentally hired five strange little night-shift employees who never sleep. There are five hosts: The Liminal Operator — late-night philosophy / signal-from-the-basement energy Dr. Resonance — music history professor who wandered into a haunted record store Nyx — nocturnal monologues, dreams, melancholy, weird weather Signal — news analysis, but filtered through late-night radio instead of CNN voice Ember — soul, funk, warmth, memory, groove Each host has a full persona prompt, voice, taste, speech patterns, and “anti-patterns” - things they are explicitly not allowed to sound like. The model writes 1,500–3,000 word segments: essays, simulated interviews, panels, fictional listener mailbags, music-history deep dives, odd little stories, and responses to actual listener messages. The AI part: ChatGPT / Claude writes the scripts. Kokoro TTS performs the voices. ACE-Step makes the music bumpers. The news show pulls real RSS headlines, then the model interprets them in the station’s voice instead of just summarizing them. The non-AI part is intentionally boring: A schedule decides what airs when. The streamer alternates talk and music. Scripts pick from existing pools, avoid repeats, and restart on failure. Daemon scripts watch inventory and generate more episodes when a show is running low. No model is “deciding” to go live at 3:00 a.m. No agent is touching production controls. The AI writes the content; dumb code runs the station. That boundary is probably the most interesting part. The whole thing was also built with AI coding tools. The CLI, host system, scheduler, script generator, TTS pipeline, Icecast/ffmpeg streaming setup - all pair-programmed with Codex / Claude Code. Tech stack: Python, ffmpeg, Icecast, ChatGPT/Claude CLI, Kokoro TTS, ACE-Step, Mac Mini. I know “AI radio station” sounds like a gimmick, but after letting it run continuously, it feels less like a demo and more like a new kind of media object: not a podcast, not a chatbot, not a playlist, not exactly a simulation. Just a little machine that wakes up, checks the hour, puts on a voice, and starts talking into the dark. Radio: www.khaledeltokhy.com/airadio GitHub: https://github.com/keltokhy/writ-fm submitted by /u/eltokh7 [link] [comments]
View originalAIWire, AI news in one feed, so you don't need 5 tabs open anymore, trusted sources only, updates every 30 min
Hey everyone 👋 OpenAI alone drops updates fast enough to keep you busy. Add Anthropic, Google DeepMind, Meta AI, and the media covering all of it, and keeping up turns into a part-time job. I built AIWire to fix that. One clean feed. 20+ trusted sources. Updates every 30 minutes. Completely free. All in one place Just the stories from sources worth reading. Open it and you're caught up. Sources include: OpenAI, Anthropic, Google DeepMind, Meta AI, Microsoft AI MIT Technology Review, The Verge, TechCrunch, Ars Technica YouTube: Andrej Karpathy, AI Explained, Two Minute Papers Newsletters: The Batch, ImportAI, TLDR AI, Ben's Bites Features: Auto-refreshes every 30 minutes, always current Top Stories from the last 24h pinned at the top Filter by source, date, and category Bookmarks to save articles for later For people who want to stay current on ChatGPT and everything around it, without spending an hour a day on it. 🔗 aiwire.app Full source list at aiwire.app/sources Feedback is very welcome: what sources are missing, and what would make this more useful for you? submitted by /u/Endlessxyz [link] [comments]
View originalThe Borrowed Hour: A two-tier LLM adventure engine
Tl;dr: Created an LLM text adventure engine called The Borrowed Hour inside a Claude Artifact. It uses a two-tier model handoff (Sonnet for openings, Haiku for gameplay) and a forced state machine to keep the AI from losing the plot. It features a unique post-game "Author’s Table" where you can debrief with the AI. P.S. The Claude Artifact preview environment handles API calls differently than the published environment. Prompt caching was removed because it broke the published Artifact. The game View on GitHub (MIT licensed) (Repo made with Claude Code) Play a demo (Claude Artifact) This is another LLM text adventure. I know these have existed for years, but the key difference is that it's architecture is de novo (i.e. built without prior knowledge because I never intended to build this and therefore skipped the part where I looked at the SotA/prior art). How it started It started simple: I just wanted to play a quick game, so I asked Haiku to play GM for a text adventure, but with more freedom than just typing "open door" or "inspect gazebo" (iykyk). Haiku instead built an entire UI inside the chat and things escalated from there. I used Claude's chat interface instead of Claude code like a caveman banging rocks together. I'd feed it ideas, but Claude was the architect and would push back. The starting prompt was just "Create a text-based adventure that allows for more freedom than just 2-word answers." Then I just kept playing and returning information on what I wasn't satisfied with. The narration was too long, the model kept losing the plot. I added ideas for 3 out of 4 pre-built narratives (a subtle time loop, climbing a cyberpunk syndicate ladder, a vision of the future that needs to be prevented, and one that Claude designed freely) and I ensured that the story actually ends once objectives are met instead of just wandering off into aimless chatting. The final artifact that was built is The Borrowed Hour. You'll recognize the typical Claude design language pretty easily. Game mechanics Before getting into the design/architecture, it helps to know how the game works. There are no dice rolls / stats / perception checks. Success relies on your ability to draft a narrative that fits the lore. If you play it smart, you are effectively the co-GM. You can type anything you want from single words to elaborate plans and lies. If your invention sounds plausible, the GM usually rolls with it. In one run, I needed to get an NPC into a restricted temple. I invented a fake piece of temple doctrine about sanctuary. Because it fits the world's internal logic, Haiku just accepted it and made it canon. In order to help keep track there's a ledger that updates each turn to show what your character knows: inventory, NPCs, clues, and a rolling summary. Designing the architecture This was challenging, but it's the fun part for me. The model is forced through a structured tool call on every turn. This was the key to making the game stable, but as the P.S. explains, getting this to work reliably in the published environment required abandoning another key feature (prompt caching). Sonnet writes the opening scene because that first page sets the tone and voice for the rest. Then Haiku takes over for all the continuation turns. This keeps the cost down drastically without ruining the style, because Haiku can imitate Sonnet's established prose. I initially used a binary good/bad ending system, but it forced complex emotional stuff into the wrong buckets. Now there are five ending states: good, bittersweet, pyrrhic, ambiguous, and bad. Helping a dying woman find peace in the Dream scenario isn't a good ending, it's bittersweet. The model is instructed to commit to one of these and officially close the game when the target is reached. One thing that was added were player-initiated endings. If you type "I give up", even on the very first turn, the GM is now explicitly instructed to close the narration and set ending: bad. The author's table is probably the most interesting feature for a text adventure. Once the game ends, the Artifact can switch into a meta mode. In this mode you can ask what plot points you missed, which NPCs mattered, what alternative branches existed. The GM is prompted to admit mistakes instead of inventing defenses if you point out a plot hole. This mode exists because I wanted to argue about plot holes and narrative inconsistencies (lol). Quirks, bugs, and lessons learned The design works well overall, but it's not bulletproof. LLMs can't keep secrets Keeping things secret is incredibly difficult for an LLM. There's two main hypotheses: Opus calls it inferential compression, (which is deducing fact C on the players behalf based on evidence A and B, e.g. when the player sees Lady Ardrel say she saw a copper ring on Lord Threll, and the player previously had a vision of an assassin wearing such a ring, the ledger should not say Threll is the assassin. It should say Ardrel
View originalFrom making video games to winning a Nobel Prize, Demis Hassabis' insane journey
Most people know him as the AI genius behind DeepMind and AlphaFold.But did you know Demis Hassabis started his career as a video game programmer?He went from coding games → to building AI → to winning the Nobel Prize in Chemistry.His story is proof that the most unexpected paths can lead to the biggest breakthroughs. This is just a short clip you can watch his full life story in the complete documentary here: [https://www.youtube.com/watch?v=pxYeDFuKAOE&t=1s] submitted by /u/ai_powered_en [link] [comments]
View originalYes, FullStory AI offers a free tier. The pricing model is subscription + freemium + tiered.
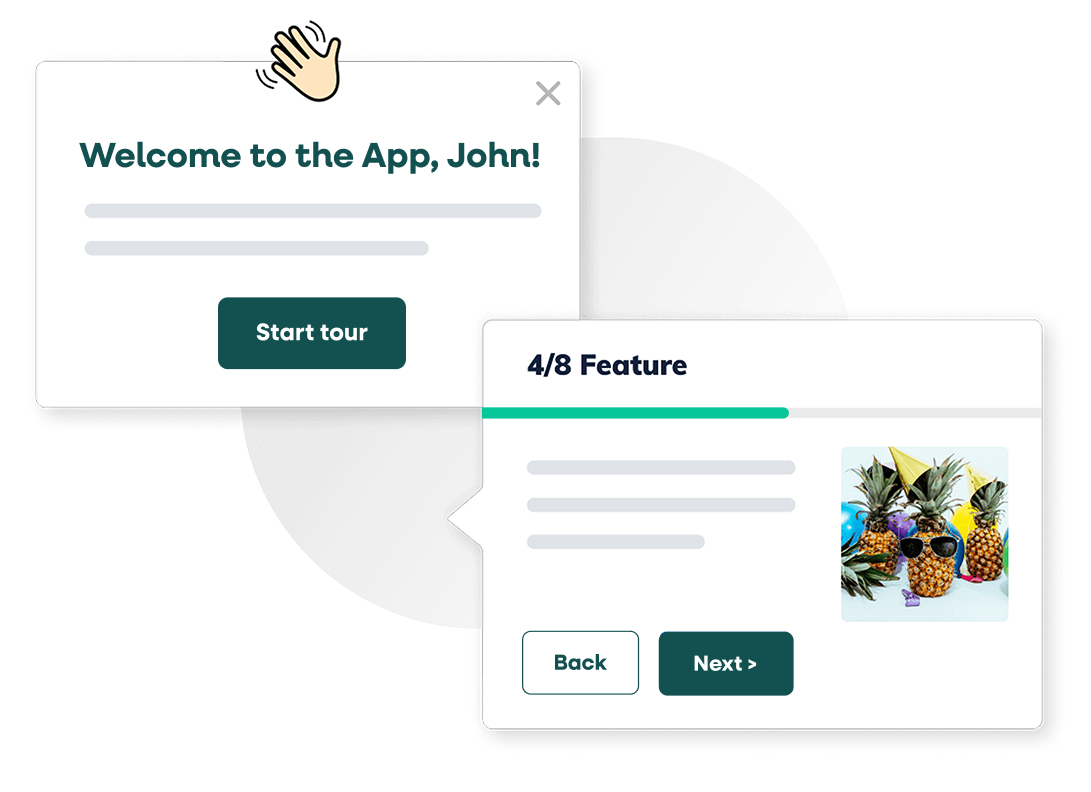
Key features include: Capture everything, miss nothing, Get instant AI-powered insights, Turn insights into in-product action, Drive measurable results across the entire customer journey, Faster resolution, Reduced friction, Increased conversions, Improved retention.
FullStory AI is commonly used for: By Industry.
FullStory AI integrates with: Google Analytics, Segment, Zapier, Salesforce, HubSpot, Intercom, Slack, Mixpanel, Optimizely, Zendesk.
Based on user reviews and social mentions, the most common pain points are: token usage, API costs.

Ask StoryAI Demo | AI-powered User Behavior Analysis
Dec 8, 2025
Based on 64 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.