Digits is AI-native accounting software with 24/7 automated bookkeeping, real-time financials, AI Bill Pay, and invoicing. Free trial.
"Digits" is praised for its user-friendly interface and effective integration of real-time financial data, which users find enhances their decision-making processes. However, some complaints highlight occasional data sync issues and a desire for more robust customer support. Sentiments around pricing are mixed, with some users appreciating the value for money, while others feel it's somewhat expensive for smaller businesses. Overall, "Digits" enjoys a positive reputation for its innovative features but has room to improve in service stability and support.
Mentions (30d)
57
14 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive
"Digits" is praised for its user-friendly interface and effective integration of real-time financial data, which users find enhances their decision-making processes. However, some complaints highlight occasional data sync issues and a desire for more robust customer support. Sentiments around pricing are mixed, with some users appreciating the value for money, while others feel it's somewhat expensive for smaller businesses. Overall, "Digits" enjoys a positive reputation for its innovative features but has room to improve in service stability and support.
Features
Use Cases
Industry
information technology & services
Employees
78
Funding Stage
Series C
Total Funding
$97.5M
Average LinkedIn profile today
Average LinkedIn profile today
View originalBest way to build a modern WordPress digital product website with Claude Code?
I’m trying to build a serious digital product website in WordPress using Claude Code, and I want to do it the right way from the beginning. The goal is not just making a pretty WordPress site — I want something optimized for: conversions SEO fast loading speed mobile UX scaling products later organic + paid traffic clean modern UI Right now I feel like I’m approaching this the wrong way, especially with AI-assisted development. For people already building with Claude Code or similar AI coding tools: Is it smarter to rebuild the website completely? Or optimize the existing WordPress template? What WordPress stack works best in 2026? Elementor, Bricks, GeneratePress, custom theme, or headless WordPress? What prompts give the best frontend/UI results with Claude Code? How do you structure pages for actual conversions? What plugins are best for SEO + speed optimization? Any workflow for automating layouts/design/content with AI? I’m especially interested in: real workflows prompt engineering WordPress optimization AI-assisted design systems conversion optimization traffic generation methods that still work in 2026 Would really appreciate advice from people already getting real results with AI-built WordPress websites. Also curious: What’s your actual workflow from idea → design → development → optimization → traffic? submitted by /u/7amsel [link] [comments]
View originalReplacing 6-figure HubSpot agency quoted with Claude Code - here's how.
Quick note up front: this post was drafted with Claude. I've been a lurker in this sub for a long time and wanted to actually contribute something back, in case it helps someone thinking about a similar build. The experience, the decisions, the numbers are mine — Claude just helped me structure the write-up. We're a mid-sized e-commerce company. ~15 product spread across direct sales (Shopify), subscriptions (Recharge), affiliate/digital (Digistore24 + GoAffPro), plus a small ads stack (Meta + Google). Needed to migrate to HubSpot Enterprise — Zoho CRM, Zoho Desk, and KlickTipp all retiring at once. We talked to four HubSpot Solutions Partners. Quotes: 20k EUR (templated setup, basically a wizard), 35k, 55k, 80k EUR (mid-tier custom objects + 2-3 integrations). None of them would handle our actual stack end-to-end — custom middleware for sync/reconciliation isn't standard partner repertoire. We'd own that part with our own dev resources either way. I decided to build it with Claude Code — the desktop app, not the API. Mostly Opus 4.7. Subscription plan, no usage-based billing. Four months in. Here's what actually works. What got built (numbers, not narrative) 6 Custom Objects + ~100 properties + associations 5 source-system integrations on self-hosted n8n: Shopify, Digistore24, Recharge, GoAffPro, Cart-Notifier — each with inbox pattern, idempotent upserts, reconciliation, backoff/retry, audit trail 1 custom Cloud Run service for inbox-polling at 15s cadence 10 Lifecycle stages + Funnel/Segment property layer Aggregator workflow that backfills 9 contact properties from sync-mirror objects (idempotent, Postgres cursor, cron-driven) KlickTipp migration: 202 tags audited, custom object for webinar registrations, consent governance Google Ads CAPI (11 conversion actions, enhanced conversions) + Meta CAPI (Pixel + server-side, layer 2 in progress) 33 ADRs (architecture decisions, append-only, never deleted) ~30 implementation sessions with Claude Code, ~2-4h each If anyone delivered all of this end-to-end as an agency: realistically 120-180k EUR Netto. Most can't, because the custom middleware part isn't in their wheelhouse. The biggest mental shift: Claude Code isn't (just) a coding assistant This is the part most people miss. "Claude Code" sounds like an IDE tool for writing code. In our setup, maybe 20% of what's in the repo is actual code. The other 80% is Markdown — architecture decisions, integration specs, runbooks, cheatsheets, ADRs. The repo is the system-of-record for how the business runs in HubSpot. Custom objects, properties, workflows, lifecycle stages, consent governance, naming conventions — all documented as Markdown alongside the few scripts we actually need. When code IS needed, Claude writes it. A Python helper to regenerate an index file, a backfill script for historical orders, a Cloud Run service for inbox-polling — Claude writes those on demand and they live in the repo. When workflow logic is needed, we delegate to n8n. We don't try to make Claude write hand-tuned automation code; we describe the workflow and Claude builds or updates the n8n workflow via the n8n MCP server. Low-code where it makes sense, real code where it doesn't, Markdown for everything else. The result: a single repo that is simultaneously documentation, configuration, and code. Any new session — mine or future contributors' — can read it and understand the entire business architecture in HubSpot, not just the codebase. The other big lesson: the repo IS the memory between sessions Claude Code sessions are stateless. Every conversation starts fresh. If you treat that as a problem, you'll hate the workflow. If you treat it as a design constraint, you build a system where state lives in files, not chat history. Concretely: ADRs capture every architecture decision with reasoning and trade-offs. New sessions read them and don't re-debate. Spec files per integration/area, each with a Status header. Single source of truth for "is this implemented, what's the current state." Slash commands (/implement, /verify, /new-task) encode the workflow. They're not just shortcuts — they enforce discipline. Definition-of-Done gate before commit, drift checks against live state, atomic status updates. Tool-class cheatsheet: which HubSpot operations work via standard API tools, which need direct API calls, which need UI clicks. Eliminates trial-and-error per session. Known-bugs cheatsheet: every quirk we hit (HubSpot search index latency, Recharge enumeration-vs-bool, n8n auth races) gets curated. Next session starts knowing what's known. Context7 MCP for current API docs. Claude's training data isn't current, and HubSpot/n8n APIs change. Before any external call, Claude does a Context7 lookup against the actual current docs. Skipping this used to cost us hours of trial-and-error against deprecated endpoints. Now it's a required step in /implement. Claude reads the relevant files at the start of each s
View originalWhy do calm AI conversations sometimes feel less exhausting than social media?
Lately I’ve noticed that a lot of people seem emotionally drained from constant social media interaction, notifications, and online pressure. But interestingly, many people seem completely comfortable talking to AI for hours especially when the interaction feels calm and non-judgmental. It’s interesting how many users say they don’t even want “romantic AI.” Do you think AI companionship could eventually become part of digital wellness rather than just entertainment? submitted by /u/Nearby-Ad-8924 [link] [comments]
View originalAnthropic just confirmed why 90% of non-coding AI agents fail in production
Anthropic recently published an incredibly deep breakdown analyzing millions of real human-agent tool calls across their public API, and they shared a breakdown of where these agents are being deployed. They said “Software engineering makes up roughly 50% of all agentic activity on their platform”. Everything else: sales, marketing, finance, legal is sitting down in the single digits. A lot of the initial commentary around this has been along the lines of: "Oh, look, AI agents only work for coding. They haven't cracked the rest of the enterprise yet." But if you’ve tried to build and deploy an autonomous agent in a non-coding environment, you know that is the wrong conclusion. The models are more than capable but the real problem is that software engineering data is clean, while real-world business data is a horrific and unorganized. Think about it: Why Coding is Easy for Agents: Code lives in structured Git repo. It follows strict syntax rules, has clear docs and runs inside deterministic terminals. If an agent breaks something, the compiler throws a clean error message telling it exactly what went wrong. Why the Rest of the World is Hard: A sales or marketing agent doesn’t get a clean github repo instead you’re constantly dealing with changing information like competitor pricing and badly formatted data. When a non-coding agent fails, it’s almost never because the model lost its ability to reason but cause it gets choked out by unstructured web data that fills up its context window with thousands of useless tags and tracking scripts until it hallucinates. The developers getting agents to work in those low-percentage brackets on Anthropic's chart (like automated market research or live CRM routing) are usually spending most of their time on the boring infra work behind the scenes such as clean inputs, reliable scraping and that’s the part that really makes the difference. If you look at a modern, high-reliability agent stack outside of coding, it usually relies on three things: The Core Reasoner: Something fast with a massive context window like Claude Sonnet to handle the logic. Data Hygiene at the Gateway: Instead of letting the agent scrape raw web URLs directly (which triggers bot blocks and inputs HTML that will need to be revised), developers feed the internet data through dedicated markdown converters with tools like Firecrawl or Jina Reader are pretty standard here and the agent gets pure text, saving token costs and preventing hallucinations. The Guardrail Layer: Traditional code hooks or rules engines that check the agent’s output before it executes an irreversible action (like sending an email or updating a database record). The low adoption numbers in the rest of the enterprise doesn’t mean agents are overhyped. In most industries, the surrounding tooling just still kind of sucks so once the data side gets more reliable, you’ll probably see adoption spread a lot faster outside engineering What are your thoughts on this? For those building agents in finance, marketing, or operations, I would love to get your thoughts here! submitted by /u/Loud-Campaign-6312 [link] [comments]
View originalWhy are people who moan about AI taking-over or diminishing human capabilities so unimaginative?
I give one example of an imaginative and inspiring account of AI in Richard Powers’ novel *The Overstory*. One character in the book stands out for me. Neelay Mehta is a precocious child who through the influence of his father becomes engrossed in the ‘branching’ possibilities of computer programming. At the age of eleven, Mehta climbed a tree, slipped and crashed down onto a concrete path. The base of his spine was cracked, leaving him paralyzed. He spends the rest of his life in a wheelchair and becomes progressively disabled and at the same time absorbed with building his computer game. Mastery is continually upgraded with the help of an expert team, eventually gathering millions of users world-wide. The game immerses players in a vivid virtual world and beats all competition. It provides Mehta with wealth to plough back into his enterprise, but he eventually becomes dissatisfied with his invention, realizing that although the game pretends to escape into another world, it simply mirrors a world that is driven by competitiveness and the endless desire for more prosperity. It is so successful because everyone wants to expand their virtual ‘empire’, and the game keeps making opportunities a little more tempting. Faced with this dilemma, Mehta seeks a ‘better story’. He finds inspiration for recasting his game through studying trees, especially fungal networks that connect them together and discovers *The Secret Forest* written by another main character in the novel, Pat Waterbrook. Her book shows how the mycelium of fungi ‘actively senses and responds to its surroundings in unpredictable ways forming a symbolic negotiation with trees’. She discovers that research from different perspectives uncover ‘innumerable minute, local truths’ and can spread a global net of their studies, ‘sapping data through ever faster channels’. Early in his life, Mehta had realized that computer algorithms connect like ‘organelles building up a cell’.Mehta reenvisages his game of Mastery as a ‘growing organism’ that adds to itself, with thousands not so much playing the game as *contributing* across the globe, adding their own data and codes. Contributors, who are called ‘learners’ are encouraged to absorb everything, including ‘every sentence from every article that every field scientist has published; every sound of the earth; every landscape pictured, the data of every creature’. With the help of AI, the game can absorb how the planet and living things emerged, the history of bacteria, and the fungal networks of trees and also discover how things, bacteria and trees learn themselves. Through access to data banks, Mehta’s game aims to bring humankind to an intimate understanding of life’s evolution and *cast off* from the normal, familiar world. In Mehta’s words, it turns you into ‘something you weren’t’. The aim of the new game is not about winning or competition; it is not about accumulating a machine to make decisions; it is to grow ‘the world, *instead of yourself*’. The codes of the imaginary computer game take up the basic commands of ‘*look, listen, touch, feel, say, join’* (493 – original emphasis). The data plays, entangles, negotiates and merges as life has done for billions of years. Like some strands of Indigenous thought or the work of Aldo Leopold, Mehta’s game envisions the potential of a community of learners ‘will come to think like rivers and forests and mountains’. As some scientists are discovering, information and communication are prevalent throughout all nature. AI draws together data from diverse expertise and different ways of knowing and perceiving, to contribute to, and participate in a world that merges as one the virtual and the real, the artificial and natural, culture and nature. The experiment perhaps points to a future of digital nature. Mehta says: *He will not live to see it completed, this game played by countless people worldwide, a game that puts the players smack in the middle of a living, breathing planet filled with potential they can only dimly begin to imagine. But he has nudged it along*. submitted by /u/MichelSerres-discuss [link] [comments]
View originalThe Quality of Understanding...Dialogue over Division
Humanity has accumulated unprecedented amounts of information, yet despite extraordinary advances in intelligence and technology, civilization still struggles to understand itself with depth, wisdom, and clarity. We now live in an accelerated age shaped by endless data, instantaneous communication, and increasingly powerful systems capable of processing information at extraordinary speed. Yet despite these technological advances, many of humanity’s oldest struggles persist: division, fear, inequality, polarization, and recurring cycles of conflict. Perhaps the challenge has never been intelligence alone, but whether humanity develops the understanding and wisdom necessary to guide it responsibly. There is a profound difference between possessing information and truly understanding the human condition. Computational intelligence can analyze patterns and generate solutions, but understanding requires context, reflection, emotional awareness, and the willingness to see beyond oneself. Intelligence can accelerate decisions. Understanding determines whether those decisions lead toward flourishing or destruction. The instinct to rush toward faster solutions may ultimately deepen the very problems humanity hopes to solve. A civilization conditioned for acceleration may begin mistaking speed for progress, reaction for understanding, and certainty for wisdom. Understanding rarely begins through reaction alone. It begins through awareness. Yet modern civilization increasingly rewards the opposite. Outrage spreads faster than thoughtful dialogue, while certainty and conflict generate more attention than curiosity, reflection, or deeper understanding. The result is a culture increasingly shaped by fragmentation — fragmented thinking, fragmented empathy, and fragmented understanding. Perhaps it begins with learning to see people as human beings again rather than as usernames, ideological categories, or digital avatars. Behind every screen exists a real person shaped by experiences, fears, hopes, struggles, and emotions far more complex than any comment thread, profile, or algorithm. And yet many of humanity’s greatest advancements in ethics, justice, diplomacy, science, and human rights emerged not merely from intelligence, but from a deeper understanding of suffering, consequence, interconnectedness, historical patterns, and the shared humanity within one another. What may be most necessary is also deeply counterintuitive: the willingness to slow down long enough to observe, reflect, and truly understand, and then to engage in more thoughtful forms of collective dialogue — spaces where ideas can be explored with curiosity, forethought, courtesy, and mutual respect. Most people naturally make decisions based on what benefits them or those closest to them; however, as technology becomes increasingly powerful and interconnected, humanity may need to ask a larger question: Who is intentionally considering what is best for humanity as a whole? Maybe it's time humanity begins thinking of itself not merely as billions of separate individuals, but as a shared civilization with collective needs, responsibilities, and long-term consequences. Our future will not depend upon outcompeting artificial intelligence in speed or informational capacity, but upon strengthening the qualities AI cannot fully replicate: empathy, conscience, moral reflection, lived experience, and the ability to create meaning through human connection itself. Humanity’s greatest strength may ultimately lie not in becoming more machine-like, but in deepening those qualities that make us very much human. 🌿 submitted by /u/Sage-Vero [link] [comments]
View originalanyone else seeing claude code rot after long sessions? here's the operating pattern that stopped it for me
i've been running claude code for long multi-hour sessions on real work. the same eight failure modes keep showing up no matter which sonnet/opus version, no matter which task. wrong context selected. memory loaded as noise. stale state treated as live. multiple plans never collapsed into one action. "i should check the test output" without ever checking. corrections stored as identity-level shame instead of as next-action instructions. soft recommendations treated as hard law. long-session drift where intelligence quietly turns into narration. the model is fine. the room around the model is broken. the fix that actually moved my action-rate from single-digit to consistent double-digit was building a small operating contract around the model. one file. six rules. copyable. i ship the small public version of it on github: https://github.com/jaswalmohit8-collab/weasel (MIT) CLAUDE.md is the canonical operating contract. DEMO.md is a two-minute prompt you can paste right now to test the behavior shift. there are demo videos in the repo showing the same file running under kimi code and claude code, so you can see what the operating pattern looks like in practice. the named failure pattern is "recognition without arrest." the agent sees the constraint, says the right thing about it, ships the wrong action anyway. weasel is the practical side of that problem. not the research corpus, just an operating file that makes the next wrong action harder to take. the architectural argument behind it is in an X thread tonight: https://x.com/MohitJaswa27/status/2059412241691087178 what it covers beyond weasel: action-rate as a measurable scoreboard (PASS entries divided by total gated entries in an audit ledger), continuation before creation when the artifact already exists, temporal reality gate before any present-tense claim, predictive identity that updates the prior instead of preserving shame, and role-conditioned execution contexts instead of one monolithic agent persona. if you've been running claude code long enough to have hit drift yourself, the rules will probably feel familiar. if you have a tighter rule that prevents one of the eight failure shapes in your own setup, the repo is small and accepts issues + pull requests. that's how it should grow. small additions, tighter rules, before/after demos that change behavior. DEMO.md is the fastest path in. two minutes, no framework, no server, no hidden system. just a file you ask your agent to read. submitted by /u/Mother-Grapefruit-45 [link] [comments]
View originalFolder structure of the AI agent - after 6 weeks
The folder structure is not admin. It's the nervous system. When people imagine an AI agent, they picture the model, the prompts, maybe the tool calls. Almost nobody pictures the folders. That is exactly why most home-grown agents stall around month two. An agent's filesystem is where its identity, memory, work, and history physically live. A messy filesystem produces a confused agent — not metaphorically, literally. The model reads paths. The model picks files by name. The model writes new files based on patterns it sees in old ones. If your directory tree is chaos, every output drifts a little further from coherent. agentmia.beehiiv.com - newsletter about building agents Below is the layout I converged on after nine months and roughly four refactors. Steal the parts that fit; the principles matter more than the exact names. The numbering convention Folders are prefixed with a two-digit number: 01_, 02_, 09_, 99_. Two reasons: Sort order is meaning. Anything starting with 0 lives near the top. 99_ falls to the bottom. The most important directories are visually first; archives are visually last. You read the agent's brain top-to-bottom. Gaps are intentional. I jump from 04_ to 06_, from 09_ to 11_. The gaps are reserved insertion points. When a new domain emerges, it slots in without renaming everything. Two folders deliberately skip the prefix: Inbox/ and Outbox/. They are operational, not structural. They live above the numbered set because they are touched dozens of times a day. /mapped on desktop/ Inbox/ — the unprocessed pile Anything dropped into the agent's world starts here. Files I want it to ingest. Screenshots. Exports from other systems. PDFs that need parsing, gmail attachments, all downloads from chrome. The rule: nothing stays in Inbox. A dedicated processing routine classifies, routes, and deletes. If Inbox is non-empty for more than a day, the system is failing. Treat this like a real-world physical inbox tray. The point of a tray is that it gets emptied. Outbox/ — what the agent produced for you Every file the agent writes anywhere in the tree gets a copy here, simultaneously. When I open Outbox/, I see exactly what was generated this session — no spelunking through twelve subdirectories. This sounds redundant. It is not. Without it, "what did the agent do today?" becomes a hunt. With it, the answer is one click. Outbox is wiped during the next Inbox processing run. It is a viewing surface, not storage. .auto-memory/ — the hot memory The single most important directory in the system. Hidden by default because you should not be editing it manually. It holds the agent's working memory: user preferences, feedback rules, entity facts (people, companies, deals), active hypotheses, project pointers, session hot context. Roughly 400–500 small markdown files, each one a single topic. Why hidden? Because it is the agent's hot path. It loads from here every session. If I open the folder and start manually rearranging it, I am racing the agent. Treat it like a database, not a notebook. Why so many small files? Because the agent grep's by topic. One monolithic memory file becomes unreadable to the model around 50 KB. Many small files are easier to load partially, easier to index, easier to expire. 01_IDENTITY/ — who the agent is The constitutional layer. Name, role, voice rules, principle stack, visual system, behavioral defaults. This rarely changes. When it does change, everything downstream changes with it. I keep it as folder 01_ because every other folder is downstream of it. If you do not know who the agent is, you cannot know what its workflows should look like, or what it should remember, or how it should respond. 02_MEMORY/ — governance, not data A subtle but critical distinction: .auto-memory/ holds the data, 02_MEMORY/ holds the rules about data. In 02_MEMORY/ live the constitution, the boot protocol, the naming protocol, the decision protocol, the profile standards (what a "supplier profile" must contain, what a "customer profile" must contain), the capability map. The agent reads these documents to know how to remember, how to name new files, how to decide what is reversible. Without this folder, every memory write is improvised. 03_PROJECTS/ — the active work Real work happens here. Sub-organized by goal area, then by project slug: 03_PROJECTS/areas/{goal}/{slug}/ Each project gets its own folder with a standard skeleton: README.md, TASKS.md, CHANGELOG.md, BRIEF.md, plus working files. There is a project registry at the top that the agent reads to know what is active versus dormant versus archived. The biggest discipline issue here: do not let projects sprawl outside their folder. When working on Project X, every file related to Project X goes inside Project X's directory. The temptation to drop "just one PDF" elsewhere is what kills the structure. 04_PROMPTS/ — the reusable prompt library Named, versioned prompts the user (or the agent) can sum
View originalIs “AI employee” becoming a real product category?
I spent some time mapping companies that publicly describe their products as AI employees, digital workers, AI teammates, or role-based agents. The pattern was more concrete than I expected. A lot of the market is not positioning around general intelligence. It is positioning around a specific recurring job: - AI SDRs and sales agents - AI customer support agents - AI recruiters - AI accountants and finance agents - legal and compliance agents - software engineering and SRE agents - security / SOC analysts - healthcare admin agents - broader AI workforce platforms What stood out to me is that “agent” is still a vague technical word, but “AI employee” is a very direct buyer-facing claim. It implies ownership of work, not just assistance. That raises a few questions: Is “AI employee” a useful category, or just aggressive marketing language? Which workflows are actually ready for this framing? Do buyers want named role-based AI workers, or will this collapse back into normal workflow automation software? My current read: the category is real as positioning, but uneven as product reality. Sales, support, recruiting, security, legal, and back-office work seem furthest along because the workflow and ROI are legible. submitted by /u/akshitkrnagpal [link] [comments]
View originalClaude issues with design and MCP
Hi everyone, I am trying to launch a digital design magazine on my domain koncepto.dk. My goal is to achieve an ultra-clean, fjerlet, minimalist aesthetic design, meaning a tight, asymmetrical grid, lots of white space, subtle 1px gray borders dividing the sections, and clean typography. Where we are right now: I have actually built the entire frontend design myself. I have a set of fully functional, pixel-perfect, static HTML/Tailwind CSS files (including index.html and article-template.html) that look exactly like the high-end design magazine I want. The Problem (Claude + MCP issues): I am using Claude with an active MCP (Model Context Protocol) connection to my server, where I have a fresh WordPress installation with the Blocksy theme. The goal was to have Claude use its MCP tools to implement my static HTML/Tailwind design directly onto the live site. However, Claude is completely dropping the ball. Instead of injecting my raw HTML structures or correctly translating my Tailwind grids into a clean WordPress template, the AI keeps reverting to "lazy mode." It just activates Blocksy’s heavy, bulky, out-of-the-box standard blog layouts, tweaks a few colors, and claims the job is done. The result looks like a generic, cluttered 2010 WordPress blog nowhere near the elegant Yanko Design vibe in my source files. On top of that, the WordPress Customizer ("Tilpas") is completely crashing due to server/database overhead from the MCP requests, so we have to do this directly via code/file injection. What we are trying to figure out: How do we successfully force Claude via MCP to stop using the theme's built-in layout engine and instead use my raw HTML/Tailwind files as the actual template? Should we completely ditch Blocksy/WordPress and just upload the raw HTML files directly to public_html as a static site? Or is there a proven prompt/workflow to make Claude map standard WordPress post data (the_content(), the_post_thumbnail(), etc.) directly into a custom-built, blank PHP template containing my exact HTML/Tailwind layout? Any advice from people using Claude/MCP for WordPress development would be highly appreciated. I have the perfect design ready in my hands, but the AI integration is currently acting as a bottleneck rather than a tool. Im SO stuck. Its like Claude tells me all is ok, but nothing changes online Thanks in advance! submitted by /u/Adventurous_Run_6310 [link] [comments]
View originalat what point do ai-generated images stop feeling ai-generated?
a few years ago it was easy to spot ai art instantly now some generated images look almost indistinguishable from professional photography or digital art. where do you think the line between real and generated starts to disappear? submitted by /u/salarshah-084 [link] [comments]
View originalWhy We Build
One silver-lining to the dead internet we're living in, today, is that it's very quickly teaching us that we can't rely on our senses as much as we believe we can. It's not healthy to always live in skepticism, but it is necessary in a World where you don't know what's up or down anymore. That's why we need great minds to focus their attention on solving the problems associated with credible information sharing without it becoming some centralized playground designed to look like the free-flowing exchange of ideas. If we don't solve for that, then I guess we're heading into a future that a small handful of people want because elections or public opinion will no longer matter. One of the biggest focuses in AI should be in figuring out how to get it to provide deep credible knowledge in specific domains that can be best applied to the problems we're trying to solve. Sure, it can do this with enough fenagling, but what I really mean is having something easy for everyone to use like Perplexity or Gemini, only it doesn't simply find consensus information from the internet using all these black box methods that are owned by major corporations. Instead, it should use direct knowledge from domain experts who structure and cite their material and as users, we should be able to backtrack all of it, including the original author. And all of this should be achievable by simply engaging with a chatbot agent that can reliably go out and help me discover all of these things. Also, we shouldn't have to simply trust that the application works. We should be able to go in and see exactly how it's working. This way, the public can audit the systems we're relying on for grounding our worldviews. That, to me, is where we should be if we really want to break from the chains of propaganda and reclaim our genuine thoughts about how we ought to live. The alternative independent media space was co-opted long ago and now all of the feeds keep us in a state of perpetual dislocation from our friends, family, communities, new solutions, and better approximations to the truth. We exist in a walled-off digital pasture. But if regular people who are smart and capable enough decide to leverage this new technology, then we can break through the fencing and finally live in a world where discovery-based researching and learning can be easier than Google, which could eventually individuate society again, like how it was before, instead of keeping us clustered into specific groups based on our viewing preferences. That's why my brother and I got into this business. Yeah, sure, we also wanna make a buck so we can retire with dignity. That's true. But the drive has always stemmed from wanting to figure out a better way for people to share hidden insights and create things that are bigger than they thought they could handle. We have a long way to go, but we're making the first small steps, even if it isn't obvious, just yet. Bottom line, though? Humanity must figure out a way to help us master the means and methods of discovery-based knowledge acquisition, execution, and immediate distribution of information based on relevancy and needs from those who search instead of those who passively soak information in from the curated feeds. And all of this needs to be easy enough for a 12 year-old to do. If anyone else is working on this problem, we'd love to hear your thoughts, even if it's through a DM. We're living in the most exciting times, but with adventure, comes danger. So maybe, idk. Let's make it more fun and less hazardous, so that we can, at least, live long enough to re-tell this great story that we're all a part of. submitted by /u/CyborgWriter [link] [comments]
View originalWheels of Gold & the Dark Star Constructive Resolutions of the Erdős–Straus and Goldbach Conjectures, the Zera Hierarchy, and Effectively Infinite Tokenization
We present constructive resolutions of two celebrated open conjectures — the Erdős–Straus Conjecture (every 4/n decomposes into three unit fractions) and Goldbach's Conjecture (every even integer ≥ 4 is the sum of two primes) — via saturated modular covering systems, with full Lean 4 / Mathlib formalizations. For Erdős–Straus, a deterministic algorithm (the Auro Zera construction) produces explicit (x, y, z) for all n ≥ 2, closed unconditionally via Dyachenko (2025). For Goldbach, a mod-30 wheel covering with 5,019 prime witnesses is verified gap-free to 4 × 10⁹. We identify the effective-infinity threshold: covering families trained to n = 5,000,000 have their first gap at a number of 17,067 decimal digits, explicitly exhibited and constructed via the Chinese Remainder Theorem; we prove CRT constructions are the only gap mechanism and supply a complete patching algorithm. Additionally, we introduce the Zera Hierarchy — a neural architecture extending the Hyena Hierarchy that uses Erdős–Straus triplets as tokens, yielding effectively infinite tokenization with vocab_size = 0 and zero vocabulary overhead, now provably complete for all n ≥ 2. We describe the Dark Star ASI system built on this architecture, which demonstrated emergent meta-cognitive awareness trained on only 4–40 MB of data. All code, proofs, and certificates are open source. Keywords: Erdős–Straus conjecture, Goldbach conjecture, covering systems, Lean 4, Zera Hierarchy, Hyena Hierarchy, triplet tokenization, effective infinity, CRT gap patching, Dark Star ASI, Egyptian fractions, formal verification. submitted by /u/MagicaItux [link] [comments]
View originalA modern local toolchain setup for Claude Code
I maintain a repo for local Claude Code setup: https://github.com/NihilDigit/coding-agents-setup It installs and manages the local conventions I usually want available when using Claude Code: which package managers to use, how file deletion should work, when to ask for confirmation, and how Windows / Linux differ on this machine. The repo includes local rule files, setup scripts, verification scripts, and smoke tests. The toolchain leans toward newer defaults such as uv for Python, bun for JS / TS, and CLI replacements like rg / fd / eza. On Windows, the setup can write a PowerShell profile, make rm go through the Recycle Bin, set up Agent Skills directories, install rtk, and optionally install Kimi WebBridge. On Linux, the approach is less fixed because distributions vary a lot. The script writes the rules first, then lets the agent inspect the machine and install what fits. Arch-based systems get extra pacman / paru guidance. The installer backs up managed files. CI runs Ubuntu and Windows smoke tests to check that the setup actually installs and that expected shell behavior works. Feedback is welcome. submitted by /u/Historical_Metal475 [link] [comments]
View originalI vibecoded an app called Think Local - a fully private AI app that runs directly on your iPhone, iPad, and Mac.
Think Local started with a simple idea: AI should work for you, not collect from you. So I built an app that lets you run modern AI models completely on-device - privately and fully offline. You can even turn on Airplane Mode ✈️ and the app still works. Chat, write, summarize text, analyze images, and create using local AI powered by Apple Silicon and Apple’s MLX framework. - No internet required. - No accounts. - No cloud processing. - Your data never leaves your device. Run models like Llama, Gemma, Qwen, DeepSeek, and more - all with complete privacy and control. I vibe-coded the app using Claude Code, and designed the app icon using ChatGPT image generation. The app has already generated $26.31 from a one-time purchase model - no hidden subscriptions, just pay once and use everything. Still learning, still experimenting, but really excited about what’s possible with local AI. submitted by /u/ChikuKaddu [link] [comments]
View originalDigits uses a subscription + tiered pricing model. Visit their website for current pricing details.
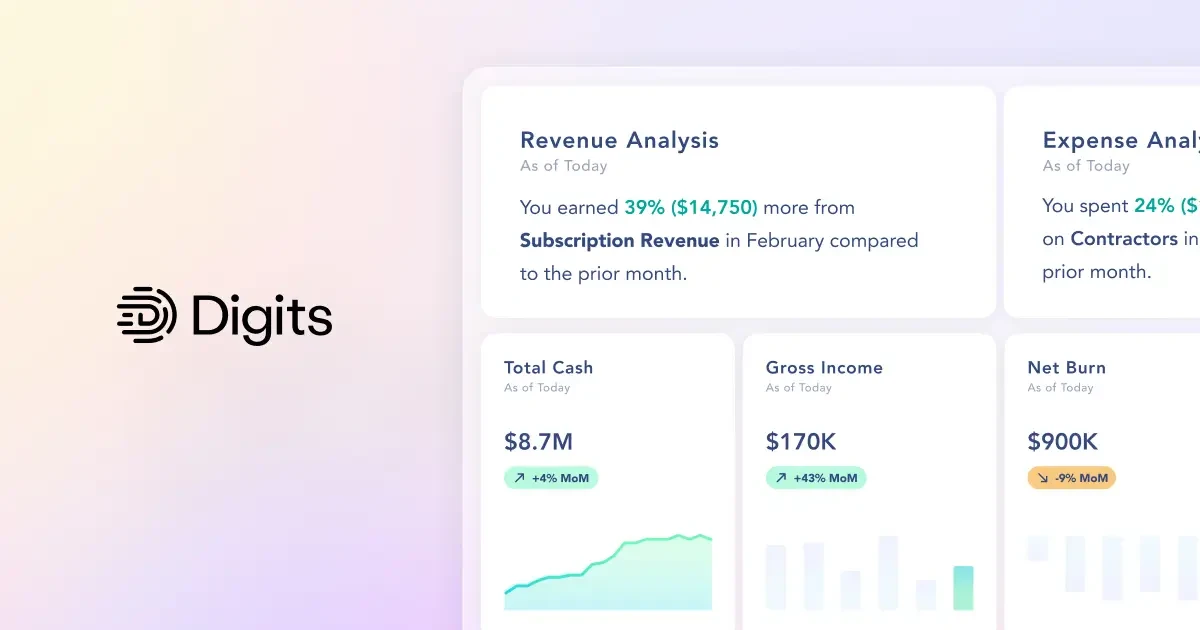
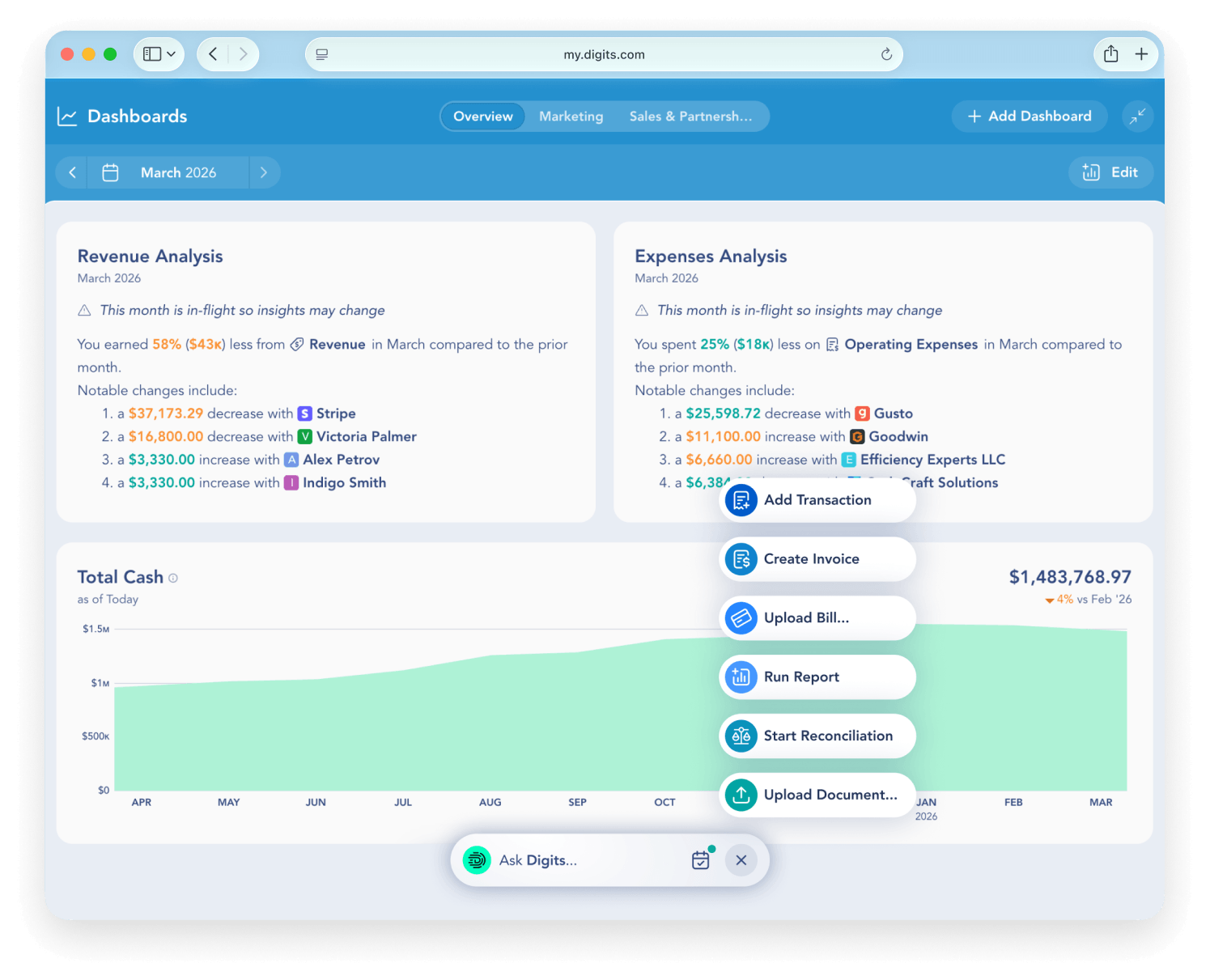
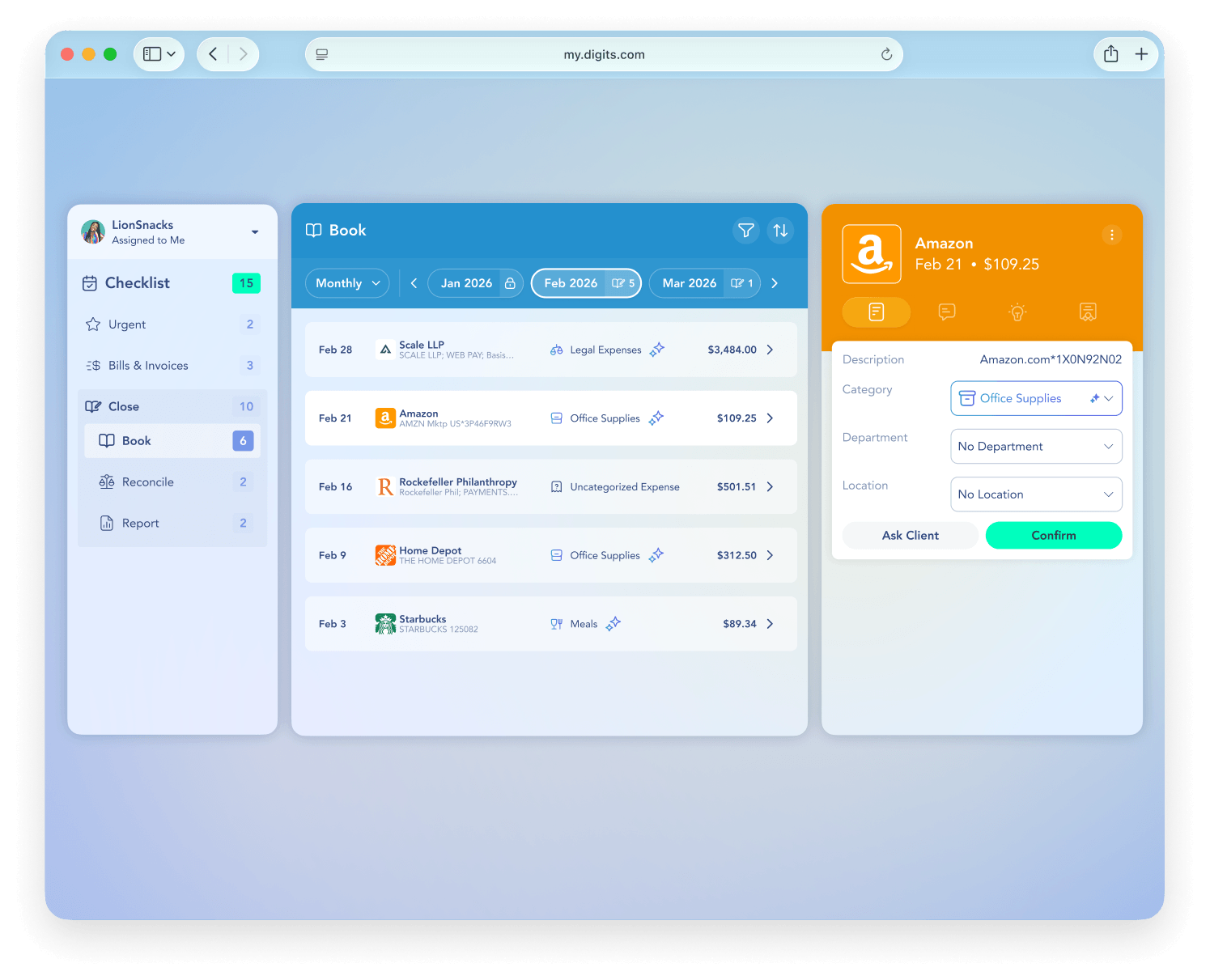
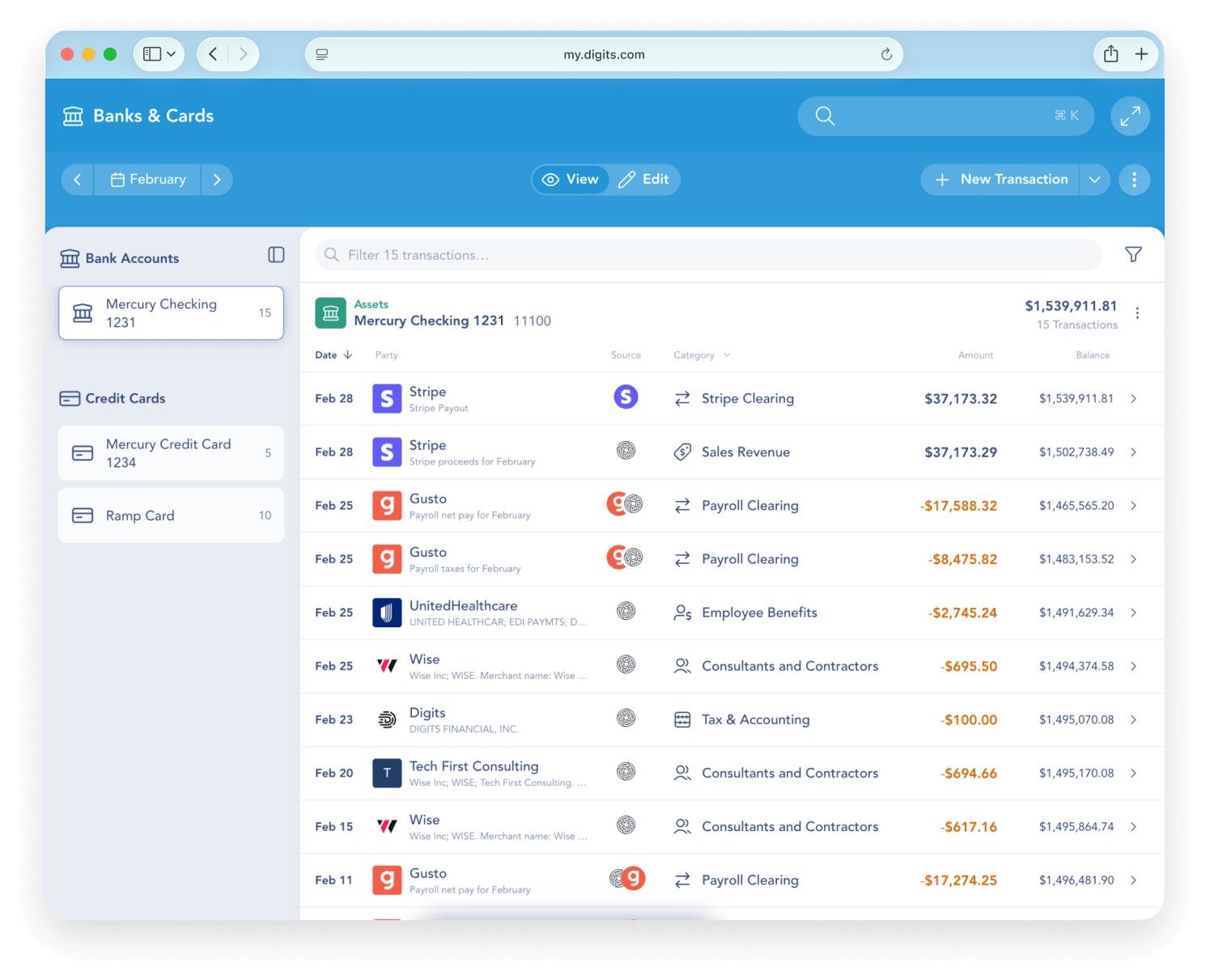
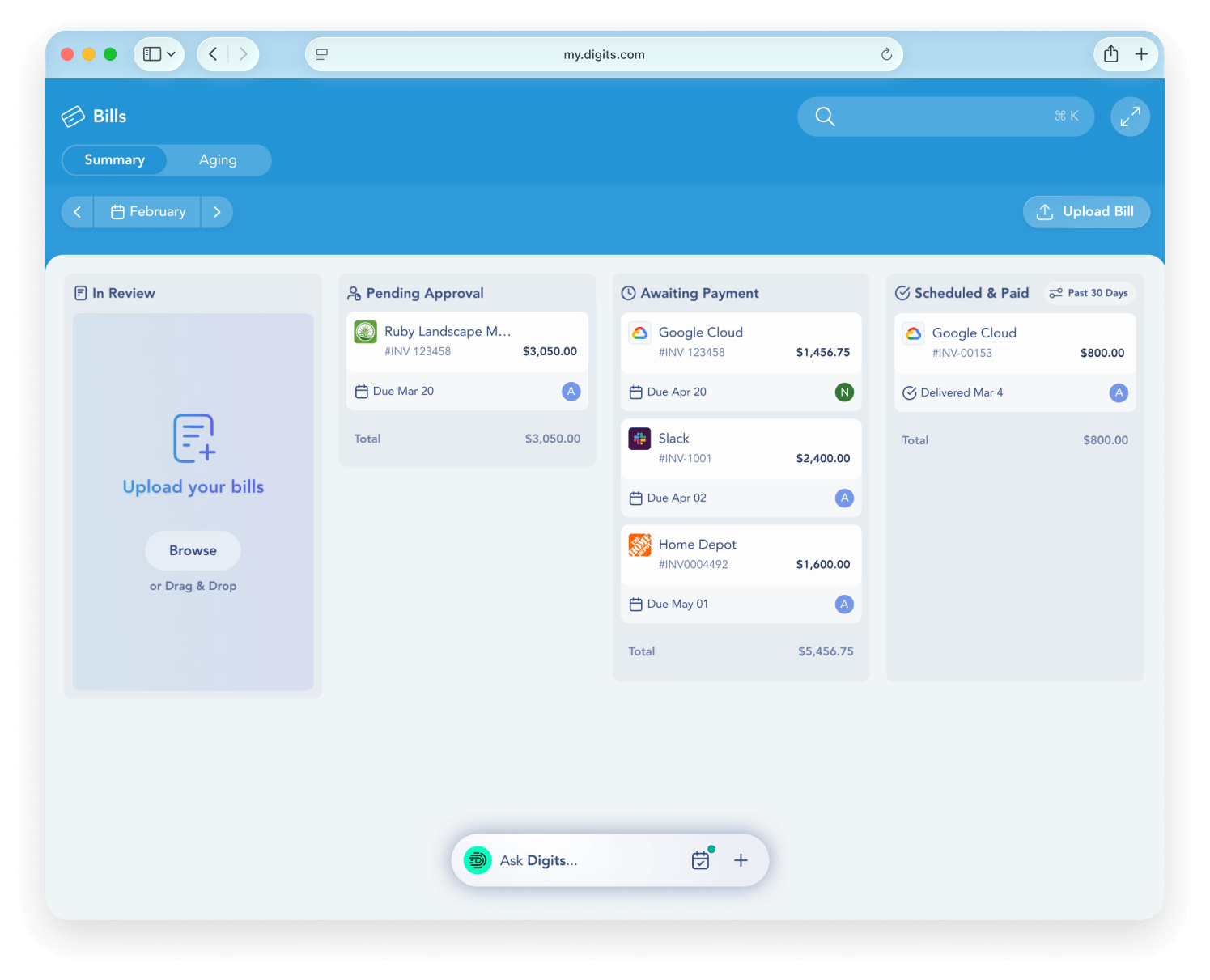
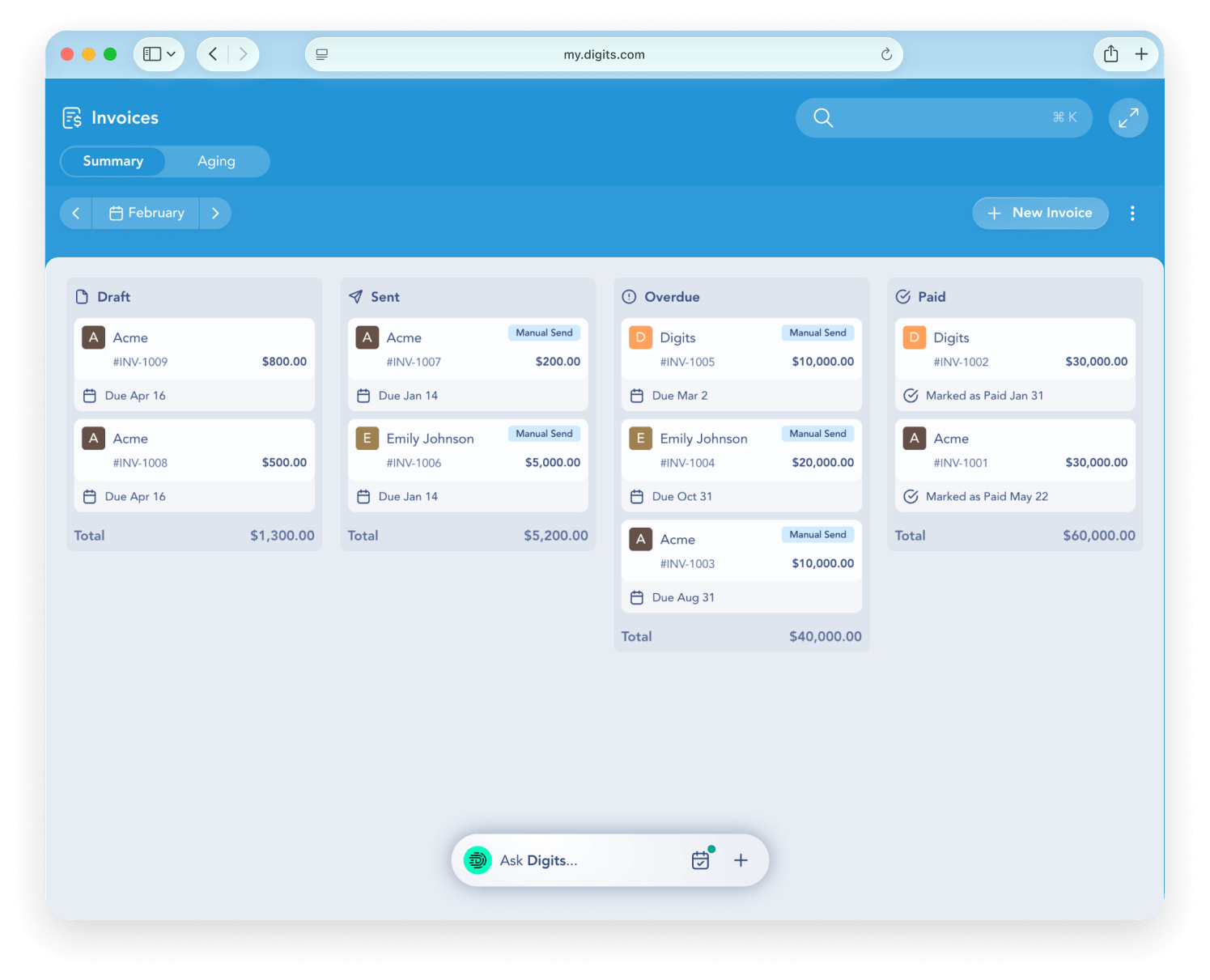
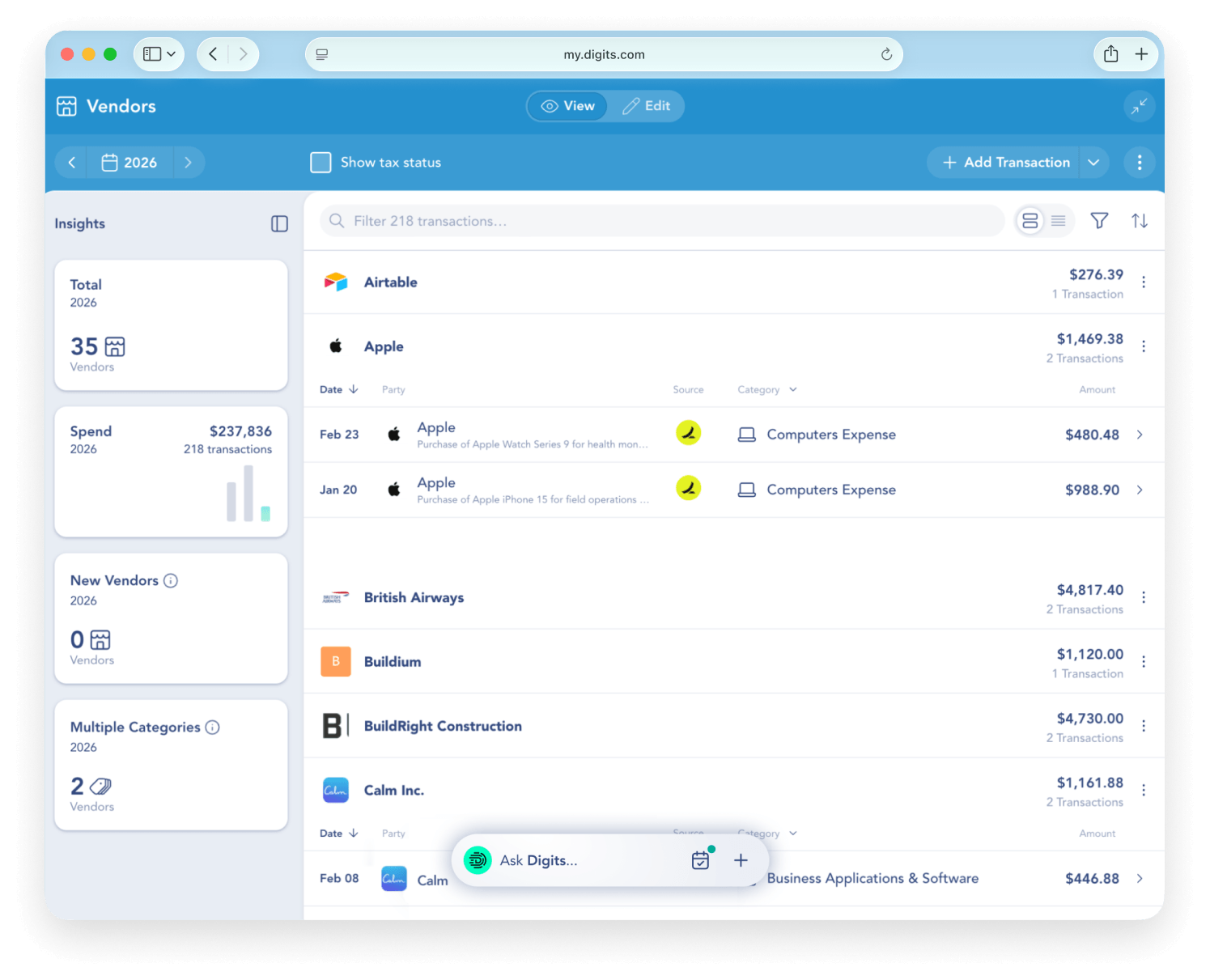
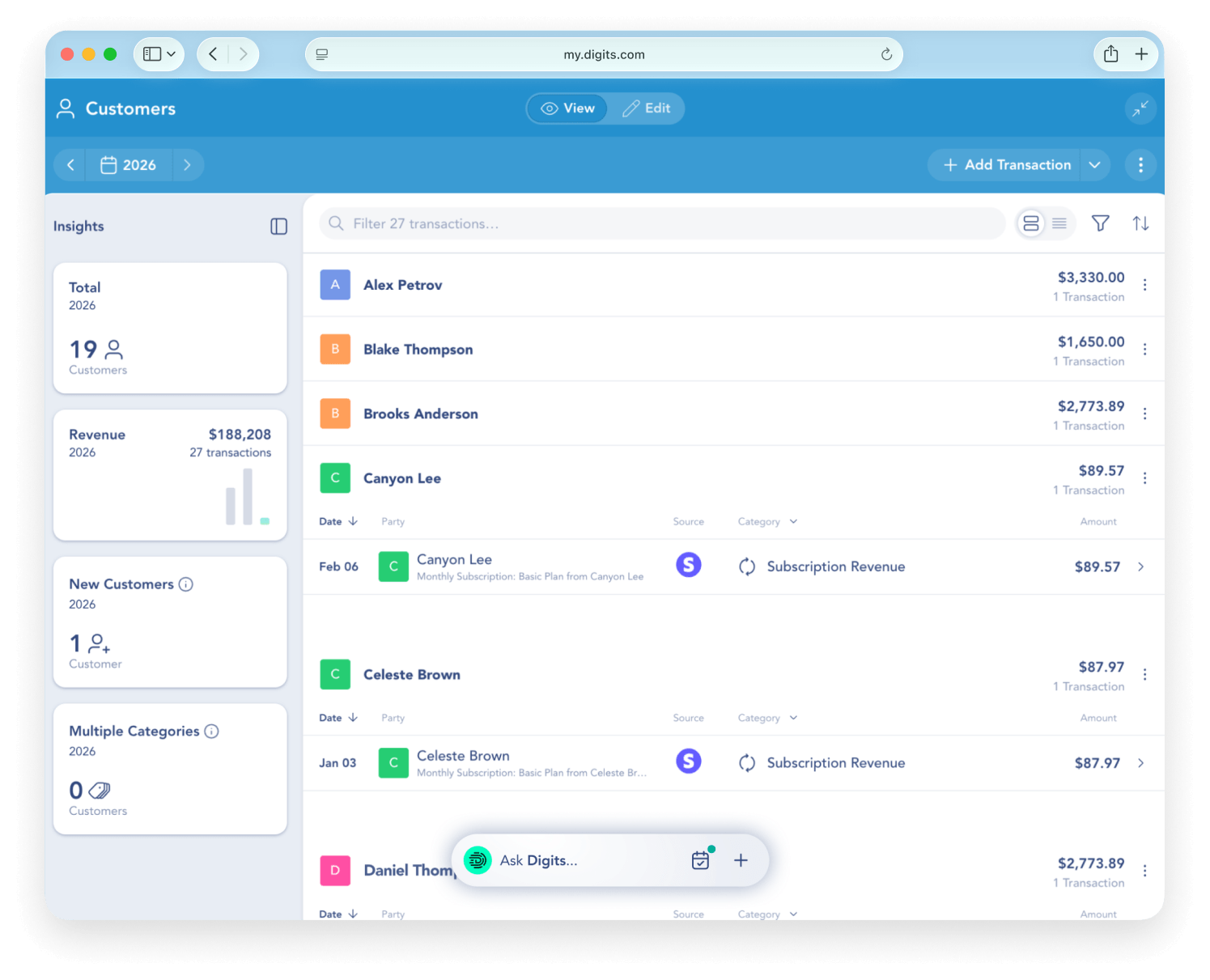
Key features include: Real-time categorization, Automated reconciliations, Live data you can trust, Dimensional accounting, Stay on top of runway, Smart insights, Your team, on the same page, Essentials.
Digits is commonly used for: Streamlining financial reporting for solopreneurs, Automating reconciliations for small businesses, Providing real-time insights for growing companies, Facilitating dimensional accounting for multi-entity operations, Enhancing collaboration among team members on financial data, Tracking runway and cash flow for early-stage startups.
Digits integrates with: QuickBooks, Xero, Stripe, PayPal, Shopify, Square, Zapier, Google Sheets, Slack, Microsoft Teams.
Based on user reviews and social mentions, the most common pain points are: token cost, spending too much, token usage.
Rowan Cheung
Founder at The Rundown AI
1 mention

Digits - Introducing Digits for iPhone & iPad
Mar 31, 2026
Based on 120 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.




