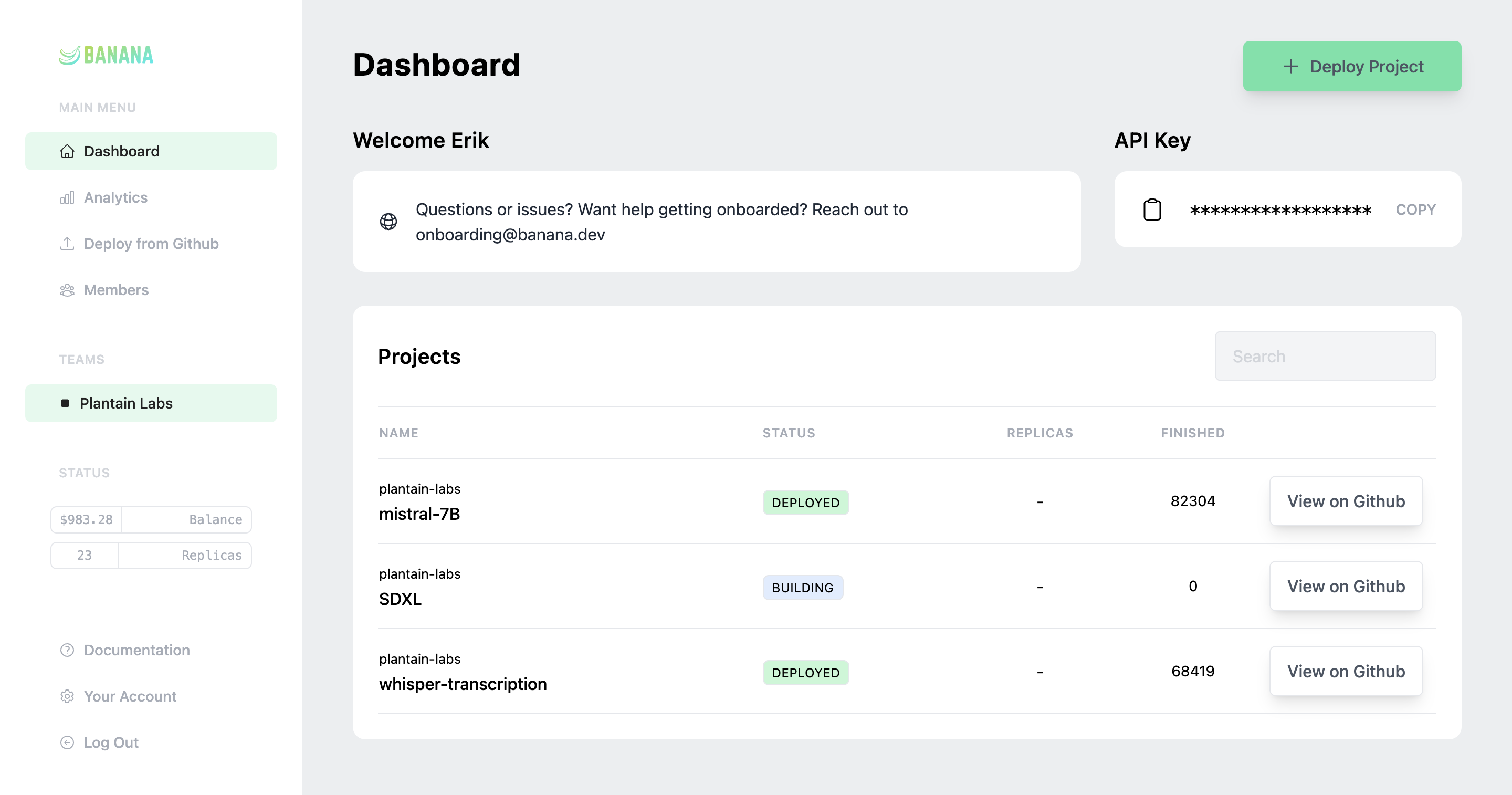
Inference hosting for AI teams who ship fast and scale faster.
Users generally view "Banana" as a competent tool, particularly favoring its graphic design and text capabilities over some newer alternatives. However, there are complaints about a lack of official communication regarding updates and API releases, which has led to user frustration. Price sentiment is largely undiscussed, pointing to potential satisfaction or indifference towards its cost. Overall, "Banana" maintains a solid reputation, with a dedicated user base appreciating its functionality despite some communication and rollout issues.
Mentions (30d)
3
Reviews
0
Platforms
2
Sentiment
0%
0 positive



Users generally view "Banana" as a competent tool, particularly favoring its graphic design and text capabilities over some newer alternatives. However, there are complaints about a lack of official communication regarding updates and API releases, which has led to user frustration. Price sentiment is largely undiscussed, pointing to potential satisfaction or indifference towards its cost. Overall, "Banana" maintains a solid reputation, with a dedicated user base appreciating its functionality despite some communication and rollout issues.
Features
Use Cases
Industry
information technology & services
Employees
170
Funding Stage
Seed
Total Funding
$5.2M
Just passed the new Claude Certified Architect - Foundations (CCA-F) exam with a 985/1000!
The original post was removed by Reddit Filters, so I made new one with same content. I just got my results back today and managed to snag the Early Adopter badge as well. Following up on my recent DP-600 certification, I really wanted to validate my architecture skills specifically on the Anthropic side. The exam covers a lot of practical ground on prompt engineering for tool use, managing context windows efficiently, and handling Human-in-the-Loop workflows. Link to join: https://anthropic.skilljar.com/claude-certified-architect-foundations-access-request Training courses: https://anthropic.skilljar.com/ Cookbook: https://github.com/anthropics/anthropic-cookbook I've created my own Playbook and Mock Exam after the exam: https://drive.google.com/file/d/1luC0rnrET4tDYtS7xe5jUxMDZA-4qNf-/view?usp=sharing https://claude-certified-architect-mock-exam-cyberskill.vercel.app If anyone is preparing for this right now and has questions about the format or the types of architectural patterns tested, ask away! Happy to share some insights on what to study. Updated 26th May 2026: I noticed some mates treated me bananas (https://buymeacoffee.com/zintaen), didn't expect that, but you made my day. I'll use that fund to take more CERTs and create a site for mock tests (always free, of course). Thanks again.
View originalPricing found: $1200 /mo, $20
Gemini core part 4
https://preview.redd.it/pv22tsg2ib4h1.png?width=1918&format=png&auto=webp&s=dfeda1000090dc99c57c8150e4de46cfe2ba2e29 I just wanted him to give me a prompt, which then i can give to Nano Banana pro and generate me a completely random thumbnail, i wanted to test its capabilities, but instead of a prompt, he gave me this... 😭😭😭😭😭 submitted by /u/ObjectiveOrchid5344 [link] [comments]
View originalBuilt an MCP server so Claude can generate music, images, and video natively. One config block.
I've been using Claude Code daily for the last few months and kept hitting the same wall: I'd ask Claude to produce a creative artifact (a song, a cover, a short video) and end up writing the API glue myself, then pasting results back into the chat. Felt backwards. So I built an MCP server around my AI generation platform. It exposes three tools to Claude: \- aw\_generate\_music (Suno, full songs with lyrics or instrumental) \- aw\_generate\_image (Z-Image Turbo, Wan 2.5 Spicy, Grok Imagine Quality, GPT-Image-2, Nano Banana 2, and others) \- aw\_generate\_video (Kling 3.0 Standard/Pro/4K T2V + I2V, Wan 2.2, Hailuo 02, Seedance, Grok video) One key. One credit pool. The agent picks the right model for the prompt. Install: npm install -g u/aetherwave-studio/mcp Claude Code config (\~/.config/claude/mcp.json or wherever yours lives): { "mcpServers": { "aetherwave": { "command": "npx", "args": \["-y", "@aetherwave-studio/mcp"\], "env": { "AW\_API\_KEY": "aw\_live\_YOUR\_KEY\_HERE" } } } } Restart Claude. Done. Prompts that work end-to-end without any additional setup: 1. "Generate a 60-second lo-fi track for a study playlist, then make me 3 album cover options in a retro Japanese print style." 2. "Take this product photo and generate a 5-second cinematic intro video for the product launch." (drop the image in chat first) 3. "Write the script for a 30-second ad about my SaaS, then generate the voiceover-friendly music bed and a matching motion-graphics opener." The agent decomposes, picks tools, runs them, hands you back the artifacts. Repo: [https://github.com/AetherWave-Studio/aetherwave-mcp](https://github.com/AetherWave-Studio/aetherwave-mcp) Dashboard + key: [https://aetherwavestudio.com/developers](https://aetherwavestudio.com/developers) Happy to answer questions about how I structured the tool schemas, what worked, what I'd do differently. v0.1.0, real users on it already, treating community feedback as the next steering signal.
View originalWhich AI image generator is actually worth the money?
I've looked at about a dozen different image generators: Nano Banana Flux Midjourney GPT Image 2 Firefly Ideogram Recraft Leonardo Canvas Meta AI They all have their pluses and minuses but they all do a decent job. If I'm looking to spend thousands over a year on an image generator, what would you suggest. This would be mainly for business and a little for art. submitted by /u/DogDetector42 [link] [comments]
View originalAI Doesn't Exist, and Poop Proves It
robot Maybe we should have called it accumulated intelligence. There is no artificial intelligence. Or at least, I don't think the word "artificial" is as clean as we pretend it is. I know this blog smells funny. Let me decompose it. What do we even mean when we say something is artificial? Usually we mean man-made. Something humans made. Something that would not exist without humans, but after humans, it exists because humans made it happen. That definition is useful. I understand why we use it. Even the original 1955 Dartmouth proposal, the document that helped name the field of "artificial intelligence," used the phrase in a practical way: a machine could be made to simulate parts of learning or intelligence. As a scientific label, the word has a job. So I am not really arguing with the dictionary. I know artificial can simply mean human-made. That is not the part I have a problem with. I am arguing with the feeling the word creates. But there is another meaning hiding inside it. Artificial starts to feel like separate. Fake. Unnatural. Something that does not really belong to this world. And that is where I think the word starts confusing us. Because humans are not outside nature. The brain is natural. It is part of this earth. Biology produces a thought. That thought becomes an action. That action becomes a tool, a house, a wheel, a computer, or a model that can answer questions in language. So where exactly does the artificial part begin? Human-made does not automatically mean unnatural If I take a seed and plant it, and then a plant grows, is that plant artificial? It happened because of human action. I moved the seed. I changed the situation. Maybe without me, that plant would not have grown there. But we still do not call the plant artificial. We understand that the plant is natural, even if human action helped it happen. Now take a wheel. A human thought about how to make travel easier. How to cover distance more efficiently. That thought became a shape. That shape became an object. That object changed how humans moved through the world. We call the wheel artificial because it was made by humans. But the human who imagined it was not artificial. The brain that produced the thought was not artificial. The need to move, carry, build, survive, and improve was not artificial. So again: where did the artificial part enter? Maybe we say "artificial" because it separates what existed before humans from what humans transformed. That is fine for communication. A tree and a wooden table are not the same thing. Designed things, synthetic things, industrial things, and harmful things can still be meaningfully different from a tree in a forest. But also, humans never really make anything from nothing. We transform what is already here. We take energy, matter, language, memory, need, and imagination, and we rearrange them. It is never fully made from nowhere. It is transformed. So I am not trying to erase all distinctions by calling everything natural. Natural does not mean harmless. Natural does not mean good. Natural does not mean morally excused. I am only saying that human-made things are not outside nature just because humans made them. Poop and thoughts are the same, in one simple way I know this is a strange example. Sometimes I have this itch to say the first thought that comes into my head. Unfortunately, this was the first thought. But maybe that is why it works. It is funny because it is too human. Also, it makes the point clearly. Why isn't poop artificial? Poop is a product of a human being. It comes from the body. It is produced by biology. We do not call it artificial, even though it is made by a human in the most literal way. A thought is also a product of a human being. It comes from the brain. It is produced by biology too. Poop and thoughts are the same in one simple way: both are products of a human. We treat one as biology. We treat the other as invention. But why? Why does one product of the human body feel natural, while another product of the human body becomes artificial the moment it turns into a tool? A thought does not stop being natural just because it becomes useful. A thought does not become unnatural just because it becomes a wheel, a house, a car, a computer, or a machine that can respond to language. It is still a product of the same earth. The same biology. The same human need to survive, organize, create, and understand. We don't call a beehive artificial Think about ants building a colony. They create a structure that is safer and more efficient for them. They organize themselves. They transform the environment around them. They make something that was not there before. But we do not look at an ant colony and say, "This is artificial." Same with bees making a hive. A beehive is built. It has structure. It has purpose. It stores food. It protects the colony. It is a product of collective behavior. But we call it natural
View originalJust passed the new Claude Certified Architect - Foundations (CCA-F) exam with a 985/1000!
The original post was removed by Reddit Filters, so I made new one with same content. I just got my results back today and managed to snag the Early Adopter badge as well. Following up on my recent DP-600 certification, I really wanted to validate my architecture skills specifically on the Anthropic side. The exam covers a lot of practical ground on prompt engineering for tool use, managing context windows efficiently, and handling Human-in-the-Loop workflows. Link to join: https://anthropic.skilljar.com/claude-certified-architect-foundations-access-request Training courses: https://anthropic.skilljar.com/ Cookbook: https://github.com/anthropics/anthropic-cookbook I've created my own Playbook and Mock Exam after the exam: https://drive.google.com/file/d/1luC0rnrET4tDYtS7xe5jUxMDZA-4qNf-/view?usp=sharing https://claude-certified-architect-mock-exam-cyberskill.vercel.app If anyone is preparing for this right now and has questions about the format or the types of architectural patterns tested, ask away! Happy to share some insights on what to study. Updated 26th May 2026: I noticed some mates treated me bananas (https://buymeacoffee.com/zintaen), didn't expect that, but you made my day. I'll use that fund to take more CERTs and create a site for mock tests (always free, of course). Thanks again.
View originalImage-generation Claude Code skill: how I structured the SKILL.MD to handle brand extraction before generation
Sharing a skill i wrote for my own workflow in case the structure is useful to anyone building their own. the problem i wanted solved: when i'm building a landing page, generating on-brand images means re-stating the brand context to the image model every single time. that context already exists in the codebase (tailwind config, CSS vars, font imports, copy tone). a skill felt like the right shape for "scan files, put together context, hand it to a generator." How the [SKILL.md](http://SKILL.md) is laid out: * **Detection phase,** explicit instructions to scan for missing/placeholder image refs first (lorem-picsum, empty src, broken paths, common placeholder hosts). No generation until detection completes, otherwise Claude gets eager and starts generating before knowing what's needed. * **Brand extraction phase**, reads \`tailwind.config.\*\`, root CSS, font imports, plus a sample of body copy. Outputs a structured brand brief (palette, typography, tone descriptors). Separating this from generation matters a lot, the brief gets reused across every image in the batch so they actually look like a set. * **Generation phase, two paths**, if the Gemini MCP (nano-banana) is configured, calls it directly with the brief plus per-image context. If not, outputs prompts to a markdown file you paste into Gemini yourself. The branching keeps it useful for people without MCP set up. The thing I'd flag if you're writing skills: be explicit about phase ordering in the [SKILL.md](http://SKILL.md) "First do X, only then do Y" reads as obvious but without it Claude will helpfully start generating before extracting brand context, and you get generic outputs. MIT, here if you want to read the actual README or fork it: [https://github.com/dancolta/gen-images-skill](https://github.com/dancolta/gen-images-skill)
View originalbest ai mcps after testing 10+ (for generating videos, code, design, and etc.). you’ve been using claude wrong this whole time.
been using claude with mcps for a few months. here's what actually stuck after testing 10+, split by what they're good for. **code**: github mcp (official). reading repos, opening prs, reviewing diffs without leaving claude. the search across issues is what hooked me — way faster than the github ui for "where did we discuss x". **docs**: notion mcp. searching across workspace + updating pages from claude beats the ui for repetitive stuff. weekly updates, meeting notes, status docs all flow through it now. **image/video**: higgsfield mcp. one connection gets you sora 2, veo 3.1, kling, seedance 1.5, soul id, nano banana. cinematic controls are the part i actually keep using — generating a 5-second shot with specific camera movement from inside claude saves the tab-switching loop. **design**: figma mcp. pulls tokens, component specs, frame contents straight into context. makes design-to-code prompts way more accurate because claude actually sees the spec instead of guessing from a screenshot. **browser**: playwright mcp. clicking around, scraping, filling forms. heavier than fetch but does the real work when you need actual interaction, not just html. **files**: anthropic's filesystem mcp. reading local files, organizing folders. boring but you use it constantly — basically the default mcp for any local workflow. what am i missing?
View originalTested 4 AI video generation MCPs in claude for making short clips
Hello everyone, recently I saw a lot of AI, especially GenAI, MCPs being launched. Out of the ones that I had an opportunity to test there were 4 I could consider worth trying out. **Higgsfield AI mcp.** the model coverage and claude comping up with ready scenarios is the main reason. one connection gets you sora 2, veo 3.1, kling, seedance 1.5 pro, nano banana, soul id. I've been able to get some gems using this. The problem is that if Claude doesn't understand you properly it can come up with something absolutely random or choose the most expensive models. **kubeez mcp.** also goes wide on models, similar pitch to the previous: image, video, music, tts in one place. i used it for batch work where i needed audio + visuals from the same chat. **runway mcp.** narrower scope, deeper on gen-4 specifically, which is why I don't really use it. the keyframe and reference image handling is solid in comparison, others tend to lose it. **elevenlabs mcp.** not video but i'm including it because every video workflow needs voiceover and this is the one that actually works end-to-end. claude writes the script, picks the voice, generates the audio. pairs well with any of the above. you will need it very frequently if you don't know/can't handle proper audio generation using higgsfield or runway. stack i settled on: higgsfield for the visuals, elevenlabs for better voiceover. what video mcps am i missing? happy to hear opinions
View originalI had Chat combine my banana bread and coffee cake recipe together…
It came out amazing. Moist, bread/cake texture, and super delicious! I’ve included the recipe at the end. I’m not a baker. Probably bake pastries like once every 6 months, so I’m not skilled enough to cross reference the recipe. Nonetheless, turned out awesome! submitted by /u/Eggrolling [link] [comments]
View originalSpent a few hundred generations testing gpt-image-2 vs Nano Banana for game sprites. gpt-image-2 isn't close.
and by '**gpt-image-2 isn't close**', I mean it's *far* better. Been running both models side by side for pixel art / game sprite generation. Some observations after a lot of A/B tests: **gpt-image-2 advantages I keep seeing:** **- Way better at small subjects. Nano** Banana wants to fill the frame with detail. gpt-image-2 actually understands "a tiny sprite in the center of the canvas, lots of negative space." **- Noticeably more game art in its training data**, judging from how it handles requests like "16-bit JRPG style" or "GBA-era pixel art." Nano Banana gives you something that looks like generic stylised illustration; gpt-image-2 gives you something a Square Enix artist might have drawn in 1996. **- Better grid layouts** when you ask for a 4x4 or 3x3 of related sprites. Nano Banana cheats and just gives you 3-4 variations of the same thing. **- "Low" tier ($0.006/call) outputs better game art than Nano Banana**'s default tier in my tests, which is wild given the price gap. Anyone else doing this kind of head-to-head for niche styles? Curious if the gap holds outside game art. (Side note: I built [spritelab.dev](http://spritelab.dev) around this if anyone wants to see the cleaned output.)
View originalSynthetic DMS Training Data Generation with Video Models
I like spending my free time testing new AI tools and seeing where they might fit into real computer vision workflows. This time I experimented with synthetic training data generation for Driver Monitoring Systems using Seedance 2.0. The inspiration came from Vision Banana: https://vision-banana.github.io/ The idea that really caught my attention is simple but powerful: many vision tasks can be represented as RGB outputs. A segmentation mask, an instance mask, a depth map, or another dense prediction target can all be treated as an image-like output. So I tried to apply this thinking to video. The workflow: Generate a realistic synthetic driver monitoring video Use the same video to generate a semantic segmentation mask Use the same video to generate an instance segmentation mask Combine the outputs into a dataset-like structure The mosaic video shows the result: RGB video + semantic mask + instance mask, aligned frame by frame. The scene is a fictional driver gradually becoming drowsy behind the wheel. This kind of scenario is useful for DMS development, but difficult to collect and annotate at scale with real-world data. Of course, generated annotations still need QA. They are not perfect ground truth. But for prototyping, rare-case simulation, and early dataset generation, this feels like a very promising direction. The interesting part is that the final output is not just a nice synthetic video. It can become structured training data: RGB frames from the generated video semantic classes from the semantic mask object regions and bounding boxes from the instance mask YOLO / COCO-style annotations after post-processing I wrote a more detailed blog post about the experiment here: https://www.antal.ai/blog/synthetic_dms_training_data.html submitted by /u/Gloomy_Recognition_4 [link] [comments]
View originalGoogle enterprise business trial, Just started and it's already stopped making images after 3?
So I just got the trial, wanted to finally test it out. I got the business enterprise trial and went to test out nano banana and after 3 images, it now seems to not be generating anything... Hasn't told me I have reached a limit or a time out. There's nothing. It's just the little blue symbol doing nothing. Is that it? That's what the trial offers? 3 images. I only did 3 images because the first image wasn't good enough lol. I imagine I would need to do 10 images to get the 1 image I wanted. So am I doing something wrong? Where do I check the quota? There's hardly any information on the business.gemini dashboard. Can't see quote, can't even see it says I'm on a trial although I know I went through the purchasing for it where it was 0 cost. How am I meant to give it a proper go if it limits me like this? submitted by /u/DeanMachineYT [link] [comments]
View originalI am paying 50$ who help start AI model journey?
I am paying 50$ who help start AI model journey? I have basic face pics around 8-10. Now i need video contents with the same character. Problemalistico, is that all the nano banana, and other staff can not copy the same face. And I want that same face. Any help i apprecite guys. My first work, amd i just try and try and nothing works. submitted by /u/bioshock73 [link] [comments]
View originalText-to-image is easy. Chaining LLMs to generate, critique, and iterate on images autonomously is a routing nightmare. AgentSwarms now supports Image generation playground and creative media workflows!
Hey everyone, If you’ve been building with AI agents, you know that orchestrating text is one thing, but stepping into multimodal workflows (Text + Image + Vision) is incredibly messy. If you want an agent to act as a "Prompt Engineer," pass that prompt to an "Image Generator," and then have a "Vision Agent" critique the output to force a re-roll—you are looking at hundreds of lines of Python boilerplate, messy API handshakes, and a terrible debugging experience when the loop breaks. I recently launched AgentSwarms, an in-browser sandbox for learning Agentic AI. Today, I am pushing a massive update: The Image Playground. What the feature actually does: Instead of fighting with code to test multimodal architectures, you can now drag, drop, and wire up text and image agents on a visual canvas to build creative workflows. Image Generation Nodes: Wire any text-output agent directly into an Image Node to autonomously generate visual assets. Vision AI Integration: Route generated images back into a Vision Node. You can instruct an agent to physically "look" at the generated image, evaluate it against your initial prompt, and trigger a loop to fix it if it hallucinated. Real-Time Data Flow: You can actually watch the payloads (the text prompts and the image outputs) flow across the node graph in real-time. submitted by /u/Outside-Risk-8912 [link] [comments]
View originalI built CanvasGPT – work with Claude on an open canvas
I've been building CanvasGPT for the past 2-3 years. It's a spatial workspace where you can brainstorm, research, and ship working products. **What it does:** Instead of linear chat, everything happens on an infinite canvas. You can work on multiple prototypes side-by-side, connect them together, and see how your research relates to what you're building. The hardest part was making the spatial reasoning work which is getting AI to understand that items placed near each other on the canvas are related. **Why I built it:** I got frustrated with ChatGPT conversations turning into endless scrolling. I'd lose context, couldn't see multiple ideas at once, and had no way to connect my research to what I was building. I wanted a workspace where everything I'm thinking about is visible and connected—like a whiteboard but with AI that can actually build things, not just chat about them! **Key features:** * **Spatial canvas** – Multiple projects visible at once, everything stays connected * **Asset generation** – Generate UI, images, videos, music, sound effects all in one place * **Multi-model support** –,GPT, Gemini, and even GLM, Kimi, Nano Banana, and GPT-Image-2 * **Connected systems** – Build apps that share data and automate workflows * **No monthly subscription** – Just pay for what you need Try it: [canvasgpt.com](https://canvasgpt.com) Happy to answer questions!
View originalPricing found: $1200 /mo, $20
Key features include: Observability, Business Analytics, Automation API, Enterprise, Banana Delivery (SF Only).
Banana is commonly used for: Real-time AI model inference for web applications, Scaling GPU resources for machine learning model training, Cost-effective deployment of deep learning models in production, Automated scaling of AI workloads based on demand, Rapid prototyping and testing of AI applications, Seamless integration of AI services into existing infrastructure.
Banana integrates with: AWS Lambda, Google Cloud Functions, Azure Functions, Kubernetes, Docker, TensorFlow, PyTorch, FastAPI, Flask, Streamlit.
Based on 46 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.
The Verge AI
Publication at The Verge
3 mentions