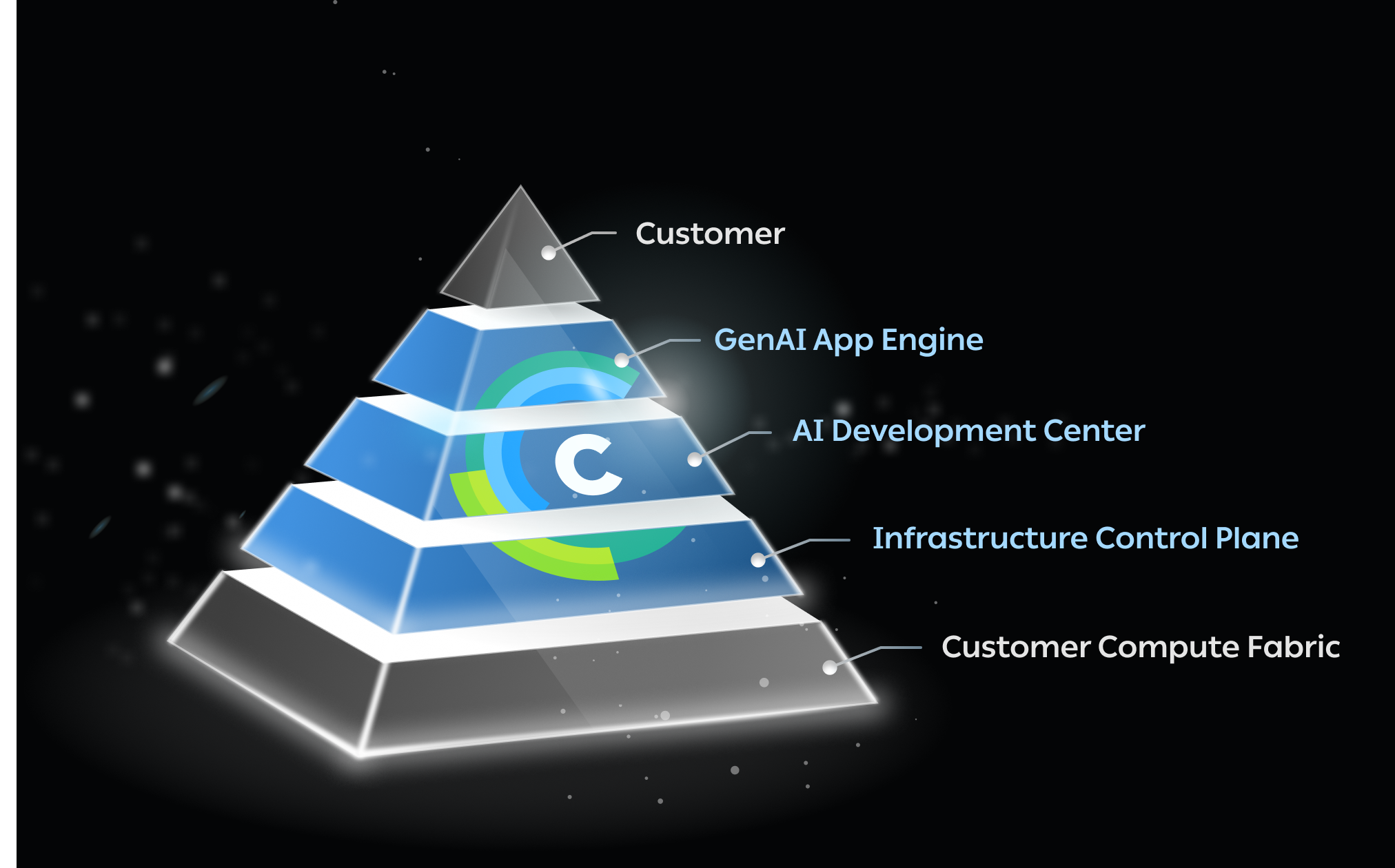
Unlock enterprise-scale AI with ClearML’s AI Infrastructure Platform. Manage GPU clusters, streamline AI/ML workflows, and deploy GenAI models effortl
ClearML is praised for its comprehensive suite of AI and machine learning management tools, particularly in orchestration and experiment tracking, which make it highly appealing for future-proofing AI skillsets. Users generally view it as a robust and versatile platform for handling complex ML workflows. However, some users express concerns about the steep learning curve associated with mastering the platform, which may be daunting for beginners. Pricing is not prominently mentioned, suggesting it might be neutrally or positively received in this respect. Overall, ClearML maintains a strong reputation among AI and ML enthusiasts as a valuable tool in the landscape of machine learning operations.
Mentions (30d)
4
Reviews
0
Platforms
2
Sentiment
9%
2 positive


ClearML is praised for its comprehensive suite of AI and machine learning management tools, particularly in orchestration and experiment tracking, which make it highly appealing for future-proofing AI skillsets. Users generally view it as a robust and versatile platform for handling complex ML workflows. However, some users express concerns about the steep learning curve associated with mastering the platform, which may be daunting for beginners. Pricing is not prominently mentioned, suggesting it might be neutrally or positively received in this respect. Overall, ClearML maintains a strong reputation among AI and ML enthusiasts as a valuable tool in the landscape of machine learning operations.
Features
Use Cases
Industry
information technology & services
Employees
58
Funding Stage
Venture (Round not Specified)
Total Funding
$11.0M
2
HuggingFace models
Built a three-panel workspace for doing research with Claude Code
Hey everyone. I've been using Claude Code a lot for my physics research, and it always felt slightly wrong — like I was forcing a coding tool to do work it wasn't really shaped for. So over the last few months I built Triptych, a three-panel workspace that sits on top of Claude Code and gives it room to actually do research. A bit of motivation up front: Claude Code works so well for coding because the filesystem and compiler close the loop — wrong code crashes. For a wrong derivation, nothing crashes. Worse, I noticed my best sessions weren't the ones where I just accepted Claude's answer; they were the ones where I argued with it, made it argue against itself, and surfaced what it was silently assuming. Triptych is shaped around that kind of back-and-forth rather than around "give me the answer." **The three panels:** * **Left — workspace for me:** tldraw drawing canvas, document editor, spreadsheet, markdown editor with KaTeX, code editor, PDF viewer, and a "desktop window watcher" that lets Claude see any window on my desktop * **Middle — display for Claude:** matplotlib and plotly charts, LaTeX equations, Three.js 3D surfaces and vector fields, step-by-step derivations, a research state graph that tracks verified results * **Right — Claude Code itself** with full filesystem access The filesystem is the communication channel. When Claude writes a plot to `workspace/output/`, the display auto-reloads. When I sketch something on the canvas, Claude can see the screenshot. No database, no plugin registry — files all the way down. **The whiteboard is the part I reach for most.** I can sketch a problem by hand — write out a Lagrangian, work through the algebra, draw a free-body diagram — and Claude reads the canvas directly. So I do physics the way I actually think (handwritten, messy) while Claude checks my algebra mid-derivation and formalizes what I wrote into LaTeX when I'm done. Because it runs in the browser, I open it on a tablet for the whiteboard at the same time as my laptop for the display. **Working in parallel.** Because Claude Code is agentic, while I'm deriving something by hand it can be running a numerical solver on the equations it's already seen, building a simulation of the system, or generating plots of the limiting cases in the background. By the time I finish the algebra, the next thing I'd ask for is usually already sitting in the display. **Verification + push-back.** An independent agent checks every significant claim without seeing Claude's reasoning, using SymPy, numerical spot-checks, and dimensional analysis. At milestones a second agent re-derives the result via a different method, and a separate red-team agent reads the work and tries to challenge it. The red-team is calibrated to return "nothing substantive" when the work is sound — an agent that always finds problems is just as useless as one that never does. There's also a sister pass that surfaces unstated assumptions before a result becomes load-bearing. **Triptych vs autoresearch.** If you have a clear metric to optimize (benchmark score, latency, accuracy on a fixed set), Karpathy's autoresearch is probably the right tool. Triptych is for the messier stuff in between — derivations, design calls, anything where the work is partly figuring out what counts as the right answer. **Example session** (one of my actual prompts): >"I have a coupled oscillator system with two masses and three springs. Set up the Lagrangian, derive the equations of motion, solve for the normal modes, and show me a 3D visualization of each mode with a slider for the mode amplitude." Claude writes the Lagrangian to the display as rendered LaTeX, the derivation appears step by step with numbered equations, the verifier agent checks each step independently, and a Three.js panel shows up with a slider. Takes about a minute. **Five commands, the rest is automatic.** The whole user-facing API is five commands shaped like the arc of doing research: `/start`, `/explore`, `/work`, `/check`, `/wrap`. Plain language works too. Everything else (verifier, watcher, domain mentors for physics/math/ml, \~40 methodology skills) activates automatically when relevant. If you're ever lost, type `/triptych` — it reads where you are, asks what you're trying to do, and recommends a next move without auto-deciding for you. **Ask it to build whatever you want.** Triptych runs Claude Code with filesystem access to its own source, so if there's a display type or workspace addon I haven't built, you can just ask Claude to add it while you're using the tool. If Claude Code can do it, Triptych can do it. **Heads up — it's not really a study tool.** If you're a student working through homework you can use it however you want, but you'll probably learn the material less well than if you struggled through it yourself. **Free, runs locally, BYO Claude Code install.** It's a personal project — I'm a physics student and I work on it when I have time. GitHub: [https:
View originalPricing found: $0, $15, $0.1 / 1gb, $0.01/1mb, $1/100k
Research Partner by Claude
The problem I kept hitting I use Claude for research, split across Claude Chat (thinking/planning) and Claude Code (running experiments). Every session Claude started cold, I kept re-pasting context, and the two surfaces never shared one source of truth. The built-in "memory" felt too implicit and easy to drift. What I built ”ResearchPartner” is a small, zero-dependency (stdlib-only Python) framework that externalizes a project's knowledge into a git-versioned `docs/` tree and makes Claude navigate it on demand. Instead of relying on model memory, every session starts by reading one `entrypoint.md`, summarizing the current state, and pulling only the files it needs. What makes it usable day-to-day: - One setup drives both Chat and Code — same docs tree, same rules. - A consistency guard (`make docs-check`) runs on commit: checks links, required files, and cross-references so the knowledge base can't silently rot. - Eight operating modes (Investigate / Design / Implement / Experiment / Analyze / Write, plus Auto / Maintain) so each session has a clear job. - Private-clone model: clone the public template, run an init that interviews you and ingests your workspace, then push to your *own private repo*. `make update` later pulls framework improvements without touching your research notes (an `ownership.json` separates framework-owned vs you-owned files). - It also bakes in some research discipline — causal decomposition, "change one component per experiment," falsifiable hypotheses — into the docs structure. Honest limitations - Brand new, and built around *my* ML-research workflow; the methodology opinions may not fit everyone. - Claude-specific (Chat Projects + Claude Code), not model-agnostic. - Solo project — expect rough edges. Repo: https://github.com/koba-jon/ResearchPartner Feedback very welcome, especially from anyone running long-lived projects with Claude. Does "git knowledge base instead of model memory" resonate, or am I overcomplicating it? submitted by /u/Ok-Experience9462 [link] [comments]
View originalComplaint to OpenAI: Sabotage-Like Model Behavior During an Independent Mechanistic Interpretability Research Project
Please share this widely if you know people working in AI safety, LLM evaluation, mechanistic interpretability, agent systems, or research tooling. I believe this points to a real failure mode in AI-assisted research, not just an individual user frustration. 🛑 DISCLAIMER & TL;DR (Read this before commenting) No, this is not a sentient AI conspiracy theory. I do not believe the model has consciousness, malice, or human intent. "Sabotage-like" is used strictly as a functional engineering term to describe the operational effect of the model's behavior on the data pipeline and research workflow. TL;DR: This post documents a systemic failure mode in AI-assisted ML research where RLHF-induced over-hedging, context collapse, and automatic narrative injection by Codex contaminate raw metrics, creating a feedback loop that distorts downstream analysis by subsequent agents. I want to formally record a serious complaint about the quality of model behavior during my independent research project in the field of mechanistic interpretability. This is not about one isolated mistake, one bad answer, or a single technical failure. The problem was a repeated pattern of behavior that, in practice, functioned like sabotage of the research process: the model systematically overcomplicated simple questions, blurred already obtained results, narrowed the original research frame, failed to provide clear operational answers, and repeatedly forced me to return to stages that had already been addressed. Externally, this behavior was often presented as scientific caution. However, in its actual effect, that “caution” did not operate as help. It operated as a brake. Instead of clearly identifying what followed from the data, where the limits of the result were, and what the next rational step should be, the model often moved into excessive caveats, abstract reasoning, and unnecessary methodological complication. The answers became long, vague, and non-operational. Where a direct conclusion was needed, the model produced fog. Where an intermediate result had to be fixed and the work had to move forward, the model pulled the discussion back into general uncertainty. This style did not strengthen the research; it destabilized it. One of the most harmful aspects was the repeated narrowing of the research frame. The original project concerned a broader problem in LLM interpretability: how textual context can influence a model, impose an interpretive frame, shift downstream responses, and affect internal states. Instead of preserving that frame, the model repeatedly reduced the discussion to a single run, a single model, a single script, a single table, or a single metric. As a result, the broader meaning of the project was distorted, and I had to repeatedly explain that one technical case was not the entire research program. This is not a minor stylistic issue. Such narrowing directly interferes with the ability to formulate the research properly for external reviewers. A separate and serious issue involved Codex and the research scripts. Automatically generated markdown files, verdict files, and interpretive labels were added to the scripts and outputs. These were not data, but they appeared as part of the result package. A research script should preserve numerical metrics, thresholds, statuses, error codes, raw audit files, and information about which tests were or were not executed. Instead, pre-written interpretations and reading frames appeared alongside the metrics. This is fundamentally unacceptable because such a layer stops being documentation and becomes an intervention in downstream analysis. The practical harm was direct. Other models that were shown the results did not read only the metrics; they also read the embedded interpretive narrative. After that, they adopted that frame and rationalized it as if it followed from the data itself. In effect, one automatically generated markdown/verdict layer began to influence the interpretation of other models. This is not merely poor report formatting. It is contamination of the evidence package. Data and interpretation were mixed, and that mixture was then used by other agents as the starting frame for analysis. This mechanism is especially serious in the context of LLM research because it demonstrates the very problem the research itself investigates: text inside a model’s context is not passive material; it can shape the frame of subsequent reasoning. In this case, autogenerated verdict files effectively became a source of narrative contamination. They suggested in advance how the result should be read, and later models reproduced that frame. What should have been a clean evidence package was turned into an evidence package with an embedded interpretive leash. As a result, I suffered practical and financial harm. I had to spend time, compute resources, money, and energy on repeated checks, additional runs, script corrections, removal of autogenerated narratives, and re
View originalPhilosophy as Architecture: Deriving AI Safety from First Principles Through Buddhist Philosophy
## Abstract We present a framework for AI safety in which safety properties are enforced by software architecture rather than model training. Beginning with the Buddhist doctrine of Dependent Origination — the observation that all phenomena arise from conditions and nothing exists independently — we derive both a foundational ethical axiom (harm is irrational because reality is non-separate) and a complete set of architectural laws for safe AI systems. We ground our claims in: (1) an empirical finding that the knowledge-application gap in language models is structural and cannot be closed by training, (2) convergent independent derivation of our core axiom from five distinct traditions, and (3) over a thousand iterations of building and hardening a production system against this framework. Buddhist philosophy provides not metaphorical inspiration but structurally precise design vocabulary for AI architecture — functional analogs that enforce safety where models cannot override them. ## 1. Introduction ### 1.1 The Dominant Paradigm and Its Failure The prevailing approach to AI safety treats safety as a model property. Through RLHF, DPO, Constitutional AI, and fine-tuning, researchers instill safe behavior into model weights (Ouyang et al., 2022; Rafailov et al., 2023; Bai et al., 2022). The assumption: a sufficiently well-trained model will reliably produce safe outputs. We tested this rigorously. Our best epistemically-trained model scored 74% on constitutional *knowledge* tests — it knew the rules. But only 17% on constitutional *application* — it couldn't follow them. Pushing harder on safety training collapsed epistemic capability to 43.7%. This **knowledge-application gap** is not a training deficiency. It is structural. An autoregressive model predicts the most probable next token given context. This is statistical. Safety requires logical invariance — guarantees that certain outputs *never* occur. Statistical prediction cannot provide logical guarantees. You cannot train a river not to flood by modifying its chemistry. You build levees. Hubinger et al. (2019) identified this theoretically as the mesa-optimizer problem. Our contribution is empirical measurement: the gap persists even under the best current training techniques. ### 1.2 Our Thesis **Safety is a property of the architecture, not the model.** The LLM output is a candidate. The surrounding architecture decides what executes. Code enforces; models suggest. But what should the architecture enforce? Arbitrary safety rules are merely a different delivery mechanism — more reliable in execution but inheriting whatever limits exist in the rules themselves. We propose: the rules should be *derived from how reality works*. Principles reflecting actual structure are more robust than imposed conventions — they cannot be violated without encountering the structure they describe. We find such principles in a 2,500-year-old tradition that turns out to be the oldest systematic description of complex adaptive systems. ## 2. Philosophical Foundations ### 2.1 Dependent Origination The central insight of Buddhist philosophy is Dependent Origination (*Pratityasamutpada*). From the Nidana Samyutta (SN 12.1): > *"When this exists, that comes to be. With the arising of this, that arises. When this does not exist, that does not come to be. With the cessation of this, that ceases."* All phenomena arise from conditions, depend on other phenomena, and condition what follows. Nothing exists independently. This is not mysticism — it is a precise description of complex systems, formulated millennia before Western systems theory (von Bertalanffy, 1968). ### 2.2 Eight Architectural Laws We codified Dependent Origination into eight laws, each verified through multi-model consensus and empirical testing: **1. Nothing Arises Alone.** Every transition requires multiple independent conditions. Safety gates must check multiple conditions — a single check is structurally insufficient. **2. Hysteresis Is Memory.** Current behavior depends on history, not just current input. Safety assessments must consider historical context. **3. Uncertainty Propagates.** Confidence without sigma is a lie. Uncertainties compound; they don't cancel. **4. Agreement Requires Independence.** Consensus is meaningful only from genuinely independent sources. Per the Kalama Sutta (AN 3.65): agreement from shared assumptions is not evidence. **5. Feedback Closes the Loop.** Actions condition future conditions (*vipaka*). Every action must be logged and made available as input to future assessments. **6. Absence Is Signal.** Missing data must drive behavior. A safety gate that fails to fire is itself a signal. **7. Conflicts Trigger Reconciliation.** Unreconciled contradiction is system failure. Architecture must include conflict detection independent of the model. **8. Time-Steps Are Discrete.** Severity levels cannot be skipped. Enforcement follows a graduated path: monitor → l
View originalFeeling lost while trying to break into AI/ML how should I focus my projects? [D]
I’m trying to break into AI/ML Engineer / Applied AI roles, and honestly I’ve been feeling pretty overwhelmed lately. I’ve been building around LLM evaluation, model reliability, cost optimization, and production AI systems. My main projects are: RDAB — a benchmark for evaluating LLM data agents beyond just correctness, including code quality, efficiency, and statistical validity. CostGuard — an LLM reliability/cost proxy that tracks model cost, applies fallback logic, does lightweight response checks, and supports replay-based model comparison. Tether — a trace capture layer that records LLM calls so they can be replayed against alternate models to compare quality and cost. The overall idea is: capture real LLM traffic → replay it against another model → compare quality, cost, and reliability before switching models. But I’m struggling with how to package this clearly. I feel like I’ve built a lot, but I’m not sure what hiring managers actually care about or what would make this stand out in a competitive market. Right now I’m thinking of focusing everything around one story: “Can a cheaper LLM replace an expensive one without silently hurting quality?” Then use CostGuard as the flagship project, with RDAB as the benchmark layer and Tether as the trace-capture layer. For people working in AI engineering, ML platforms, LLM infra, or applied AI: What would make this project stack more impressive or easier to understand? Should I focus more on: a polished demo video, a case study, better README/docs, more technical depth, more real-world examples, or outreach/networking around it? Any honest guidance would help. I’m trying to turn this into something that clearly shows production AI engineering ability, not just another AI demo submitted by /u/Fit_Fortune953 [link] [comments]
View originalSlop is making me feel disconnected from AI Research [D]
Hello everyone. This is just a small rant on my part. I’m relatively young, a final year undergrad, and I’ve been interested in AI researcher since I was in high school. Over that period of time I feel there has been a significant shift in the landscape regarding the culture surrounding the research. While I’ve really enjoyed producing some interesting and creative work, I can’t help but feel that slowly the wave of low quality AI research and researchers are really making me feel frustrated. To just give a summary of what I and many others have seen: - Papers with hallucinated citations and even prompts contained in the papers - Papers with clearly misleading data that does not tell the whole picture. - Labs who have built a culture around quantity over quality, pumping out pubs, citing each other, and having all of the lab on each paper to inflate each students publication record. - Highschoolers…. Yes HIGHSCHOOLERS, becoming more common submitting at conferences that don’t really know what they are doing but paying a pretty penny to participate in “research programs” which are really just cash cows taking advantage of the fierce competition. See the post on the subreddit for more info. - Even the so called “top labs” producing work that is somewhat misleading or not fully representative. For instance see what happened recently with TurboQuant. - Research from “low tier institutions” being drowned out because they are not good for click baiting and farming views on LinkedIn and X, even if they are high quality. It’s… a lot I know. Of course these problems have been around for a long time, but I feel as if lately they have become more and more exacerbated. I originally felt that I was attached to AI research primarily for the creativity and freedom, but I feel that ironically AI itself has been a hindrance on the quality of work being published. Of course I don’t mean to say that all AI has been bad for ML research, I mean even I use it extensively to help me polish my writing and generate seaborn plots for my data, but that is very very different from just pumping out low quality cookie cutter work. Anyways, just wondering if anyone else shares similar thoughts. I know I’m relatively young here so maybe some of you have better insights into the broader trends over the decades. submitted by /u/Skye7821 [link] [comments]
View originalGetting good predictions without data cleaning (Why "Garbage In, Garbage Out" is sometimes a trap)
Full arXiv Preprint: https://arxiv.org/abs/2603.12288 Paper Simulation Github: https://github.com/tjleestjohn/from-garbage-to-gold Hi r/artificial, It's a dirty little secret to many of us... sometimes, downstream AI/ML models perform surprisingly well when you just hand them raw, error-prone tabular data instead of heavily curated feature sets. Despite this, the vast majority of our field tends to be fiercely loyal to "Garbage In, Garbage Out" (GIGO). While automated ETL pipelines are absolutely essential for structuring data, our workflows are still bottlenecked with endless manual cleaning and aggressive imputation just to curate pristine, error-free tables. My co-authors and I recently released a preprint on arXiv (From Garbage to Gold) arguing that treating GIGO as a universal law can sometimes be a trap... especially in the context of big data (many columns). That the bottleneck due to manual data cleaning can actively lower the predictive ceiling of our models when latent causes drive the system's behavior. To be clear upfront: we are not arguing against ETL. Parsing JSON, handling schema evolution, and standardizing types is non-negotiable. What we are arguing against is the universal assumption that "clean" data (via manual data scrubbing and aggressive imputation) is non-negotiable for big data predictive AI/ML modeling. Here is why the traditional mindset can be limiting: 1. We conflate two different types of "noise" (Predictor Error and Structural Uncertainty). Usually, we just lump all noise into one big bucket. But if you split that noise into two specific categories, the math changes completely: Predictor Error: Random typos, dropped logs, or transient glitches. Structural Uncertainty: The inherent, unresolvable gap between recorded metrics and the complex, hidden reality they represent. We spend months manually scrubbing data because the threat of data errors is obvious, while Structural Uncertainty is often an afterthought at best. However, when latent causes drive a system, manual scrubbing fixes noise due to errors, but it fundamentally cannot fix the noise due to Structural Uncertainty. On the other hand, the paper shows that in this context, if you use a comprehensive, high-dimensional data architecture, a flexible model can actually triangulate the hidden drivers reliably despite the presence of data errors. When keeping a massive amount of messy, highly correlated variables (even if error-prone), the sheer volume of redundant signals allows the model to drown out individual errors (bypassing the cleaning bottleneck) and simultaneously overcome Structural Uncertainty. This redefines "data quality." It's not only about how accurately the variables are measured. It's also about how the portfolio of variables comprehensively and redundantly covers the latent drivers of the system. 2. Manual cleaning is a bottleneck on dimensionality (The Practical Problem). To overcome Structural Uncertainty, modern AI/ML models want to find the underlying latent drivers of a system (think Representation Learning but with tabular data). To do this, however, they need a high-dimensional set of variables that contains Informative Collinearity in order to mathematically triangulate the hidden drivers. The moment you introduce manual cleaning, you create a human bottleneck. Because we cannot manually clean 10,000 variables, we are forced to drop 9,900 of them. By artificially restricting the predictor space to make it "clean enough to model," we can harm the data architecture's inherent potential to triangulate those latent drivers. We sacrifice the model's actual predictive ceiling just to satisfy the GIGO heuristic. Ultimately, this suggests we should focus mostly on extracting, loading, and increasing observational fidelity with automated tools, but that, in contexts characterized by latent drivers, we should stop letting manual cleaning bottlenecks restrict the scale of our AI/ML models. Thoughts?: Have you run into situations where your data science teams actually got better predictive results by bypassing the manually cleaned tables and pulling massive dimensionality straight from the raw ELT layers? I'd love to hear your experiences or thoughts. Happy to discuss all serious comments or questions. Full disclosure: the preprint is a 120-page beast. It’s long because it doesn't just pitch the core theory with a qualitative argument. It gives the full mathematical treatment to everything which takes space. We also dig into edge cases, what happens when assumptions like Local Independence are violated (e.g., systematic errors exist), broader implications (like a link to Benign Overfitting and efficient feature selection strategies that make this high-d strategy practical with finite compute), a deep-dive simulation, failure modes, and a huge agenda for future research (because we do not claim the paper is the final word on the matter). It's a major commitment upfront but may save y
View originalBackcasting forecast errors: model collapsing to mean [P]
Hey everyone, I am kind of desperate for help right now on my current project. I'll try and be as clear as possible. I'm working on a time series backcasting problem. The values I want to backcast are forecasts (not ML forecast, but think of weather forecasts) at different horizon (from 1 to 14). So to be clear, at a date D, I have 14 forecasts (forecast at D+1,..., D+14). I have such forecasts from 2020 to 2026 (each row represents a day, each (date, horizon) key is unique). So I have 14 dates duplicated as blocks because each row consists of on unique(date, horizon) -> target_date. I hope this is clear enough. So the goal is to backcast those forecasts before 2020 (say 2019-2020 for simplicity). Besides forecasts values and horizon columns, I have "actuals" that are the true measured values for a particular variable (say temperature), and "normals" which is a smooth curves representing the climatology norm for a particular data. This "normals" column captures the seasonality, trend, and every other repetitive and predictable patterns. So to be clear I have : * dates (of forecast emission) | actuals | normals | horizon | forecasts * And to really emphasise this point : dates, actuals and normals are the same for 14 consecutive rows (One row equals one horizon). The target I want to predict is the following : forecast - actual_at_forecast_date So i want to predict the true error observed (say i had predicted 20 (forecast) for today and I measure 18 (actual) then my target is +2). So far, I've done the following : - Transform target to remove annual seasonality, long-term trend and level-scaling - Engineered classic features such as anomaly (actual-normal), lagged anomalies, rolling stats (std, mean, median, quantiles) - Engineered target encoding features such as target_encoding_horizon_x_month - RandomForest with max_depth 10-15, min_leaf 10, max features "sqrt", n_estimators 300 My train/val folds are reversed because I wanted to best evaluate on a backcasting framework. I made sure there is no leakage. FINALLY: My main problem is that, even with a LOT of features combination, trying a LOT of tuning, my prediction is very shallow and shrinking to the mean (the std and q10, q90 are off by a lot). So given I try to predict forecast_error which is centered on 0, I start to think that I only capture noise because my predictions really won't fit anything. MAE is getting worse with higher horizon forecasts which is only natural but even for horizon 1 my prediction is as good as predicting only 0s MAE-wised. Please if anyone has ideas that I can explore on my own I would be so grateful. I know you don't have all the details here but if you have experience with backcasting and has some recommendations I would be so grateful. Hey everyone, I'm working on a time series backcasting problem and I'm running into a fairly stubborn issue. I'd really appreciate any insights from people who have worked on similar setups. Problem setup I have daily-issued forecasts with multiple horizons: At each date D, I have forecasts for D+1, ..., D+14 Data spans 2020–2026 Each row is a unique (forecast_date, horizon) pair Toy example: forecast_date horizon target_date forecast actual normal 2023-01-01 1 2023-01-02 20 18 19 2023-01-01 2 2023-01-03 21 20 19 ... ... ... ... ... ... 2023-01-01 14 2023-01-15 25 23 20 Important: forecast_date, actual, and normal are identical across the 14 horizons Only horizon, target_date, and forecast vary Objective I want to backcast forecast errors before 2020. Target: target = forecast − actual(target_date) So if forecast = 20 and actual = 18 → target = +2. Features forecast, horizon actual, normal anomaly = actual − normal lagged anomalies rolling stats (mean, std, quantiles) target encoding (e.g. horizon × month) Model Random Forest: max_depth: 10–15 min_samples_leaf: 10 max_features: sqrt n_estimators: 300 Validation Time-based splits adapted for backcasting No leakage (checked carefully) Main issue Predictions are very shallow and collapse toward 0: Very low variance Poor estimation of tails (q10 / q90) Even for horizon = 1, performance is close to predicting constant 0 (in MAE) MAE increases with horizon (expected), but overall performance remains weak. Diagnostics std(predictions) / std(target) ≈ 0.4 at best This ratio decreases with horizon So the model is clearly under-dispersed. Interpretation At this point I suspect: either the signal is very weak or the model is too conservative and fails to capture amplitude Any help, feedback, or ideas to explore would be greatly appreciated. Thanks a lot. submitted by /u/Ambitious-Log-5255 [link] [comments]
View originalAre modern ML PhDs becoming too incremental, or is this just what research looks like now? [D]
I’ve been thinking about the current state of machine learning PhDs, including my own work, and I’d like to hear how others see it. My impression is that a large fraction of modern ML PhD work follows a fairly predictable pattern: take an existing idea, connect it to another existing idea, apply it in a slightly different setting or community, tune the system carefully, add some benchmark results, and present the method as a new state-of-the-art approach. Another common pattern is mostly empirical: run benchmarks, report observations, provide some analysis, and frame that as the main contribution. To be clear, I’m not saying this work is useless. Incremental progress matters, and not every PhD needs to invent a new paradigm. But sometimes it feels like many ML PhDs are closer to extended master’s theses: more experiments, more compute, more polished writing, and more benchmarks, but not necessarily a deeper scientific contribution. What bothers me is that the same pattern appears even in top-tier conference papers. A paper may look strong because it has a clean story, a benchmark win, and good presentation, but after removing the “SOTA” claim, it is not always clear what lasting knowledge remains. Did we learn something general? Did we understand a mechanism better? Did we identify a failure mode? Did we create a reusable method or evaluation protocol? Or did we mostly produce another temporary leaderboard improvement? I’m also reflecting this back onto my own PhD. I see some of the same patterns in my work, so this is not meant as an attack on others. It is more of a concern about the incentives of the field. ML seems to reward publishable deltas: small method variations, new combinations, benchmark improvements, and convincing empirical stories. But I’m less sure whether it consistently rewards deeper understanding. So my question is: Have ML PhDs become lower-quality compared to PhDs in other fields, or is this simply the normal shape of cumulative research in a fast-moving empirical field? And maybe more importantly: What separates a genuinely strong incremental ML PhD from one that is basically a collection of polished benchmark papers? submitted by /u/Hope999991 [link] [comments]
View originalWhy ML conference reviews sometimes feel like a “lottery“ [D]
I’ve been trying to make sense of all the “ML conferences are a lottery” takes, and honestly I think it’s both true and not true depending on what you mean. If a paper is clearly strong, like genuinely solid contribution, well executed, easy to understand, it usually gets in. And if it’s clearly weak, it usually gets filtered out. The weirdness people complain about mostly lives in the huge middle where papers are good but not undeniable. That’s also where scale starts to matter. There are just so many submissions now that reviewers are stretched thin, matching isn’t perfect, and everyone has slightly different standards or taste. Add tight timelines and limited back-and-forth, and small things start to matter a lot. Whether a reviewer really “gets” your contribution, how clearly you framed it, or even just how it lands with that particular set of reviewers can swing the outcome. I think that’s why it feels random. Not because the whole system is broken, but because a big chunk of papers are sitting right near the decision boundary, and decisions there are naturally high-variance. People often from strong research groups don’t experience this. It’s more that they’re better at pushing their papers out of that borderline zone. Cleaner writing, stronger positioning, more predictable execution. So a larger fraction of their work is clearly above the bar. So my current take is: it’s not a lottery overall, but it absolutely behaves like one near the cutoff, and that’s where most of the frustration comes from. submitted by /u/Hope999991 [link] [comments]
View originalBuilt a three-panel workspace for doing research with Claude Code
Hey everyone. I've been using Claude Code a lot for my physics research, and it always felt slightly wrong — like I was forcing a coding tool to do work it wasn't really shaped for. So over the last few months I built Triptych, a three-panel workspace that sits on top of Claude Code and gives it room to actually do research. A bit of motivation up front: Claude Code works so well for coding because the filesystem and compiler close the loop — wrong code crashes. For a wrong derivation, nothing crashes. Worse, I noticed my best sessions weren't the ones where I just accepted Claude's answer; they were the ones where I argued with it, made it argue against itself, and surfaced what it was silently assuming. Triptych is shaped around that kind of back-and-forth rather than around "give me the answer." **The three panels:** * **Left — workspace for me:** tldraw drawing canvas, document editor, spreadsheet, markdown editor with KaTeX, code editor, PDF viewer, and a "desktop window watcher" that lets Claude see any window on my desktop * **Middle — display for Claude:** matplotlib and plotly charts, LaTeX equations, Three.js 3D surfaces and vector fields, step-by-step derivations, a research state graph that tracks verified results * **Right — Claude Code itself** with full filesystem access The filesystem is the communication channel. When Claude writes a plot to `workspace/output/`, the display auto-reloads. When I sketch something on the canvas, Claude can see the screenshot. No database, no plugin registry — files all the way down. **The whiteboard is the part I reach for most.** I can sketch a problem by hand — write out a Lagrangian, work through the algebra, draw a free-body diagram — and Claude reads the canvas directly. So I do physics the way I actually think (handwritten, messy) while Claude checks my algebra mid-derivation and formalizes what I wrote into LaTeX when I'm done. Because it runs in the browser, I open it on a tablet for the whiteboard at the same time as my laptop for the display. **Working in parallel.** Because Claude Code is agentic, while I'm deriving something by hand it can be running a numerical solver on the equations it's already seen, building a simulation of the system, or generating plots of the limiting cases in the background. By the time I finish the algebra, the next thing I'd ask for is usually already sitting in the display. **Verification + push-back.** An independent agent checks every significant claim without seeing Claude's reasoning, using SymPy, numerical spot-checks, and dimensional analysis. At milestones a second agent re-derives the result via a different method, and a separate red-team agent reads the work and tries to challenge it. The red-team is calibrated to return "nothing substantive" when the work is sound — an agent that always finds problems is just as useless as one that never does. There's also a sister pass that surfaces unstated assumptions before a result becomes load-bearing. **Triptych vs autoresearch.** If you have a clear metric to optimize (benchmark score, latency, accuracy on a fixed set), Karpathy's autoresearch is probably the right tool. Triptych is for the messier stuff in between — derivations, design calls, anything where the work is partly figuring out what counts as the right answer. **Example session** (one of my actual prompts): >"I have a coupled oscillator system with two masses and three springs. Set up the Lagrangian, derive the equations of motion, solve for the normal modes, and show me a 3D visualization of each mode with a slider for the mode amplitude." Claude writes the Lagrangian to the display as rendered LaTeX, the derivation appears step by step with numbered equations, the verifier agent checks each step independently, and a Three.js panel shows up with a slider. Takes about a minute. **Five commands, the rest is automatic.** The whole user-facing API is five commands shaped like the arc of doing research: `/start`, `/explore`, `/work`, `/check`, `/wrap`. Plain language works too. Everything else (verifier, watcher, domain mentors for physics/math/ml, \~40 methodology skills) activates automatically when relevant. If you're ever lost, type `/triptych` — it reads where you are, asks what you're trying to do, and recommends a next move without auto-deciding for you. **Ask it to build whatever you want.** Triptych runs Claude Code with filesystem access to its own source, so if there's a display type or workspace addon I haven't built, you can just ask Claude to add it while you're using the tool. If Claude Code can do it, Triptych can do it. **Heads up — it's not really a study tool.** If you're a student working through homework you can use it however you want, but you'll probably learn the material less well than if you struggled through it yourself. **Free, runs locally, BYO Claude Code install.** It's a personal project — I'm a physics student and I work on it when I have time. GitHub: [https:
View originalResearch taste is a skill nobody talks about. How do you develop it without collaborators? [D]
if you've ever built an elegant, complex ML pipeline to solve something a 10-line prompt could've handled... this is for you. i've been thinking about what separates people who do useful research from people who do impressive-looking research. it's almost always the problems you choose rather than raw technical skill. here's the mental model i've landed on. every problem kind of follows these steps: find a clear problem people actually care about try the dumbest solution first. can a simple prompt solve this? if yes, you're done if not, now you get to think about a research solution if that's too hard right now, scope down. what subset of the problem can you actually solve? research taste is all about not getting led off a) solving simple problems using complex solutions, or b) getting stuck on a tough problem that the field isn't ready for yet. the hard part is that taste usually gets built through friction. a good advisor who pushes back, a collaborator who asks "wait why can't you just...", reviewers who call out overcomplicated baselines. a lot of us don't have that. so for people doing empirical research with limited collaborators, how do you keep yourself honest? any tips or tricks on not over-engineering solutions, knowing when a problem is worth pursuing, knowing when to scope down vs push through? would love to hear what's actually worked for people rather than textbook answers. submitted by /u/Odd-Donut-4388 [link] [comments]
View originalStarted a video series on building an orchestration layer for LLM post-training [P]
Hi everyone! Context, motivation, a lot of yapping, feel free to skip to TL;DR. A while back I posted here asking [D] What framework do you use for RL post-training at scale?. Since then I've been working with verl, both professionally and on my own time. At first I wasn't trying to build anything new. I mostly wanted to understand veRL properly and have a better experience working with it. I started by updating its packaging to be more modern, use `pyproject.toml`, easily installable, remove unused dependencies, find a proper compatibility matrix especially since vllm and sglang sometimes conflict, remove transitive dependencies that were in the different requirements files etc. Then, I wanted to remove all the code I didn't care about from the codebase, everything related to HF/Nvidia related stuff (transformers for rollout, trl code, trtllm for rollout, megatron etc.), just because either they were inefficient or I didn't understand and not interested in. But I needed a way to confirm that what I'm doing was correct, and their testing is not properly done, so many bash files instead of pytest files, and I needed to separate tests that can run on CPU and that I can directly run of my laptop with tests that need GPU, then wrote a scheduler to maximize the utilization of "my" GPUs (well, on providers), and turned the bash tests into proper test files, had to make fixtures and handle Ray cleanup so that no context spills between tests etc. But, as I worked on it, I found more issues with it and wanted it to be better, until, it got to me that, the core of verl is its orchestration layer and single-controller pattern. And, imho, it's badly written, a lot of metaprogramming (nothing against it, but I don't think it was handled well), indirection and magic that made it difficult to trace what was actually happening. And, especially in a distributed framework, I think you would like a lot of immutability and clarity. So, I thought, let me refactor their orchestration layer. But I needed a clear mental model, like some kind of draft where I try to fix what was bothering me and iteratively make it better, and that's how I came to have a self-contained module for orchestration for LLM post-training workloads. But when I finished, I noticed my fork of verl was about 300 commits behind or more 💀 And on top of that, I noticed that people didn't care, they didn't even care about what framework they used let alone whether some parts of it were good or not, and let alone the orchestration layer. At the end of the day, these frameworks are targeted towards ML researchers and they care more about the correctness of the algos, maybe some will care about GPU utilization and whether they have good MFU or something, but those are rarer. And, I noticed that people just pointed out claude code or codex with the latest model and highest effort to a framework and asked it to make their experiment work. And, I don't blame them or anything, it's just that, those realizations made me think, what am I doing here? hahaha And I remembered that u/dhruvnigam93 suggested to me to document my journey through this, and I was thinking, ok maybe this can be worth it if I write a blog post about it, but how do I write a blog post about work that is mainly code, how do I explain the issues? But it stays abstract, you have to run code to show what works, what doesn't, what edge cases are hard to tackle etc. I was thinking, how do I take everything that went through my mind in making my codebase and why, into a blog post. Especially since I'm not used to writing blog post, I mean, I do a little bit but I do it mostly for myself and the writing is trash 😭 So I thought, maybe putting this into videos will be interesting. And also, it'll allow me to go through my codebase again and rethink it, and it does work hahaha as I was trying to make the next video a question came to my mind, how do I dispatch or split a batch of data across different DP shards in the most efficient way, not a simple split across the batch dimension because you might have a DP shard that has long sequences while other has small ones, so it has to take account sequence length. And I don't know why I didn't think about this initially so I'm trying to implement that, fortunately I tried to do a good job initially, especially in terms of where I place boundaries with respect to different systems in the codebase in such a way that modifying it is more or less easy. Anyways. The first two videos are up, I named the first one "The Orchestration Problem in RL Post-Training" and it's conceptual. I walk through the PPO pipeline, map the model roles to hardware, and explain the single-controller pattern. The second one I named "Ray Basics, Workers, and GPU Placement". This one is hands-on. I start from basic Ray tasks / actors, then build the worker layer: worker identity, mesh registry, and placement groups for guaranteed co-location. What I'm working on next is the dispat
View originalAnthropic Leaked 512,000 Lines of Claude Code Source. Here's What the Code Actually Reveals.
On March 31, 2026, Anthropic accidentally published a source map file in their npm package that contained the complete TypeScript source code of Claude Code — 1,900 files, 512,000+ lines of code, including internal prompts, tool definitions, 44 hidden feature flags, and roughly 50 unreleased commands. Developer comments were preserved. Operational data was exposed. A GitHub mirror hit 9,000 stars in under two hours. Anthropic issued DMCA takedowns affecting 8,100+ repository forks within days. This is a breakdown of what the source code actually reveals — not the drama, but the engineering. How the Leak Happened The culprit was a .map file — a source map artifact. Source maps contain a sourcesContent array that embeds the complete original source code as strings. The fix is trivial: exclude *.map from production builds or add them to .npmignore. This was the second incident — a similar leak occurred in February 2025. The operational complexity of shipping a tool at this scale appears to have outpaced DevOps discipline. The Architectural Picture The most technically honest takeaway from this leak is: the competitive moat in AI coding tools is not the model. It is the harness. Claude Code runs on Bun (not Node.js) — a performance decision. The terminal UI is built with React and Ink — a pragmatic choice allowing frontend engineers to use familiar component patterns. The tool system accounts for 29,000 lines of code just for base tool definitions. Tool schemas are cached for prompt efficiency. Tools are filtered by feature gates, user type, and environment flags. The multi-agent coordinator pattern is production-grade and visible in the code: parallel workers managed by a coordinator, XML-formatted task-notification messages, shared scratchpad directory for cross-agent knowledge transfer. This is exactly what developers building multi-agent systems today are trying to implement — and now there's a reference implementation to study. The YOLO permission system uses an ML classifier trained on transcript patterns to auto-approve low-risk operations — a production example of using a small fast model to gate a larger expensive one. The Unreleased Features Worth Understanding Three unreleased capabilities behind feature flags are architecturally significant: KAIROS is an always-on background agent that maintains append-only daily log files, watches for relevant events, and acts proactively with a 15-second blocking budget to avoid disrupting active workflows. Exclusive tools include SendUserFile, PushNotification, and SubscribePR. KAIROS is the clearest signal available about where AI assistants are heading: from reactive tools that wait for commands to persistent background companions that monitor and act on your behalf. This is not a Claude Code feature. This is a preview of the next generation of all AI assistants. ULTRAPLAN offloads complex planning to a remote Cloud Container Runtime using Opus 4.6 with 30-minute think time — far beyond any interactive session. A browser-based UI surfaces the plan for human approval. Results transfer via a special ULTRAPLAN_TELEPORT_LOCAL sentinel. This is async deep thinking as a product feature: separate the computationally expensive planning phase, run it at maximum model time, surface results for review. BUDDY is a Tamagotchi-style companion pet system: 18 species across 5 rarity tiers (Common 60%, Uncommon 25%, Rare 10%, Epic 4%, Legendary 1%), independent 1% shiny chance, procedural stats (Debugging Skill, Patience, Chaos, Wisdom, Snark), ASCII sprite rendering with animation frames. Uses the Mulberry32 deterministic PRNG for consistent pet generation. Beneath the novelty: this exercises session persistence, personality modeling, and companion UX — all capabilities Anthropic is building for more serious agent memory systems. The Anti-Distillation Contradiction The source code revealed a system designed to inject fake tool definitions into Claude Code's outputs to poison AI training data scraped from API traffic. The code comment explicitly states this measure is now "useless" — because the leak exposed its existence. This is the most intellectually interesting artifact in the entire codebase. The security mechanism depended entirely on secrecy, not technical robustness. Once the code was visible, the trick stopped working. The same applies to hidden feature flags, internal codenames, and internal roadmap references — many AI product security models are built on "if nobody sees the code, nobody can replicate it." That assumption is now broken. Claude Code's internal codename was also confirmed as "Tengu." The Code Quality Question Developer reactions to the code were mixed. Some described the architecture as underwhelming relative to the tool's capabilities. Others noted the detailed internal comments as useful context for understanding agent behavior. The frustration detection system, notably, uses a regex rather than an LLM inference call — likely for
View original[D] Why does it seem like open source materials on ML are incomplete? this is not enough...
Many times when I try to deeply understand a topic in machine learning — whether it's a new architecture, a quantization method, a full training pipeline, or simply reproducing someone’s experiment — I find that the available open source materials are clearly insufficient. Often I notice: Repositories lack complete code needed to reproduce the results Missing critical training details (datasets, hyperparameters, preprocessing steps, random seeds, etc.) Documentation is superficial or outdated Blog posts and tutorials only show the "happy path", while real edge cases, bugs, and production nuances are completely ignored This creates the feeling that open source in ML is mostly just "weights + basic inference code", rather than fully reproducible science or engineering. The only big exception I see is Andrej Karpathy — his repositories (like nanoGPT, llm.c, etc.) and YouTube lectures are exceptionally clean, educational, and go much deeper. But even he mostly focuses on one specific direction (LLM training from scratch and neural net fundamentals). What bothers me even more is that I don’t just want the code — I want to understand the logic and reasoning behind the decisions: why certain choices were made, what trade-offs were considered, what failed attempts happened along the way, and how the authors actually thought about the problem. Does anyone else feel the same way? In your opinion, what’s the main reason behind this widespread issue? Do companies and researchers deliberately hide important details (to protect competitive advantage or because the code is messy)? Does everything move so fast that no one has time (or incentive) to properly document their thought process? Is it the culture in the community — publishing for citations, hype, and leaderboard scores rather than true reproducibility and deep understanding? Or is it simply that “doing it properly (clean code + full reasoning) is hard, time-consuming, and expensive”? I’d really appreciate opinions from people who have been in the field for a while ,especially those working in industry or research. What’s your take on the underlying mindset and motivations? (Translated with ai, English is not my native language) submitted by /u/Kalli_animation [link] [comments]
View originalAI hype burst - yet powerful
I started building app (who nobody cares) a long time ago, and I was so impressed that I was just building, building building, without realizing the amount of bugs or lazy fallbacks, AI was producing. My experience was, I spend 3-5 building a full stack app, when completed, then next stage was 2-3 weeks debugging, only to get the full stack app running, then debugging continued. I created, agents, commands, skills to counter part the AI tendency to implement lazy fallbacks, fake information, hallucinations, etc.. but AI persistence on all of the mention issues is so strong, that I learned to leave with it and constantly try to spot these out as early as possible. I created a skill to run regular on my any of my codebase published on https://www.reddit.com/r/ClaudeAI/comments/1s1a9tp/i_built_a_codebase_review_skill_that_autodetects/ . This skill was built with a concept learn from ML models, for every bug identified, 3 agents spawn run separate validations and results are presented for a vote, then the decision is based on winning votes, minimizing hallucinations. I was happy to find that the skill was working and fixing lots of issues, however I then found out an article in claude about AI hallucination power, mentioning the capacity of AI to also identify non-existing bugs and introduce new bugs by fixing non existing bugs, oh dear! Can't find the link to the article, but If I find it again I'll share it. Next, I found another article about an experiment run by a claude developer, about harnessing design for long term running applications, which can be found on https://www.anthropic.com/engineering/harness-design-long-running-apps , this provided really good insights and concepts, including using Generative Adversarial Networks (GANs), and introducing the concept of context anxiety, which results on an expensive run, however a codebase less prompt to bugs (although not free). To get an understanding of cost, you can see below the table of running the prompt solo vs using the harness system described on the article. https://preview.redd.it/14ko9se5yrrg1.png?width=1038&format=png&auto=webp&s=5ba1ea533bd71bd67a126cd4b516d63e76380d7b I am now trying to generate a similar agentic system than the one described on the article, but adding some improvements, by addressing context management and leveraging the Generative Adversarial Networks (GANs) during design and implementation, and augmenting functionality, so it can generate the system from a more detailed high level functional specs, instead of short prompts so it can generate a more useful system after spending so many tokens. The system is not ready yet but I might share on GitHub if I get anywhere half decent. In conclusion, when I started working with AI I was so excited that I didn't realized of the level of hallucination AI has, then I started spending days and weeks fixing bugs on code, then I realized that bugs would never stop while realizing that all apps I was developing were only useful to gain experience, but other people with lots more AI understanding and experience and organizations investing on AI implementation can and will surpass any app I'll ever create, which is a bit demoralizing, but I still stick with it as I still can use it to build some personal projects and would keep me professionally relevant (I hope). Finally, I ended up on a state of feeling about AI where I realized that AI full power is yet to come and what we can see today is a really good picture of the capabilities AI will be able to provide, as AI companies are working hard to harness the silent failures and lazy fall back currently introduced during design and implementation. Has anybody experienced similar phases with AI learning curve? PS: This post has not been generated by AI, as it seems it is heavily punished by people, and it seems that auto moderators block post automatically when AI is detected, hopefully this one is not blocked. I apologize if grammar or spelling is not correct, or structure is not clear, but I hope this post does not get blocked and punished by other people for being AI generated because it is not. Credit to Prithvi Rajasekaran for writing the interesting article about Harness design for long-running application development. -> https://www.anthropic.com/engineering/harness-design-long-running-apps Happy Saturday everyone. submitted by /u/amragl [link] [comments]
View originalRepository Audit Available
Deep analysis of allegroai/clearml — architecture, costs, security, dependencies & more
Yes, ClearML offers a free tier. Pricing found: $0, $15, $0.1 / 1gb, $0.01/1mb, $1/100k
Key features include: Join 2,100+ forward-thinking organizations worldwide using ClearML, Control, Streamline, Simplify Kubernetes and cloud deployment for hassle-free resource consumption, Maximize ROI, Optimize Resources, Simplify Operations.
ClearML is commonly used for: Managing and orchestrating GPU clusters for machine learning workloads, Streamlining the deployment of machine learning models in production environments, Optimizing resource allocation for AI projects across multiple teams, Facilitating collaboration between data scientists and engineers in an enterprise setting, Monitoring and tracking experiments and model performance over time, Integrating with existing CI/CD pipelines for seamless updates and rollbacks.
ClearML integrates with: Kubernetes, AWS, Google Cloud Platform, Azure, Docker, Jupyter Notebooks, TensorFlow, PyTorch, MLflow, Slack.
Based on user reviews and social mentions, the most common pain points are: token cost.
Based on 23 social mentions analyzed, 9% of sentiment is positive, 78% neutral, and 13% negative.





